

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Исследование двоичного квантования в векторных базах данных

Двоичное квантование в векторных базах данных повышает эффективность, производительность и оптимизирует хранение данных для расширенного поиска и анализа информации.
Векторные базы данных — это специализированные системы, предназначенные для хранения и извлечения многомерных векторных представлений неструктурированных, сложных данных, таких как изображения, текст или аудио. Представляя сложные данные в виде числовых векторов, эти системы понимают контекстное и концептуальное сходство, предоставляя заметно схожие результаты для запросов, а не точные совпадения, что обеспечивает расширенный анализ и поиск данных.
По мере увеличения объема данных в векторных базах данных хранение и извлечение информации становится все более сложной задачей. Двоичное квантование упрощает многомерные векторы до компактных двоичных кодов, уменьшая размер данных и повышая скорость поиска. Такой подход повышает эффективность хранения и обеспечивает более быстрый поиск, позволяя базам данных более эффективно управлять большими наборами данных.
Понимание двоичного квантования
После получения первоначального внедрения применяется двоичное квантование. Двоичное квантование сводит каждую особенность данного вектора к двоичной цифре 0 или 1. Оно присваивает 1 положительным значениям и 0 отрицательным значениям, фиксируя знак соответствующего числа.
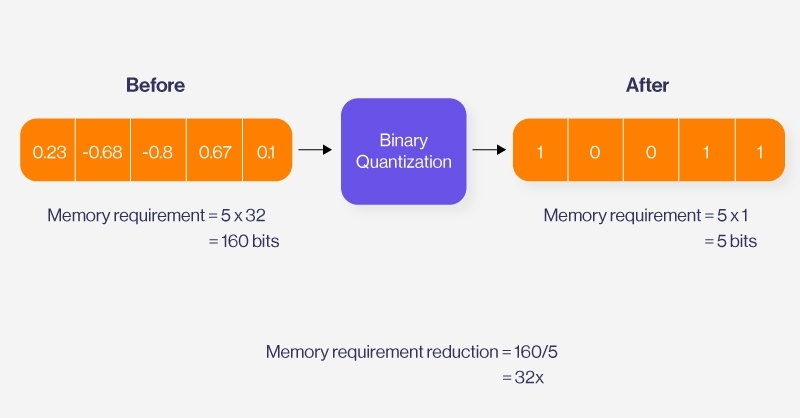
Например, если изображение представлено четырьмя различными объектами, каждый из которых содержит значение в диапазоне единиц хранения FLOAT-32, выполнение двоичного квантования этого вектора преобразует каждый объект в одну двоичную цифру. Таким образом, исходный вектор, состоящий из четырех значений FLOAT-32, будет преобразован в вектор с четырьмя двоичными цифрами, например [1, 0,0, 1], занимающий всего 4 бита.
Это значительно уменьшает объем пространства, занимаемого каждым вектором, в 32 раза за счет преобразования числа, хранящегося в каждом измерении, из числа с плавающей запятой32 в 1-битное. Однако обратить этот процесс вспять невозможно, что делает этот метод сжатия с потерями.
Почему двоичное квантование хорошо работает для многомерных данных
При расположении вектора в пространстве знак указывает направление движения, а величина указывает, насколько далеко нужно двигаться в выбранном направлении.
При двоичном квантовании мы упрощаем данные, сохраняя знак каждого компонента вектора — 1 для положительных значений и 0 для отрицательных. Хотя это может показаться крайностью, поскольку при этом не учитывается величина движения вдоль каждой оси, на удивление это работает исключительно хорошо для многомерных векторов. Давайте выясним, почему этот, казалось бы, радикальный подход оказывается настолько эффективным!
Преимущества двоичного квантования в векторных базах данных
Улучшенная производительность
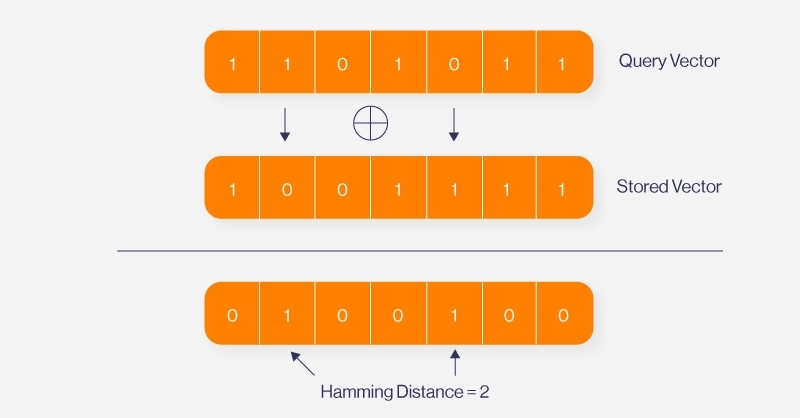
Двоичное квантование повышает производительность за счет представления векторов двоичными кодами (0 и 1), что позволяет использовать расстояние Хэмминга в качестве показателя сходства. Расстояние Хэмминга вычисляется с помощью операции XOR между двоичными векторами: XOR приводит к 1, если биты различаются, и 0, если они одинаковы. Количество единиц в результате операции XOR указывает количество различающихся битов, обеспечивая быструю и эффективную оценку сходства.
Этот подход упрощает и ускоряет сравнение векторов по сравнению с более сложными метриками расстояний, такими как евклидово расстояние.
Повышенная эффективность
Двоичное квантование сжимает векторы из 32-битных чисел с плавающей запятой в 1-битные двоичные цифры, что резко снижает требования к хранению, как показано на рисунке выше. Такое сжатие снижает затраты на хранение и ускоряет скорость обработки, что делает его высокоэффективным для векторных баз данных, которым необходимо хранить огромные объемы данных и управлять ими.
Масштабируемость
Мы уже обсуждали, как увеличение размерностей уменьшает количество коллизий в представлении, что делает двоичное квантование еще более эффективным для многомерных векторов.
Эти расширенные возможности позволяют эффективно управлять и хранить огромные наборы данных, поскольку компактный двоичный формат значительно сокращает пространство для хранения и вычислительную нагрузку. По мере роста числа измерений экспоненциальное увеличение потенциальных областей обеспечивает минимальные коллизии, сохраняя высокую производительность и скорость реагирования.

Проблемы и соображения
Точность и точность
Хотя двоичное квантование значительно ускоряет операции поиска, оно влияет на точность и точность результатов поиска. Нюансы и детали, представленные в данных более высокого разрешения, могут быть потеряны, что приведет к менее точным результатам. Более того, двоичное квантование представляет собой сжатие с потерями, то есть после того, как данные подверглись квантованию, исходная информация безвозвратно теряется. Интеграция двоичного квантования с передовыми методами индексации, такими как HNSW, может помочь повысить точность поиска, сохраняя при этом преимущества скорости двоичного кодирования.
Сложность реализации
Специализированное аппаратное и программное обеспечение, такое как инструкции SIMD (одна инструкция, несколько данных), необходимы для ускорения побитовых операций, позволяя одновременно обрабатывать несколько точек данных, что значительно ускоряет вычисления даже при использовании метода грубой силы для расчета сходства.
Предварительная обработка данных
Двоичное квантование предполагает, что данные имеют нормальное распределение. Когда данные искажены или имеют выбросы, двоичное квантование может привести к неоптимальным результатам, влияя на точность и эффективность векторной базы данных.
Расхождения в показателях
Бинарный квантователь точно использует расстояние Хэмминга для таких угловых показателей, как сходство косинусов, но противоречит таким метрикам, как евклидово расстояние. Таким образом, его следует правильно выбирать в соответствии с областью применения для измерения расстояния между битами.
Будущие тенденции и разработки
Мы можем рассчитывать на определенные улучшения в двоичном квантовании, такие как корректировка порогов на основе распределения данных для повышения точности и включение контуров обратной связи для постоянного улучшения. Кроме того, сочетание двоичного квантования с передовыми методами индексации обещает еще больше оптимизировать эффективность поиска.
Применение двоичного квантования в векторных базах данных
- Извлечение изображений и видео. Изображения и видео представляют собой многомерные данные, требующие значительных затрат на хранение. Например, одно изображение с высоким разрешением может содержать миллионы пикселей, каждому из которых требуется несколько байтов для представления информации о цвете. Двоичное квантование сжимает эти многомерные векторы признаков в компактные двоичные коды, что значительно снижает потребности в хранении и повышает эффективность поиска.
- Системы рекомендаций. Двоичное квантование расширяет возможности систем рекомендаций за счет преобразования векторов функций пользователя и элемента в компактные двоичные коды, повышая как скорость, так и эффективность. Это можно дополнительно оптимизировать путем объединения с методами ближайшего соседа, такими как LSH, обеспечивая точные рекомендации посредством уточненного поиска.
- Обработка естественного языка (NLP): двоичное квантование помогает обрабатывать и анализировать текстовые данные за счет снижения требований к хранению в векторной базе данных, обеспечивая эффективную производительность. Этот метод НЛП позволяет быстрее извлекать и сравнивать текстовые данные, делая чат-ботов более отзывчивыми и эффективными при обработке запросов пользователей.
Заключение
По мнению разработчиков компании DST Global, двоичное квантование предлагает мощное решение для обработки сложных векторных данных большой размерности в векторных базах данных. Преобразуя многомерные векторы в компактные двоичные коды, этот метод радикально снижает требования к хранению и ускоряет время поиска.
Кроме того, его интеграция с передовыми методами индексирования может еще больше повысить точность и эффективность поиска, что делает его универсальным инструментом поиска информации. Векторные базы данных, используемые для хранения многомерных данных, могут использовать быстродействующее оборудование хранения для ускорения вашей рабочей нагрузки, будь то обучение искусственному интеллекту или приложения на основе RAG.
Исследование двоичного квантования в векторных базах данных
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Одним из самых фундаментальных и критически важных решений при создании современного приложения является выбор технологии для хранения данных. Этот выбор, часто стоящий перед архитекторами и разраб...
Выбор правильной базы данных является критически важным выбором при создании люб...
Цель этой статьи — ответить на один вопрос: ...
В этой статье разработчиками компании DST Global, ...
Программное обеспечение хранилища данных помогает ...
В этой статье разработчики компании DST Global ...
В этой статье вы узнаете от разработчиков компании...
Узнайте о преимуществах от разработчиков компании ...
Oracle — самая популярная база данных в мире...
Повысьте производительность и масштабируемость, ис...
Векторные базы данных оказывают значительное воздействие на различные отрасли. Частым применением векторных баз данных является поиск подобного.
В ритейле
Векторные базы данных в розничной торговле, обеспечивают продвинутые системы рекомендаций, которые выдают персонализированные предложения на основе атрибутов продуктов и предпочтений пользователей.
Обработка естественного языка (NLP)
Векторные базы данных улучшают приложения NLP, позволяя чат-ботам и виртуальным помощникам лучше понимать и отвечать на человеческий язык, улучшая взаимодействие между клиентами и агентами.
Анализ финансовых данных
В финансовой сфере векторные базы данных анализируют сложные данные, чтобы помочь аналитикам обнаруживать закономерности, принимать обоснованные инвестиционные решения и прогнозировать движение рынка.
Обнаружение аномалий
Векторные базы данных отлично подходят для обнаружения выбросов, особенно в секторах финансов, что делает процесс обнаружения аномалий быстрее и точнее, тем самым предотвращая мошенничество и нарушения безопасности.
Здравоохранение
Векторные базы данных персонализируют медицинское лечение, анализируя геномные последовательности и соотнося решения с индивидуальной генетической структурой.
Анализ медиа-материалов
Векторные базы данных упрощают анализ изображений, помогая в задачах, таких как интерпретация медицинских сканов и видеонаблюдение для оптимизации потока трафика и обеспечения общественной безопасности.
Как я понял, она заточена под оптимизацию тегов и других метаданных, которые позволяют создавать сложные связи между данными.
Все остальное это уже варианты использования, так?
Тут ещё стоит добавить, что сами вектора могут позволять делать операции над ними. Соответственно вы можете сделать какие-то преобразования над «смыслами» и потом в базе искать что-то близкое к цели.
Условный пример (работает для некоторых видов эмбеддингов): если из вектора для слова «король» вычесть вектор для слова «мужчина» и прибавить вектор для слова «женщина», то вы получите вектор, близкий к вектору для слова «королева».
— Улучшенная производительность. Представление векторов двоичными кодами (0 и 1) позволяет использовать расстояние Хэмминга в качестве показателя сходства.
— Повышенная эффективность. Двоичное квантование сжимает векторы из 32-битных чисел с плавающей запятой в 1-битные двоичные цифры, что резко снижает требования к хранению.
— Применение в системах рекомендаций. Двоичное квантование расширяет возможности систем рекомендаций за счёт преобразования векторов функций пользователя и элемента в компактные двоичные коды.
— Помощь в обработке естественного языка (NLP). Двоичное квантование помогает обрабатывать и анализировать текстовые данные за счёт снижения требований к хранению в векторной базе данных.
Однако обратить процесс двоичного квантования вспять невозможно, что делает его методом сжатия с потерями.