
Munin — простая система мониторинга, которой может оказаться вполне достаточно для перечисленного.
munin-node — устанавливается на сервер (узел).
Munin — простая система мониторинга, которой может оказаться вполне достаточно для перечисленного.
munin-node — устанавливается на сервер (узел).
Zabbix, описана процедура установки пошагово, мониторится куча всего из коробки.
Скорее всего криво настроенный MySQL. После какого то количества больших запросов база данных сьедает всю память. Покажите конфиг my.cnf
В дополнение к совету включить и проанализировать slow query log (который и ответит на вопрос "«какой запрос именно создает такую нагрузку ), советую посмотреть на конфигурацию mysql.
Если я правильно вижу, у вас бежит несколько процессов mysql — пришлите пож-ста вывод „ps -ef | grep mysql“ чтобы точно проверить. Я бы использовал один процесс и дал ему больше памяти — это помогает mysql работать эффективнее.
Вопрос немного непонятно. Если вопрос состоит 7/24/365 работы хостинга, тогда уж иди на цод тиер3.
А если прерывать на пару часов, максимум пол дня и некто не обидеться, тогда достаточно VDS+свой сервер.(На vds ставишь реверспрокси, впн, а сервера подключаешь к vds через впн).
Но можно масштабировать. Vds+сервер дома, сервер на работе, сервер у друга и т.д. собрать кластер для отказоустойчивости. У меня сервера простые, по 5000 руб себестоимости( всякие i3 3220, xeon 775сокета) главное качественно запитать и усе. Работает годами. Все на proxmox.
Возможно, только это делают те у кого реальный доход и простой сервера, стоит дороже, чем все затраты на обслуживание всего этого. Тебе можно не заморачиваться подобным.
Для надёжности вам нужно 3 сервера:
1 — ваш VPS
2 — ваш офисный сервер
3 — Load balancer, который будет настроен таким образом, чтобы направлять трафик на сервер 1, но если он лёг, то направлять его на сервер 2.
Чтобы не покупать отдельный сервер под Load balancer, можете посмотреть в сторону специальных сервисов. Например Cloudflare: developers.cloudflare.com/load-balancing/
Откройте файл /ваш_сайт/templates/default/admin.tpl.php там Вы найдете где формируется меню для панели управления DST Platform, по аналогии с другими пунктами добавьте нужные Вам пункты меню и все готово. Пример кода пункта меню:
<li> </p> <p> <a href="Тут ссылка"> </p> <p> <svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><polyline points="23 4 23 10 17 10"/><polyline points="1 20 1 14 7 14"/><path d="M3.51 9a9 9 0 0 1 14.85-3.36L23 10M1 14l4.64 4.36A9 9 0 0 0 20.49 15"/></svg> </p> <p> <span>Тут название пункта</span> </p> <p> </a> </p> <p> </li>
Используйте IMAP. Пришедшая почта будет попадать ко всем пользователям ящика. При отправке письма так же хранятся на сервере, а значит должны оказываться в Отправленных у всех пользователей ящика.
Есть 2 сторонних почтовых сервера с маленьким объемом (~25 ящиков по 1ГБ). Каждым ящиком пользуется несколько человек. Есть свой сервер с достаточным объемом памяти.
Расширить объем ящиков возможности нет, поэтому надо организовать локальное хранение почты. Использовать свой почтовый сервер вместо этих сторонних тоже нет возможности.
Рассматривал варианты:
1) Почтовый клиент (Thunderbird) у каждого пользователя с протоколом POP3. Из минусов почта хранится локально на компьютерах, делать бэкапы не совсем удобно, отправленные письма хранятся только на компьютере, откуда они отправлялись. В Thunderbird можно указать папку для хранения почты, можно было бы выбрать в качестве этой папки папку на сервере, но не будет ли тогда конфликтов при одновременной работе нескольких пользователей в одном ящике?
2) Веб-клиент (Roundcube) на сервере. Вся почта хранится на нем, следовательно удобнее делать бэкапы и отправленные письма хранятся тоже только на сервере, а не на куче отдельных ПК. Из минусов не поддерживает POP3 без плагина и на каждый ящик нужен отдельный пользователь. Есть плагин для использования нескольких ящиков одновременно, но там я так понял только IMAP, можно ли его подружить с плагином для POP3?Также нужно вывести в панель управления DST Platform ссылку для модераторов и администраторов сайта, чтоб им было проще заходить в почту.
Может сможете подсказать как правильнее и удобнее решить этот вопрос?
Строй Дом
1. В Thunderbird можно указать папку для хранения почты, можно было бы выбрать в качестве этой папки папку на сервере, но не будет ли тогда конфликтов при одновременной работе нескольких пользователей в одном ящике?
Этот вариант с небольшой модификацией. Не должны несколько пользователей работать в одном ящике. На уровне Thunderbird ящик у каждого свой (отдельные папки на сервере), но на уровне учётной записи для POP3 они могут совпадать. В настройках Thunderbird убрать удаление с сервера при получении и установить удаление через несколько дней — это позволит нескольким пользователям забирать через POP3 в разное время. Минус этого варианта в повышенном расходе места на диске.
2. Откройте файл /ваш_сайт/templates/default/admin.tpl.php там Вы найдете где формируется меню для панели управления DST Platform, по аналогии с другими пунктами добавьте нужный Вам пункт меню и все готово.
Да кстати и еще в конфиге нужно удалить строчку client-to-client, всё просто. Затем перечитать настройки или перезапустить
Через iptables надо не маршруты задавать, а запрещать трафик на соответствующий диапазон адресов.
sudo iptables -I FORWARD -s 10.8.0.230! -d 10.8.0.1 -j DROP
Пример правила, который у меня работает.
Опция client-to-client обеспечивается внутренним роутингом овпн сервера, до обработки iptables и маршрутизацией ядром этот трафик не доходит
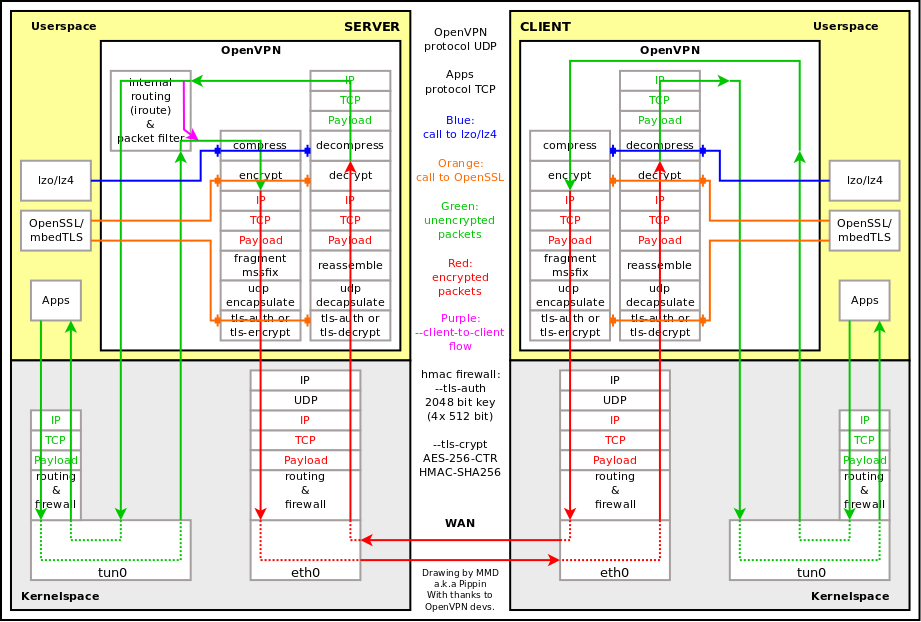
Таким образом, надо отключить опцию client-to-client, обеспечить форвандинг трафика между клиентами через ядро (routing and firewal после tun0 на схеме т.е.), и уже тогда можно будет ограничить трафик отдельного клиента через iptables
