

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Гибкость в хранении информации и масштабировании в Kafka

Сложно спорить с тем, что одно из важных преимуществ Kafka -- это возможность долговременного хранения информации. Мало того, используя настройки, вы можете как указать определенное время хранения топиков, так и ограничить размер топика в байтах -- в случае превышения сообщения станут недействительны и будут удалены. Разве не удобно, что сообщения хранятся лишь до той поры, пока они нужны? Однако это еще не всё.
Второй момент - масштабирование.
Когда поток сообщений становится все больше и больше, а одного кластера будет мало, можно развернуть их несколько. К примеру, это актуально, если вы имеете несколько ЦОД, а вам надо копировать между ними информацию. Или же представьте ситуацию, когда в требованиях по доступности информации указано, что вы обязаны иметь в каждом ЦОД полноценную копию данных.
Да, механизмы репликации в кластерах Kafka поддерживают лишь работу внутри одного кластера, а репликация между несколькими кластерами не выполняется. Но выход есть - утилита Mirror Maker из пакета Kafka. Она не просто свяжет очередью продьюсера и консьюмера, но и будет получать сообщения из одного кластера, публикуя их в другом.
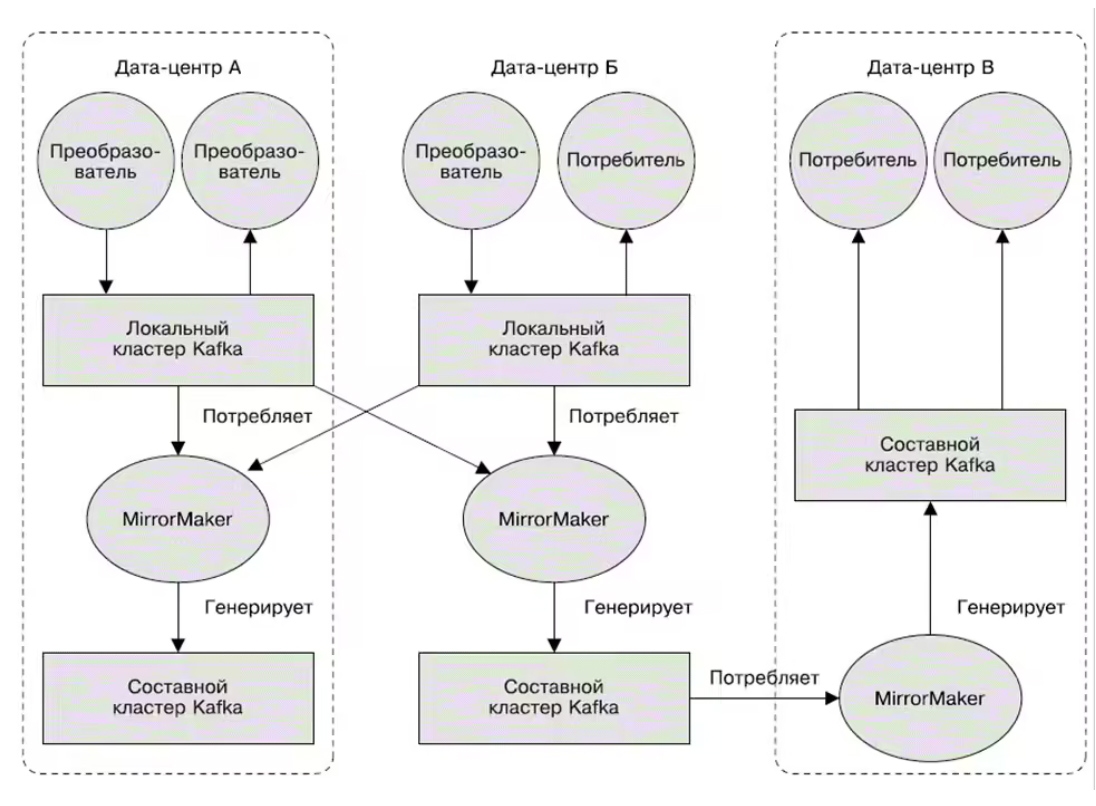
Пример использования MirrorMaker смотрите ниже. Там сообщения из 2-х локальных кластеров агрегируются в составной кластер, а он потом копируется в другие ЦОД. Красота!
Топики в Apache Kafka
Мало кто не знаком с Apache Kafka.

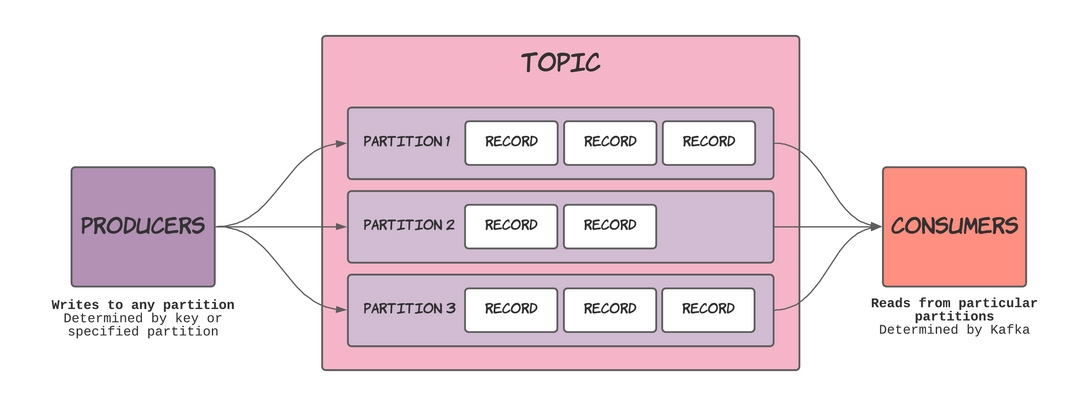
По своей сути топики можно сравнить с БД в стандартных системах управления базами данных. При этом топики разбиваются на разделы, а эти разделы представляют собой отдельные журналы, функционирующие по принципу FIFO, то есть по принципу очереди. Каждый раздел -- это отдельный журнал.
Ниже - процесс записи сообщений по разделам:
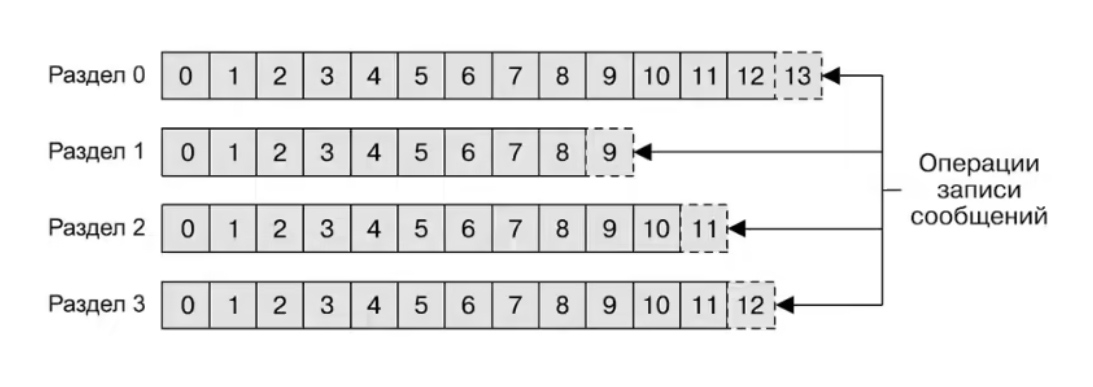
Благодаря нескольким разделам, Kafka обеспечивает как избыточность, так и масштабируемость, что не может не радовать.
Кроме того, любой раздел вы можете расположить на отдельном сервере, а это уже повышает возможности по горизонтальному масштабированию системы на несколько серверов, что значительно увеличивает производительность. Таким образом, можно сказать, что в Apache Kafka поток данных является отдельным топиком вне зависимости от числа разделов.
Гибкость в хранении информации и масштабировании в Kafka
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
ВведениеS3-совместимые объектные хранилища давно перестали быть «файловым складом для резервных копий». Сегодня это ключевой компонент инфраструктуры для раздачи статики, хранения медиафайлов, логов, ...
Масштабирование Elasticsearch требует балансировки шарда, производительности зап...
GitOps совершает революцию в управлении инфраструк...
Проектирование платформ не заменяет DevOps —...
Исследуйте синергию GitOps и Kubernetes в современ...
Изучаем преимущества DevOps и SRE для доступности ...
Автоматизация играет жизненно важную роль в DevOps...
DevOps (акроним от англ. development & operati...
Apache Kafka это больше про большие данные и потоковую обработку.
Kafka идеально подойдет, если в реальном времени требуется обрабатывать огромные куски данных, требующие обработки сообщений с частотой от тысяч до миллионов сообщений в секунду.
Kafka также подходит для реализации систем логирования и мониторинга, где данные собираются с большого числа источников.
Или если есть сценарии, когда несколько потребителей должны получить все сообщения (например, в системах подписок).
RabbitMQ идеален для более стандартной очереди или брокера сообщений:
Если нужна сложная маршрутизация сообщений (например, выборочная подписка или публикация), он предоставляет очень гибкие функции.
Он может стать отличным выбором для обычных задач, связанных с посылкой краткосрочных сообщений от одного микросервиса к другому.
RabbitMQ также подходит, когда нужна поддержка разных протоколов обмена и более зрелый подход к стандартной очереди задач.
Несколько примеров использования в больших корпорациях:
Apache Kafka и LinkedIn
Kafka был изначально разработан командой LinkedIn для обработки активности пользователей на сайте и использования этих данных для усовершенствования продуктов. Например, предоставления рекомендаций на основе действий пользователей в реальном времени. До сих пор LinkedIn активно использует Kafka для обработки более чем 1,4 триллиона сообщений в день.
Apache Kafka и Netflix
Kafka в Netflix используется для обработки и анализа огромного количества логов, которые приходят на их серверы при воспроизведении видео. Информация в реальном времени используется для мониторинга производительности и улучшения качества потокового воспроизведения.
RabbitMQ и Mozilla
Mozilla использует RabbitMQ для сбора статистической информации от своих пользователей. Вместо того, чтобы каждый клиент напрямую отправлял статистику на центральный сервер, которому может быть сложно справиться с таким большим объемом данных, клиенты отправляют свои данные в RabbitMQ, который затем обрабатывает их в более управляемый формат.
RabbitMQ и Vanguard
Vanguard, одна из крупнейших компаний управления инвестициями, использует RabbitMQ в качестве посредника сообщений для своей сложной инфраструктуры. RabbitMQ помогает Vanguard поддерживать надежность и эффективность своих услуг.
В итоге, выбор между Apache Kafka и RabbitMQ зависит в основном от требований к пропускной способности, сообщениям и обработке данных в твоем проекте. Как всегда, нужно всегда тестировать и оценивать различные инструменты, чтобы найти лучший для своих задач.
Использование RabbitMQ и Apache Kafka на одном проекте
Такое решение может объединить преимущества обоих брокеров сообщений для обработки различных типов сообщений и данных. Это дает возможность позволить получить максимальную производительность и гибкость в обработке данных.
В проекте, где необходимо обрабатывать большие объемы потоков данных, можно использовать Kafka, а для обработки очередей сообщений можно использовать RabbitMQ. Также это может быть полезным в случаях, когда требуется обработать данные и события в режиме реального времени, а затем передать их для задач более широкого использования.
Например, представим стартап, который выпускает мобильное приложение для фитнес-отслеживания. В этом приложении пользователи могут записывать свои тренировки, отслеживать прогресс, а также получать обратную связь и советы.
Вот, как могут быть использованы Apache Kafka и RabbitMQ:
Apache Kafka. Когда пользователи ведут активный образ жизни и во время тренировок делают много действий в приложении (например, стартуют и останавливают трекер, записывают упражнения, делают заметки и т.д.), все эти действия генерируют огромное количество данных. Kafka используется для сбора этих данных в реальном времени и обработки их в виде потока.
RabbitMQ. Всегда есть важные события, которые должны быть обработаны немедленно и гарантированно, такие, как уведомления пользователей. Например, если приложение должно отправить уведомление пользователю о достижении его ежедневной цели активности, использование RabbitMQ позволит гарантировать, что это уведомление будет отправлено и доставлено.
Итак, Kafka используется для обработки больших потоков данных, а RabbitMQ – для гарантии доставки важных уведомлений. Оба эти инструмента работают вместе, чтобы обеспечить надежную и эффективную обработку данных в реальном времени для этого фитнес-приложения.
При этом важно отметить, что это всего лишь один из потенциальных вариантов использования. В зависимости от конкретных потребностей проекта инструменты могут быть использованы в совершенно других целях и на разных этапах обработки данных. Все зависит от бизнес-требований, архитектуры системы и технической среды.
Второй момент — масштабирование.
Когда поток сообщений становится все больше и больше, а одного кластера будет мало, можно развернуть их несколько. К примеру, это актуально, если вы имеете несколько ЦОД, а вам надо копировать между ними информацию. Или же представьте ситуацию, когда в требованиях по доступности информации указано, что вы обязаны иметь в каждом ЦОД полноценную копию данных.
Да, механизмы репликации в кластерах Kafka поддерживают лишь работу внутри одного кластера, а репликация между несколькими кластерами не выполняется. Но выход есть — утилита Mirror Maker из пакета Kafka. Она не просто свяжет очередью продьюсера и консьюмера, но и будет получать сообщения из одного кластера, публикуя их в другом.
Пример использования MirrorMaker смотрите ниже. Там сообщения из 2-х локальных кластеров агрегируются в составной кластер, а он потом копируется в другие ЦОД. Красота!