

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Как крупные технологические компании создают устойчивые системы для миллионов пользователей

Узнайте от специалистов компании DST Global, как ведущие технологические компании создают отказоустойчивые, масштабируемые системы с облачным отказоустойчивым решением, автоматическим масштабированием, микросервисами и возможностью наблюдения для обеспечения высокой доступности.
Когда вы обслуживаете миллионы пользователей, устойчивость не может быть чем-то, что вы добавляете позже. Она должна быть частью дизайна с самого начала. В противном случае, учитывая, как растут ожидания пользователей и как меняются глобальные модели трафика, ваша система просто не будет успевать.
Сегодня я хочу рассказать вам, как ведущие компании думают об устойчивости в масштабе. Мы рассмотрим стратегии, которые работают в реальном мире — а не только в теории — и посмотрим, как доступность, стоимость, наблюдаемость, масштабирование и проектирование системы объединяются.
Почему устойчивость так важна в масштабах
В том масштабе, о котором мы говорим, сбои — не редкость. Оборудование выйдет из строя. У сетей будут проблемы. Центры обработки данных выйдут из строя. Это нормально, а не исключительно.
Компании, которые усвоили это на собственном горьком опыте, теперь с самого начала разрабатывают проекты, рассчитанные на неудачи. Вот некоторые из основ:
- Разбиение системы на отдельные секции, чтобы один сбой не тянул за собой все остальное
- Резервное копирование не только серверов, но и баз данных, хранилищ и даже целых географических регионов
- Постоянное выполнение проверок работоспособности и настройка автоматического переключения на резервный ресурс для восстановления без необходимости вмешательства человека.
- Масштабирование системы в зависимости от потребностей в реальном времени
- Достаточно внимательное наблюдение за поведением системы, чтобы заметить ранние предупреждающие сигналы до того, как они приведут к серьезным сбоям
И это не то, что можно сделать и забыть. Команды постоянно улучшают историю устойчивости, основываясь на реальных инцидентах и извлеченных уроках.
Распространение систем по регионам: как это помогает
Один из самых умных шагов, которые вы можете сделать для обеспечения устойчивости, — это распределение ваших систем по разным регионам. Такие платформы, как AWS и GCP, созданы для этого; их регионы изолированы по замыслу.
Такая настройка означает, что даже если целый регион отключается, ваша система продолжает работать из других. Пользователи автоматически перенаправляются в здоровый регион, часто даже не замечая, что что-то пошло не так.
Обычно существует два способа репликации данных между регионами:
- Асинхронная репликация : быстрее, но есть небольшой риск потери нескольких последних обновлений, если авария произойдет в неподходящий момент.
- Синхронная репликация : безопаснее для критически важных данных, но вносит некоторую задержку
Большинство реальных архитектур в конечном итоге смешивают эти два подхода — в зависимости от того, какие части системы могут допустить небольшой риск, а какие нет.
Еще один важный трюк — региональная изоляция. Вы проектируете системы таким образом, что каждый регион может работать самостоятельно, если это абсолютно необходимо.
Однако не каждой системе нужна многорегиональная настройка. Многое можно сделать в одном регионе, используя несколько зон доступности. Но когда речь идет о действительно критически важных для миссии сервисах или очень строгих требованиях соответствия, многорегиональность становится необходимой.
Настройка правильных планов аварийного переключения
Каждая устойчивая система нуждается в надежной стратегии отказоустойчивости. Используются две основные модели в зависимости от потребностей:
Активно-активные настройки — это когда несколько узлов или регионов обрабатывают живой трафик одновременно. Если один из них выходит из строя, другие мгновенно подхватывают его. Это почти исключает простои, но требует очень тщательной синхронизации и балансировки.
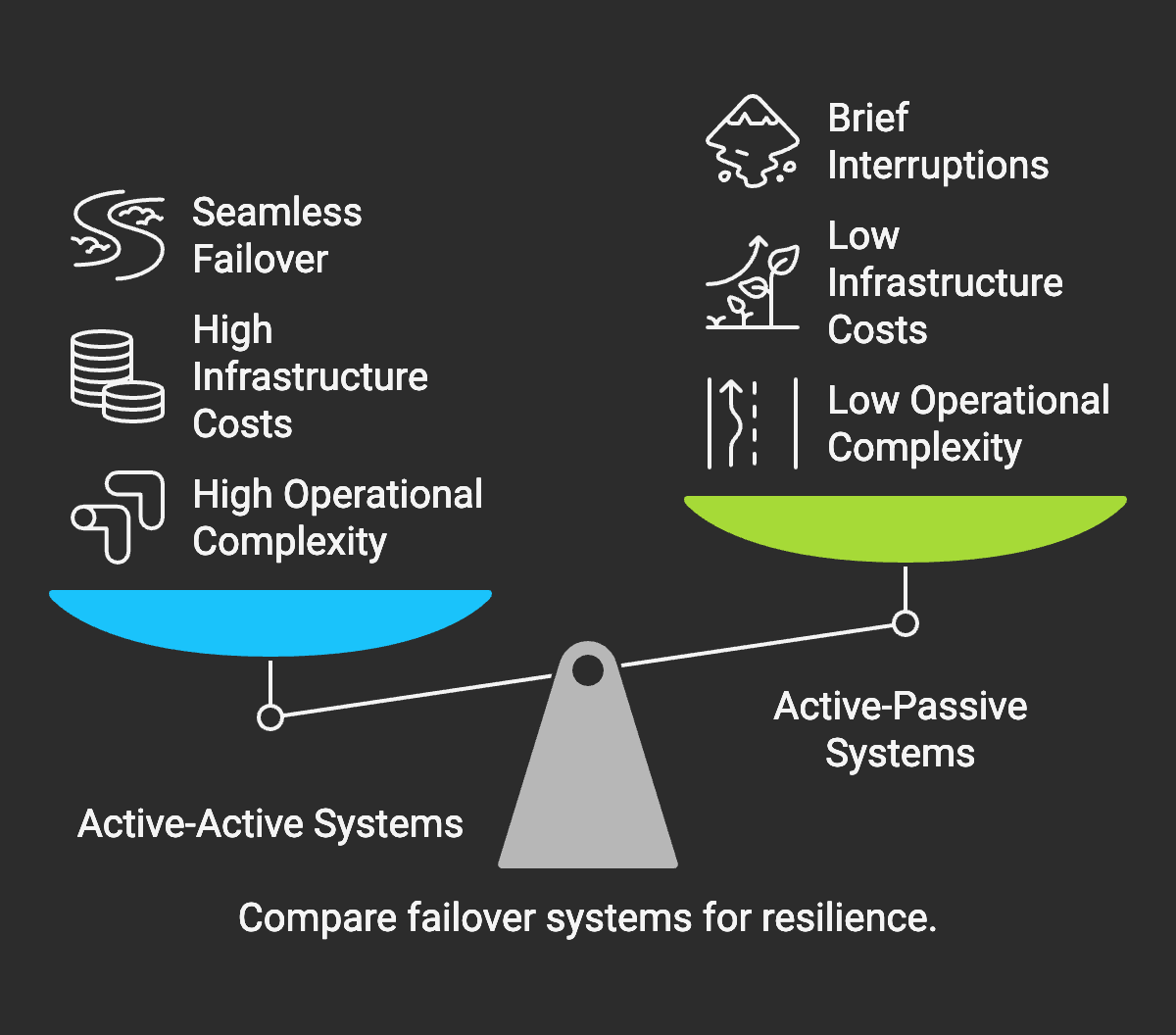
В активно-пассивных установках один работающий узел выполняет всю работу, а другой простаивает в ожидании отказа.

Независимо от того, какую модель вы выберете, регулярное тестирование отказоустойчивости является обязательным. Вы не хотите, чтобы первый реальный сбой стал первым моментом, когда вы обнаружите проблему с вашим планом. Тренировки и имитация сбоев — это то, как хорошие команды остаются готовыми.
Подготовка к всплескам трафика с помощью автоматического масштабирования
Если ваша система не может гибко реагировать на трафик, она сломается во время скачков. Вот почему автоматическое масштабирование является таким мощным инструментом.
Автоматическое масштабирование позволяет вашей системе автоматически добавлять или удалять ресурсы на основе данных об использовании в реальном времени, таких как загрузка ЦП, использование памяти или количество запросов.
Еще лучше то, что предиктивное автоматическое масштабирование может прогнозировать всплески спроса на основе исторических закономерностей — например, масштабирование непосредственно перед началом распродаж в Черную пятницу.
Масштабирование должно происходить по всему стеку: веб-серверы, базы данных, кэши, очереди сообщений, все. Слабое звено в любом месте может создать узкое место.
Но есть один важный момент: политики масштабирования должны быть хорошо продуманы. В противном случае вы можете в конечном итоге потратить ресурсы впустую и увеличить расходы. Умное масштабирование требует умных порогов, периодов охлаждения и ограничителей расходов.
Микросервисы: устранение сбоев путем разбиения компонентов на части
Микросервисы стали популярной архитектурой для создания устойчивых крупномасштабных систем. Основная идея заключается в разделении большой системы на множество меньших, специализированных сервисов, которые общаются друг с другом через API.
Такой подход дает ряд серьезных преимуществ:
- Если одна служба выходит из строя, ущерб ограничивается и не приводит к остановке всей системы.
- Каждая услуга может масштабироваться независимо в зависимости от собственных потребностей.
- Команды могут обновлять службы, не затрагивая несвязанные части системы.
- Услуги могут использовать наилучшие технологии, соответствующие их индивидуальным потребностям.
Конечно, микросервисы не бесплатны. Они вносят сложность. Теперь вам придется управлять такими вещами, как обнаружение сервисов, распределенная трассировка, централизованное ведение журналов и более сложные конвейеры развертывания.
Тем не менее, компромисс часто окупается, когда вы стремитесь к устойчивости и быстрой итерации в очень больших масштабах.
Наблюдаемость: как узнать, здорова ли ваша система
В больших масштабах нельзя летать вслепую. Наблюдаемость — это то, как вы опережаете проблемы.
Вам необходимо охватить три столпа:
- Метрики предоставляют вам цифры по таким показателям, как частота ошибок, задержка, пропускная способность и использование ресурсов.
- Журналы регистрируют события в вашей системе, чтобы вы могли расследовать случаи, когда что-то идет не так.
- Распределенная трассировка позволяет отслеживать один запрос по нескольким службам, чтобы находить узкие места или точки отказа.
Помимо этих основ, хорошая наблюдаемость также включает в себя панели мониторинга, оповещения, синтетические тесты и проактивный мониторинг состояния.
Обычно используются такие платформы, как AWS CloudWatch, X-Ray и инструменты с открытым исходным кодом, как Prometheus и Jaeger. Но настоящий ключ — это не инструмент, а обеспечение того, чтобы система была создана с самого начала так, чтобы ее было легко наблюдать и устранять неполадки.
Хорошая наблюдаемость сокращает продолжительность инцидентов, упрощает поиск первопричин и помогает командам выявлять и устранять риски до того, как они навредят пользователям.
Управление компромиссами: стоимость, скорость и устойчивость
Создание устойчивых систем всегда требует компромиссов.
- Строгая согласованность обеспечивает более безопасные данные, но может замедлить работу системы.
- Архитектуры высокой доступности требуют больше затрат на инфраструктуру, но позволяют сэкономить гораздо больше средств из-за простоев.
- Сложные конструкции могут обеспечить большую устойчивость, но могут затруднить эксплуатацию
Умные команды не пытаются иметь все. Они делают осознанный выбор на основе данных: имитируют сбои, моделируют влияние простоя на бизнес и проводят тесты на хаос, чтобы найти реальные слабые места.
Иногда имеет смысл принять конечную согласованность ради лучшей скорости. Иногда приходится вкладывать большие средства, потому что даже минута простоя обходится слишком дорого.
Универсального ответа не существует. Правильный выбор по мнению разработчиков DST Global, зависит от ваших пользователей, вашего бизнеса и того, какой сбой вы абсолютно не можете себе позволить.
Формирование устойчивости как постоянной привычки
Если есть что-то, что отличает великие системы, так это то, что их создатели рассматривают устойчивость как живой процесс, а не как разовый проект.
Лучшие компании делают устойчивость частью всего, что они делают:
- Устойчивость рассматривается во время обсуждения архитектуры, а не добавляется позже
- После каждого инцидента команды проводят безупречные проверки, направленные на обучение и совершенствование.
- Изменения внедряются осторожно, часто с флагами функций или с помощью канареечных развертываний.
- Хаос-инжиниринг используется проактивно для проверки того, как системы ведут себя в условиях стресса.
Сделав устойчивость частью повседневной культуры, эти организации в конечном итоге создают системы, которые не просто переживают плохие дни — они на самом деле становятся лучше благодаря им.
Создание надежных систем в глобальном масштабе — это тяжелая работа. Она требует тщательного планирования, продуманных компромиссов, постоянной бдительности и стремления учиться на каждой неудаче.
Но если все сделано правильно, вы сможете обеспечить отличный пользовательский опыт, даже если произойдет что-то непредвиденное, — и именно это отличает хорошие системы от по-настоящему великих.
Как крупные технологические компании создают устойчивые системы для миллионов пользователей
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Программное обеспечение продолжает усложняться, теряя связь с бизнес-целями. Проектирование, ориентированное на предметную область, обеспечивает ясность, делая системы масштабируемыми, осмысленными и ...
Контейнеризация — это технология, которая произвела революцию в разработке...
В этой статье разработчиками компании DST Global р...
В этой статье разработчиками компании DST Global, ...
Чтобы эффективно планировать (или даже разумно обс...
Введение в архитектуру веб-приложенийАрхитектура в...
Узнайте от разработчиков DST Global, что такое арх...
Структура сайта с точки зрения роботов поисковых с...
Этот текст не объясняет, что такое микросервисы и ...
Понятие прототипа в проектирование и веб-диза...
Что входит в проектирование сайта в ДСТ?Определени...
В мире, где количество пользователей исчисляется миллионами, надёжность должна быть заложена в основу разработки с самого начала. Если добавить её позже, система не сможет соответствовать растущим ожиданиям пользователей и адаптироваться к меняющимся глобальным тенденциям.
Какие подходы действительно работают в реальных условиях? Как доступность, стоимость, мониторинг, масштабирование и проектирование системы объединяются для создания эффективных решений?
— Анализ требований. Определяются основные характеристики системы, её функциональные и нефункциональные требования, оцениваются потенциальные риски и угрозы.
— Проектирование. Разрабатывается архитектура системы с учётом выявленных требований и рисков.
— Реализация. Система создаётся на основе разработанных проектных решений: пишется код, интегрируются компоненты, проводится тестирование и отладка.
— Тестирование и верификация. Проводится тестирование системы на надёжность и устойчивость, симуляция различных сценариев отказов.
— Внедрение и мониторинг. Система внедряется в рабочую среду, устанавливаются механизмы мониторинга, которые позволяют отслеживать её состояние и быстро реагировать на возможные сбои.
Примеры успешных проектов
— Экосистема Microsoft. Компания интегрировала продукты и сервисы для обеспечения пользователям удобства в разных сферах жизни и бизнеса. Например, офисные приложения с облачными сервисами и возможностями совместной работы позволяют работать с локальными и облачными данными, синхронизируя их между устройствами.
— Цифровая экосистема Amazon. Единая облачная платформа (AWS) служит основой для более 40 сервисов компании, включая Amazon Prime Videos, Prime Music и Studio. Интеграция между сервисами позволяет управлять пользовательским поведением, добиваться максимальной скорости и прозрачности процессов.
Проблемы и вызовы
— Недовольство пользователей. Клиенты могут выражать недовольство, если дополнительные услуги предлагают без возможности выбора.
— «Тяжёловесность» приложений. Из-за многочисленных дополнительных функций приложения могут становиться слишком объёмными и занимать много места в телефоне.
— Сложности с интеграцией новых участников. Например, в некоторых случаях функциональная цифровая экосистема бывает закрытой, что порождает сложности с интеграцией новых сервисов.
Цифровые экосистемы достигают успеха благодаря своей уникальной модели взаимодействия с пользователями и постоянному расширению функционала. Гибкость и инновации позволяют им адаптироваться к меняющимся рынкам. А их способность предугадывать и удовлетворять потребности аудитории делает эти экосистемы лидерами в своих областях.
Для пользователей обычно эти изменения кажутся странными: как банк или торговая сеть могут называть себя одинаково — цифровой экосистемой? И действительно, фактически границы, которые были между компаниями из разных отраслей, начинают стираться. Хотя так происходит не только в России — поясняют эксперты.
Что такое цифровая экосистема?
На самом деле термин далеко не новый и устоялся уже давно. Прежде всего он закрепился за Apple, Microsoft, Google, Facebook*, Tesla, Amazon и другими всемирно известными технологичными компаниями. Для каждой из них цифровая экосистема — это текущий этап развития.
Цифровая экосистема — это цифровое пространство, в котором бесшовно функционирует множество сервисов одной компании или нескольких участников-партнёров. Интеграция между ними позволяет управлять пользовательским поведением, добиваться максимальной скорости и прозрачности процессов, обнаруживать проблемы и точки улучшения в разных бизнес-направлениях деятельности.
Классический пример цифровой экосистемы компании Amazon — Amazon Web Services (AWS). Чтобы выстроить бизнес по всему миру, гиганту потребовалось много лет.
AWS — единая облачная платформа, на которой базируются все сервисы компании. Именно там впервые были запущены Amazon Prime Videos, Prime Music, Studio. Сегодня в единую экосистему входит более 40 сервисов Amazon. Пользователи по всему миру быстро и без лишних действий получают доступ к товарам, любимым фильмам, музыке и другим услугам. Максимальное удовлетворение потребностей клиента — вот что двигало Amazon при создании собственной цифровой экосистемы.
Топ-5 факторов цифровой экосистемы
Одного объединения сервисов на одной платформе, чтобы назвать это модным термином, недостаточно. Эксперты выделяют минимум пять характеристик цифровой экосистемы, которым она должна соответствовать.
Ориентир на пользователя
На старте создания любой цифровой экосистемы стоит необходимость повысить ценность компании и её продуктов в глазах клиента. Именно поэтому он получает огромное количество услуг, информации, выгод и возможностей одновременно. Инструментами достижения такой ценности становятся сервисы, интегрированные друг с другом. При этом их связь работает как вовне — их может видеть и применять пользователь, так и изнутри компании — в этом случае объединённые приложения позволяют выстраивать максимально удобную, слаженную и быструю работу сотрудников с клиентскими запросами и ожиданиями. Во втором случае речь может идти о системах управления документами и процессами, финансовыми операциями и т. д., например, экосистема цифровых решений Directum.
Информация — важный ресурс
Данные — новая нефть. С этим точно не будут спорить все, кто создал успешную цифровую экосистему. Задача объединенных сервисов часто сводится к сбору необходимой информации о клиентах, её аналитике и прогнозированию. Всё это позволяет влиять на пользовательское поведение, наращивать объёмы продаж и повышать лояльность аудитории к бренду.
Оптимизация и автоматизация во всём
Цифровая экосистема — это всегда сложная инфраструктура, которая требует постоянного внимания. Настройка грамотной архитектуры и интеграции, избавление от лишних операций, этапов и элементов — всё это помогает компании улучшать показатели скорости работы и удовлетворения потребителя.
Глобальный масштаб
Уже в момент создания цифровая экосистема строится как платформа, которая предполагает масштабирование бизнеса. Чем выше потенциал развития компании, тем меньше должно быть инфраструктурных и организационных ограничений у применяемого ПО.
Как правило, подразумевают масштабы мира. Реже возможности цифровой экосистемы могут расчитываться на несколько стран.
Динамика как постоянный фактор
Цифровые экосистемы меняются так, как того требует рынок. Они адаптируются под новые требования клиента. Ожидаемой функциональности часто бывает недостаточно. Для устойчивого развития бизнеса сервисы должны предвосхищать ожидания пользователей.
Какие виды обычно выделяют
Цифровые экосистемы принято разделять на три типа: функциональная, экосистема платформы и экосистема суперплатформы. Классификация строится на данных о количестве компаний, которые размещают сервисы в едином пространстве, а также на возможностях масштабирования.
Функциональная цифровая экосистема – самый простой тип. Обычно выстраивается вокруг одной компании или её продукта. При этом количество партнеров (или дочерних компаний), которые размещают свои сервисы в рамках экосистемы, обычно не превышает сотни. Разрабатывается и используется чаще всего. Как правило, функциональная цифровая экосистема бывает закрытой, что порождает сложности с интеграцией новых участников платформы.
Экосистема платформы — более продвинутый вариант. Здесь количество участников со своими сервисами может исчисляться миллионами. Упор при разработке и использовании экосистем платформы делается на работу с данными о клиентах, которые потом могут применяться для повышения продаж и предложения новых услуг.
Экосистема суперплатформы — самый сложный и редкий вид. Включает в себя возможность одновременного подключения практически неограниченного количества партнеров-участников и пользователей. Интеграция здесь может настраиваться не только на уровне сервисов, но и выше — между платформами. Экосистемы суперплатформы — удел крупнейших технологических гигантов, таких как Apple и Amazon.