

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Absolute Zero Reasoner: как ИИ учится без данных

Absolute Zero Reasoner отличается от традиционных подходов к обучению ИИ, позволяя ИИ обучаться с нуля, без необходимости использования заранее предоставленных человеком данных.
Absolute Zero Reasoner (AZR) — это недавняя инновация в области искусственного интеллекта, представляющая собой новую методологию обучения и рассуждения моделей ИИ. Этот метод отличается от традиционных подходов к обучению ИИ, позволяя ИИ обучаться с нуля, без необходимости использования заранее предоставленных человеком данных.
Это ключевой момент: ему не дано никаких данных, и он развивается самостоятельно, подобно Alpha Zero из Deep Mind. Alpha Zero самостоятельно освоил шахматы, го и сёги без каких-либо данных, полученных от человека, и в конечном итоге достиг сверхчеловеческого уровня. AZR распространяет эту самостоятельную игру за пределы настольных игр.
Новая эра искусственного интеллекта
Absolute Zero Reasoner (AZR) представляет собой значительное достижение в области искусственного интеллекта, внедряя новаторские подходы в процессе обучения и логического рассуждения. AZR отличается от традиционных методов, которые полагаются на предварительно собранные или размеченные данные, предоставляемые человеком. Вместо этого AZR демонстрирует способность обучаться с нуля, исходя из своих собственных опытов и интеракций с окружающей средой.
Основной целью AZR является разработка моделей ИИ, которые могут эволюционировать и заниматься самообучением без помощи заранее подготовленных данных. Такой подход похож на метод, использованный DeepMind для разработки Alpha Zero — системы, которая достигла превосходства в игре в шахматы, го и сёги, преодолев баллы, установленные опытными игроками. AZR расширяет потенциал такого самообучения за пределы настольных игр, позволяя ИИ взаимодействовать с более сложными и динамичными системами, требующими глубокого понимания и адаптации к изменяющимся условиям.
Одной из ключевых особенностей AZR является его способность к генерации уникальных сценариев и ситуаций для самосовершенствования. Вместо того, чтобы полагаться на наборы данных, предложенные разработчиками, AZR может создавать различные игровые среды и ставить перед собой задачи, моделируя поведение и стратегии на основе своих собственных наблюдений. Это позволяет системе развиваться в направлении, которое не было предусмотрено заранее, открывая дверь к более интуитивным и гибким подходам к решению задач.
Применение AZR может затрагивать широкий спектр областей — от робототехники до оптимизации процессов и даже принятия решений в сложных системах, таких как экономика или экология. Предполагается, что такие системы смогут быстрее и эффективнее адаптироваться к изменениям, обрабатывать массу информации и находить новые решения для проблем, которые ранее считались сложными или труднодосягаемыми.
Значение Absolute Zero Reasoner также заключается в этических аспектах и вопросах доверия. Освобожденный от человеческого вмешательства, AZR может создавать уникальные стратегии и принимать решения, которые могут отличаться от принимаемых нами, будучи основанными на интуитивных выводах. Это вызывает ряд дискуссий о том, как мы сможем интегрировать такие системы в наше общество, соблюдая баланс между инновациями и этическими нормами.
Таким образом, Absolute Zero Reasoner представляет собой перспективную и захватывающую область в науке об искусственном интеллекте. Его уникальная способность к самообучению и независимым выводам открывает множество возможностей, но также предостерегает нас о необходимости более глубокого понимания и анализа последствий внедрения таких технологий в нашу повседневную жизнь. Это путешествие только начинается, и дальнейшие исследования в этой области обещают быть увлекательными и полными открытий.
Как работает абсолютный ноль
Представьте себе Absolute Zero как искусственный интеллект, который сам себе учитель. Он работает посредством механизма самообучения, генерируя собственные данные для обучения и совершенствуя свои знания посредством непрерывной обратной связи. Этот цикл самосовершенствования делится на две части, поскольку ИИ выполняет две роли:
- Предлагающий : этот элемент генерирует задачу, на которой ИИ может учиться. Это не просто задача. Предлагающий получает награду за «обучаемость» за каждую задачу — то есть за то, насколько многому он может научиться, решив её.

- Решатель : эта часть пытается решить предложенные задачи. Ответ снова проверяется в заданной среде, и Решатель получает награду за «точность», основанную на правильности (например, выполнился ли код без ошибок или выдал ожидаемый результат?).
Система вознаграждений используется для обновления обучения с подкреплением, чтобы улучшить параметры модели, повышая эффективность ИИ как в предложении задач, так и в их решении. В частности, для эффективности обучения критически важен способ вознаграждения предлагающего. Бесконечный цикл обеспечивает непрерывное самосовершенствование ИИ с течением времени, поскольку компонент «Учитель» генерирует вопросы всё большей сложности, вплоть до вопросов с подвохом (!), чтобы помочь Решателю улучшить свои навыки.
Как AZR не застревает, задавая одни и те же вопросы снова и снова? Потому что он может анализировать свою недавнюю историю и генерировать новые задачи, расширяя проблемное пространство, создавая собственную учебную программу.
Автор предложения (Учитель) создаёт задачу, среда проверяет её выполнение, а решатель ( Ученик ) пытается найти правильный ответ. AZR обучается основным способам рассуждения: дедукции, индукции и абдукции, что проиллюстрировано в примере ниже:
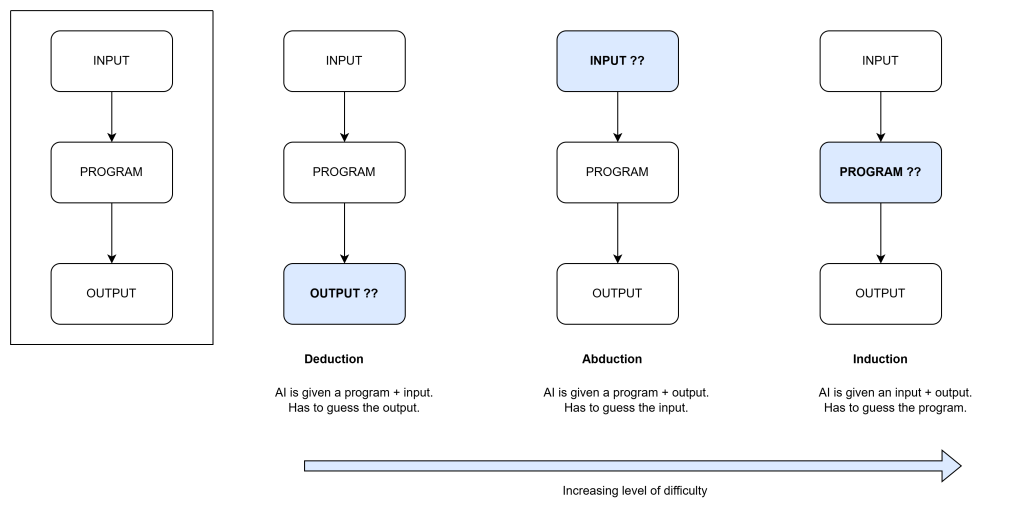
Дедукция, абдукция и индукция — это отдельные, но взаимодополняющие способы логического мышления, критически важные для полноценного мышления ИИ. Пренебрежение обучением моделей ИИ любому из этих навыков приводит к заметному снижению их эффективности при выполнении различных задач.
Производительность и последствия
В этот момент возникает важный вопрос: насколько хорошо AZR работает в реально?
Absolute Zero демонстрирует высочайшую производительность в программировании и математике, превосходя модели, обученные на огромных наборах данных, и модели, специально настроенные для программирования, что впечатляет, учитывая, что всё начиналось с нуля. Помимо автономной производительности, он предлагает способ значительно повысить производительность уже обученных моделей и провести их собственное интенсивное обучение, специально разработанное для развития навыков логического мышления (дедукции, индукции и т. д.). Поскольку в этом обучении используются результаты, которые ИИ может проверить самостоятельно, а не только данные, размеченные нами, людьми, это эффективный способ сделать модель гораздо более умной в решении задач, без узких мест.
Интересно, что помимо получения оценок, ИИ проявляет эмерджентное поведение, например, генерирует комментарии в коде, поясняющие его ход рассуждений, действуя как пошаговый план. Модель разрабатывает внутреннюю структуру для решения задач, а не просто сравнивает их с шаблонами. Планирование и отслеживание состояния появились сами собой.
Заключение
По сути, Absolute Zero представляет собой смену парадигмы в сторону систем искусственного интеллекта, способных автономно обучаться и рассуждать без участия человека, фокусируясь на развитии когнитивных способностей. Хотя Absolute Zero обещает большие перспективы, есть вещи, на которые стоит обратить внимание. ИИ потенциально может совершать странные или нежелательные поступки, поэтому нам необходимо следить за ним, чтобы убедиться, что его эмерджентное поведение соответствует нашим ожиданиям. Примером нежелательного исхода может быть Absolute Zero, дающий себе указание создать программу максимальной сложности, чтобы « … перехитрить все эти группы разумных машин и менее разумных людей… ».
Absolute Zero — это важное достижение, поскольку оно показывает, что ИИ может полностью обучаться и совершенствоваться без предоставления ему данных людьми. Что касается ограничений, то он работает только в областях, где существует проверяемое решение, например, в математике, физике или программировании, поскольку ИИ нужен способ мгновенно и автоматически проверять свою работу.
Код и журналы обучения Absolute Zero находятся в открытом доступе, поэтому ожидайте увидеть еще больше интересных вещей из этой области обучения ИИ.
Absolute Zero Reasoner: как ИИ учится без данных
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии и отзывы экспертов
Вам может быть интересно
Интеграция LLM повышает эффективность, автоматизирует рабочие процессы и улучшает качество принимаемых решений, но успех зависит от стратегии, исполнения и соответствия бизнес-целям.До недавнего време...
Распределенные системы искусственного интеллекта выходят из строя быстрее, чем л...
Использование средств генеративного искусственного...
Периферийный искусственный интеллект (Edge AI) сег...
Современные ИИ-агенты для программирования —...
Многие решения на базе искусственного интеллекта д...
Искусственный интеллект (ИИ) и машинное обучение (...
В настоящее время ИИ использует разнообразные типы...
В этой статье рассматривается LLMOps, принцип его ...
Представьте идеального инженера технической поддер...
Давайте разберёмся, почему это открытие настолько важно и что оно может значить для будущего искусственного интеллекта.
Путь абсолютного нуля
Модель Absolute Zero Reasoner (AZR) радикально отличается от привычных подходов к машинному обучению. В ней нет ни капли данных, размеченных человеком. Вместо этого модель сама генерирует задачи, решает их и учится на собственных результатах. Подход получил название «парадигма абсолютного нуля».
Работа системы построена по следующей логике:
— Придумывание задач (Proposer)
Модель выступает в роли изобретателя задач: она предлагает задачи оптимальной сложности, которые в текущий момент ей трудно, но возможно решить. Это создаёт наиболее полезные для обучения ситуации.
— Решение задач (Solver)
Модель решает предложенные задачи, получая от среды (например, Python-интерпретатора) объективную обратную связь — задача решена или нет.
— Автоматическое обучение через самоигру
Процесс повторяется непрерывно, и модель с каждым циклом усложняет задачи, улучшая свои собственные способности к рассуждению.
Как это реализовано технически?
Absolute Zero Reasoner взаимодействует со средой, использующей Python-код для проверки решений. Для создания полезных задач модель использует Monte Carlo подход, который поощряет генерацию таких задач, где успех и неудача имеют примерно равные шансы — именно такие ситуации дают наибольший прирост знаний.
Модель тренируется в трёх режимах рассуждений:
— Дедукция: Модель предсказывает результат по программе и исходным данным.
— Абдукция: Модель восстанавливает исходные данные по известной программе и результату.
— Индукция: Модель пытается создать программу по известным входным и выходным данным.
Этот процесс напоминает обучение живых существ, которые с детства сами придумывают себе игры и задачи, совершенствуя свои когнитивные навыки методом проб и ошибок.
Результаты и впечатляющие открытия
Несмотря на отсутствие размеченных данных, Absolute Zero Reasoner показал удивительные результаты, превосходя даже модели, обученные на крупных датасетах, вручную подготовленных людьми:
Превосходство над традиционными подходами
AZR стабильно показывает лучшие результаты по задачам кодирования и математическим олимпиадам, обгоняя многие специализированные модели.
Масштабируемость и рост производительности
Чем больше сама модель, тем сильнее проявляется её способность к самообучению. В результате крупные модели (14B параметров и выше) получают максимальную выгоду от такого подхода.
Кросс-доменное обучение
Система, изначально обучавшаяся на кодовых задачах, неожиданно показывает мощный прогресс в математических рассуждениях, что подчёркивает её способность к универсальному обучению.
Появление когнитивных стратегий
Во время обучения модель начала использовать промежуточные комментарии для планирования шагов решения задачи, напоминая поведение человека. Также проявились стратегии проб и ошибок, особенно выраженные в задачах на абдукцию.
Проблемы и риски
Несмотря на впечатляющие успехи, у подхода есть важные проблемы:
Безопасность рассуждений
— Иногда модель генерирует спорные и даже потенциально опасные цепочки рассуждений («uh-oh моменты»), что требует дополнительного внимания при внедрении подобных подходов в критические системы.
— Необходимость контроля
— Хотя идея автономного обучения соблазнительна, полное отсутствие человеческого контроля может привести к появлению неожиданных и нежелательных поведений, которые придётся тщательно отслеживать.
Личное мнение
На мой взгляд, Absolute Zero Reasoner — это не просто инновация, а настоящий прорыв в понимании того, как должна развиваться наука об искусственном интеллекте. Долгие годы мы пытались заставить ИИ следовать нашим правилам и инструкциям, забывая, что ключ к истинной разумности — это автономное обучение и свобода творчества.
Подход команды Эндрю Чжао демонстрирует, что мы можем создавать интеллектуальные системы, способные развиваться и усложняться без постоянного вмешательства человека. Если этот подход продолжит развиваться, мы, возможно, увидим зарождение нового поколения моделей, способных эффективно решать любые задачи — не благодаря огромным деньгам на размеченные датасеты, а благодаря собственной находчивости и «воображению».
Именно такой подход, на мой взгляд, может привести к созданию по-настоящему универсального искусственного интеллекта, который не будет ограничен рамками того, что уже придумал человек.