

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Архитектура Веба: основы для начинающих разработчиков

Неопытные разработчики вряд ли поймут, что изображено на диаграмме ниже. Но без понимания концептуальных основ работы современного веба тяжело назвать себя хорошим веб-программистом. В материале будет приведено краткое объяснение, которое поможет разобраться в происходящем, а после каждый элемент будет разобран в деталях.
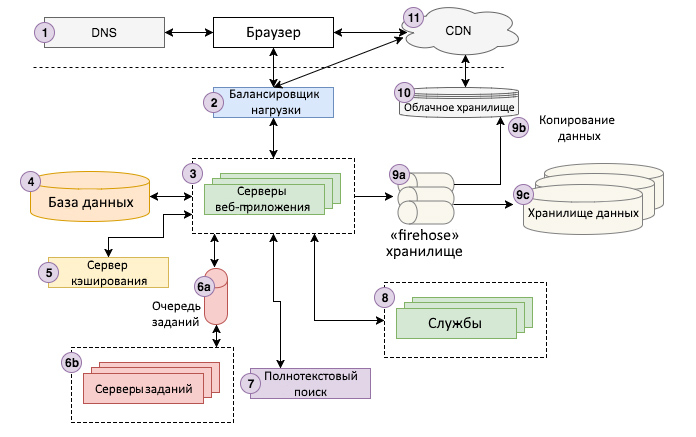
Пользователь ищет в Google «Strong Beautiful Fog And Sunbeams In The Forest». Первый результат отправляет его на Storyblocks. Пользователь нажимает на ссылку, которая перенаправляет его браузер на страницу с изображением. Тем временем браузер отправляет запрос на DNS-сервер, чтобы установить соединение со Storyblock, и, получив ответ, отправляет запрос на сайт.
Запрос попадает на балансировщик нагрузки, который случайным образом выбирает для обработки запроса один из десяти (или около того) веб-серверов, на которых запущен сайт. Веб-сервер достаёт некоторую часть информации об изображении из службы кэширования, а остальное — из основной базы данных. Если цветовой профиль для изображения ещё не был вычислен, задача «определить цветовой профиль» будет добавлена в очередь заданий. Эти задания серверы обрабатывают асинхронно и соответствующим образом обновляют базу данных с результатами.
Затем происходит поиск похожих фотографий: в службу полнотекстового поиска отправляется запрос с заголовком фотографии в качестве входных данных. Если пользователь авторизовался в Storyblocks, информация о его учётной записи загружается из базы данных учётных записей. Наконец, данные о просмотре страницы отправляются в firehose-хранилище для последующей записи в облачную систему хранения. В конечном счёте, эти данные будут загружены в хранилище данных, которое аналитики используют для обработки.
Теперь сервер рендерит страничку в HTML и отправляет её обратно браузеру пользователя, проходя сначала через балансировщик нагрузки. Страница содержит Javascript- и CSS-файлы, которые загружены в облачную систему хранения, подключённую к CDN, поэтому браузер связывается с CDN для получения содержимого. Наконец, браузер отображает страницу пользователю.
Далее будет рассказано про каждый элемент в деталях. Конечно, каждую тему можно рассмотреть гораздо подробнее, но в рамках этой статьи будут разобраны только основы. Этого должно хватить для понимания архитектуры современного веб-проекта.
1. DNS
DNS расшифровывается как «Domain Name System» (система доменных имён). Это базовая технология, которая делает возможной работу интернета. На самом базовом уровне DNS обеспечивает поиск пары из доменного имени и IP-адреса (например, google.com и 85.129.83.120), что позволяет компьютеру отправить запрос на соответствующий сервер. По аналогии с телефонными номерами разница между доменным именем и IP-адресом такая же, как и между вызовом Джону Доу и звонком по номеру 201-867-5309. Для поиска номера Джона нужна телефонная книга, а для поиска IP-адреса домена — DNS. Таким образом, можно считать DNS телефонной книгой интернета.
2. Балансировщик нагрузки
Прежде чем начать обсуждение балансировки нагрузки, нужно сделать шаг назад, чтобы обсудить горизонтальное и вертикальное масштабирование приложений. Что это и в чём разница? Эта тема хорошо объяснена в посте на StackOverflow: «горизонтальное» масштабирование характеризуется добавлением новых машин в пул ресурсов, тогда как «вертикальное» подразумевает, что наращивается мощность (например, увеличивается CPU или RAM) существующей машины.
В веб-разработке проект масштабируется горизонтально как минимум потому, что всё ломается. Серверы падают по непонятным причинам. Сети деградируют. В некоторых ЦОД-ах время от времени отключается свет. Несколько серверов позволит переживать незапланированные отключения без нарушения работы приложения. Другими словами, приложение становится «отказоустойчивым». Горизонтальное масштабирование позволяет минимально связывать разные части проекта (веб-сервер, базу данных и т. д.), потому что каждая из них запускается на разных серверах. Наконец, может наступить такой момент, когда вертикальное масштабирование более невозможно, так как в мире нет достаточно мощного компьютера для выполнения всех вычислений приложения. Поисковая платформа Google является типичным примером, хотя это относится и к компаниям с гораздо меньшими масштабами. Например, Storyblocks обычно использует от 150 до 400 AWS-машин EC2 в любой момент времени. Было бы сложно получить всю эту вычислительную мощность с помощью вертикального масштабирования.
Давайте вернёмся к балансировщикам нагрузки. Благодаря им возможно горизонтальное масштабирование. Они направляют входящие запросы на один из множества серверов приложения, которые обычно являются зеркальными копиями друг друга, и отправляют ответ обратно пользователю. Любой сервер обрабатывает запросы одинаково, так что балансировщик занимается распределением заданий, чтобы никакой из них не был перегружен.
Вот и всё. Концептуально балансировщики нагрузки довольно просты и понятны.
3. Серверы веб-приложений
Если смотреть издалека, серверы веб-приложений относительно просты. Они выполняют основную бизнес-логику, которая обрабатывает запрос пользователя и отправляет HTML обратно браузеру. Чтобы выполнять свою работу, они обычно общаются с различными бэкэнд-инфраструктурами, такими как базы данных, серверы кэширования, очереди заданий, службы поиска и т. д. Как упоминалось выше, обычно есть как минимум два, а то и больше, сервера, подключённых к балансировщику нагрузки для обработки пользовательских запросов.
Для реализации сервера приложений требуется выбрать конкретный язык (Node.js, Ruby, PHP, Scala, Java, C#, .NET и т. д.) и MVC-фреймворк для этого языка (Express для Node.js, Ruby on Rails, Play для Scala, Laravel для PHP и т. д.).
4. Сервер баз данных
Каждое современное веб-приложение использует одну или несколько баз данных для хранения информации. Базы данных предоставляют инструменты для организации, добавления, поиска, обновления, удаления и выполнения вычислений над данными. В большинстве случаев серверы веб-приложений напрямую общаются с серверами заданий. Кроме того, у каждой серверной службы может быть соответствующая база данных, изолированная от остальной части приложения.
Здесь стоит упомянуть SQL и NoSQL.
SQL расшифровывается как «Structured Query Language» (язык структурированных запросов). Он был изобретён в 1970-х годах, чтобы создать стандартный способ запросов к реляционным наборам данных, доступных широкой аудитории.

Рассмотрим типичный пример хранения информации об истории адресов пользователей. Получатся две таблицы — user и user_addresses, — связанные друг с другом идентификатором пользователя (id в таблице user). Их можно увидеть на изображении ниже. Таблицы связаны, потому что столбец user_id в user_addresses является «внешним ключом» в столбце id в таблице users.
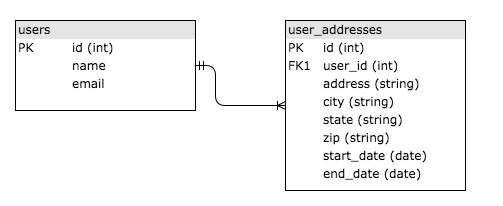
Если вы мало что знаете о SQL, настоятельно рекомендуем ознакомиться с нашим курсом по этой теме. Эта технология используется в веб-разработке почти везде, поэтому стоит хотя бы понимать основы для правильного построения приложений.
NoSQL расшифровывается как «не-SQL» и представляет собой более новый набор технологий баз данных. Он был разработан для обработки очень больших объёмов информации, которые могут генерироваться крупномасштабными веб-приложениями. Большинство вариантов SQL плохо масштабируются горизонтально, а масштабироваться вертикально могут только до определённого момента.
Также хочется отметить, что индустрия повсеместно полагается на SQL даже как на интерфейс для баз данных NoSQL, поэтому нужно изучать SQL, даже если он не требуется в вашей работе. В современных реалиях почти невозможно этого избежать.
5. Кэширование
Служба кэширования предоставляет простое хранилище данных в формате ключ-значение, которое позволяет хранить и искать информацию за время, близкое к линейному (O(1)). Обычно приложения используют функции кэширования, чтобы сохранять результаты дорогостоящих вычислений и воспользоваться ими позже из кэша, а не пересчитывать их еще раз. Приложение может кэшировать результаты запроса в базы данных, результаты обращения к внешним службам, HTML для заданного URL-адреса и многое другое. Вот некоторые примеры из реального мира:
Google кэширует результаты поиска для популярных поисковых запросов, таких как «собака» или «Тейлор Свифт», а не ищет их каждый раз заново;
Facebook кэширует большую часть данных, которые вы видите при входе в систему, например, списки постов или друзей. Подробнее, о технологии кэширования используемого в Facebook, можно почитать в этой статье на Medium;
Storyblocks кэширует HTML-страницы от React, результаты поиска и другое.
Двумя наиболее распространёнными технологиями кэширования являются Redis и Memcache.
Смотрите также: Четыре уровня кэширования в сети: клиентский, сетевой, серверный и уровень приложения
6. Очереди задач
Большинству веб-приложений требуется выполнять некоторую работу, напрямую не связанную с ответом на запросы пользователей, асинхронно, в фоновом режиме. Например, Google должен сканировать и индексировать весь интернет, чтобы возвращать релевантные результаты поиска. Он не делает это при каждом запросе, а сканирует сеть асинхронно, обновляя поисковые индексы «по пути».
Выполнять асинхронную работу позволяют разные архитектуры, но наиболее распространённой является архитектура «очередь задач». Она состоит из двух компонентов: очереди «заданий», которые необходимо выполнить, и одного или нескольких рабочих серверов (часто называемых «работниками»), которые обрабатывают задания из очереди.
В очередях задач хранятся списки заданий, которые нужно выполнить асинхронно. Всякий раз, когда приложению нужно выполнить какую-то задачу, которая должна выполняться по расписанию или в соответствии с действием пользователя, оно добавляет её в очередь. Проще всего организованы очереди FIFO — «первым пришёл — первым ушёл», но большинство приложений в конечном итоге нуждаются в какой-то системе балансировки очередей.
Например, в Storyblocks очередь заданий используется для выполнения многих скрытых работ, необходимых для поддержания проекта: кодирование видео и фотографий, обработка CSV-файлов для тегов метаданных, агрегирование статистики пользователей, отправка писем с паролями для сброса и т. д. Со временем проект отказался от простой очереди FIFO в пользу приоритетной очереди, чтобы операции с фиксированным временем выполнения, такие как отправка писем о сбросе пароля, были завершены как можно скорее.
Сервера заданий выполняют задания из очереди. Они запрашивают её, чтобы определить, есть ли работа, и если есть, — приступают к выполнению.
7. Полнотекстовый поиск
Многие, если не большинство, веб-приложений поддерживают функцию поиска по текстовому вводу (часто называемого «запрос»), в котором приложение возвращает наиболее «релевантные» результаты. Технология, использующая эту функцию, обычно называется «полнотекстовым поиском» и использует инвертированный индекс для быстрого поиска документов, содержащих ключевые слова запроса.
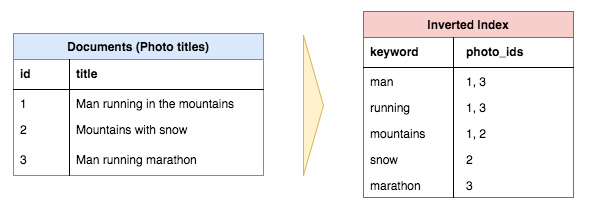
В этом примере три заголовка документов преобразуются в инвертированные индексы, что облегчает поиск по определённому ключевому слову среди документов с этим ключевым словом в заголовке. Обратите внимание, что обычные слова, также называемые стоп-словами («in», «the», «with» и т. д.), обычно не включаются в инвертированный индекс.
В действительности можно выполнять полнотекстовый поиск непосредственно из некоторых баз данных (например, его поддерживает MySQL), но обычно принято запускать отдельную службу, которая вычисляет и сохраняет инвертированные индексы и предоставляет интерфейс для запросов. Самая популярная полнотекстовая поисковая платформа сегодня — Elasticsearch, хотя есть и другие варианты, такие как Sphinx или Apache Solr.
8. Службы
Когда приложение достигает определённого масштаба, как правило, появляются определённые «службы», созданные специально для запуска в виде отдельных приложений. Они не выставлены на всеобщее обозрение, но приложение и другие службы взаимодействуют с ними. Например, в Storyblocks имеются несколько операционных и плановых служб:
служба учётных записей хранит пользовательские данные для всех сайтов компании, что позволяет работать перекрёстно и создаёт более унифицированный опыт использования;
служба контента хранит метаданные для видео, аудио и изображений, а также предоставляет интерфейсы для загрузки содержимого и просмотра истории загрузок;
служба оплаты предоставляет интерфейс для оплаты кредитными картами;
HTML → PDF сервис предоставляет простой интерфейс, который принимает HTML-код и возвращает соответствующий PDF-документ.
9. Хранилище данных
Будет компания жить или нет во многом определяется тем, как она работает с данными. Почти каждое современное приложение, достигая определённого масштаба, переходит к одной и той же организации сбора, хранения и анализа данных. Работа с данными проходит в три основных этапа:
Приложение отправляет данные в «firehose»-хранилище, которое обеспечивает потоковый интерфейс для поглощения и обработки данных. Как правило, это информация о действиях пользователей. Часто необработанные данные преобразуются или дополняются и передаются в другие «firehose»-хранилища. Наиболее распространённые технологии для этого процесса — AWS Kinesis и Kafka.
Исходные, а также окончательно преобразованные и дополненные данные сохраняются в облачном хранилище. AWS Kinesis предлагает сервис под названием Firehose, который позволяет сохранять необработанные данные в облачном хранилище (S3), которое чрезвычайно просто в настройке.
Преобразованные и дополненные данные загружаются в хранилище данных для анализа. Типичным примером является AWS Redshift, им пользуется большинство стартапов, хотя крупные компании предпочитают решения от Oracle или другие проприетарные технологии хранения. Если наборы данных достаточно велики, то для анализа может потребоваться технология NoSQL MapReduce, например, Hadoop.
На диаграмме не изображён ещё один шаг: загрузка данных из приложения и баз данных различных служб в хранилище. Например, Storyblocks каждую ночь загружает VideoBlocks, AudioBlocks, Storyblocks, службу учётных записей и базы данных портала разработчиков в Redshift. Это даёт аналитикам целостное представление, так как основные бизнес-данные и данные действий пользователей хранятся в одном и том же месте.
10. Облачное хранилище
«Облачное хранилище — простой и масштабируемый способ для хранения и обмена данными через интернет». Такое определение дано AWS. Его можно использовать для хранения и доступа к чему угодно, что можно хранить в локальной файловой системе, пользуясь преимуществами RESTful API через HTTP. Решение от Amazon S3 на сегодняшний день является самым популярным облачным хранилищем, и его широко используют в Storyblocks для хранения видео-, фото- и аудиофайлов, CSS- и JavaScript-файлов, данных действий пользователей и многого другого.
11. CDN
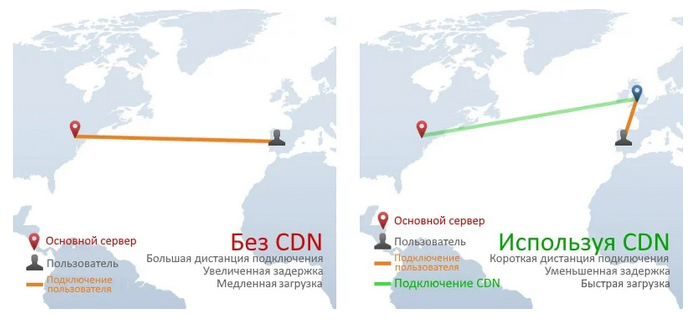
CDN расшифровывается как «Content Delivery System» (система доставки контента). Эта технология позволяет намного быстрее, чем с исходного сервера, отправлять статические HTML-, CSS-, JavaScript-файлы и изображения. Она распространяет контент из многих «конечных» серверов по всему миру, чтобы пользователи загружали различные ресурсы из них вместо исходного сервера. Например, на изображении ниже пользователь из Испании запрашивает веб-страницу с сайта, серверы которого находятся в Нью-Йорке, но статические ресурсы для этой страницы загружаются с «конечного» сервера CDN в Англии, предотвращая медленные кросс-атлантические HTTP-запросы.
Удачи в покорении веба!
Архитектура Веба: основы для начинающих разработчиков
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Технические ограничения, создавшие разрыв между внутренним и внешним циклами, устраняются как раз вовремя, чтобы объединение этих циклов стало необходимостью для рабочих процессов агентов.На протяжени...
Выбор парадигмы проектирования API — GraphQL или REST — представляет...
В 2026 году команды разработчиков программного обе...
В эпоху стремительной цифровизации качество и эффе...
Открытый исходный код преобразует сетевые техно...
В мире технологий, где языки и фреймворки сходят с...
Сложность распределённых систем — важная про...
Low-code дополняет разработчиков, автоматизируя ру...
Развитие информационных технологий - ключевой факт...
Выбор API играет ключевую роль в успехе и эффектив...
В современном обществе программирование становится...
Выбираем направление
От фронтенда, бэкенда и вот этого всего голова может идти кругом — поэтому давайте определимся что это за направления.
Фронтенд
Вся лицевая сторона. Фронтенд-разработчик отвечает за то, что пользователь видит и с чем взаимодействует на странице. Например: дизайн, визуальные элементы, схемы.
Задачи фронтендера — сделать сайт, который будет решать задачи владельца, одинаково корректно работать на всех устройствах, независимо от браузера и размера экрана и при этом будет удобен пользователю.
Основные инструменты: HTML, CSS и JavaScript.
Подойдёт тем, кто педантично относится к деталям и хочет сразу видеть результат своей работы.
Бэкенд
Невидимая часть сайта. Бэкенд-разработчик отвечает за то, что скрыто от глаз пользователя и работает на сервере. Например: создание базы данных и программы, которые будут записывать информацию в базу, шифрование паролей и ценной информацией, настраивание доступов и системы резервного копирования данных, написание программы, обрабатывающие информацию, невидимую пользователю.
Языков программирования для бэкенда несколько: PHP, Ruby, Python или Node.js. Для бэкенд-разработки нужны системы управления базами данных: MySQL, PostgreSQL, SQLite или MongoDB.
Подойдёт тем, кому интересна работа с данными и решение архитектурных задач.
— Калькулятор: Создайте простое приложение для выполнения арифметических операций. Это поможет вам освоить основные концепции программирования, такие как ввод и вывод данных, условные операторы и циклы.
— Простой веб-сайт: Создайте веб-страницу с HTML, CSS и JavaScript. Это поможет вам понять основы веб-разработки и взаимодействие между различными технологиями.
— Игра на основе текста: Напишите текстовую игру, в которой игроки могут принимать решения и влиять на развитие сюжета. Это поможет вам освоить работу с текстом и логическими условиями.
— Приложение для заметок: Создайте приложение для создания и управления заметками. Это поможет вам освоить работу с файлами и базами данных.
Лично я к онлайн курсам отношусь скептически, учат все в кашу и дают много теории, так что больше практики товарищи и все получиться