

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Что такое ускорение и масштаб в СУБД?

В этой статье разработчики компании DST Global обсудят ускорение и масштаб в СУБД, две фундаментальные концепции из параллельной обработки для баз данных, которые используются для настройки баз данных.
Ускорение
Хранилище данных с несколькими сотнями гигабайт данных в настоящее время относительно типичны из -за устойчивого увеличения размеров базы данных. Даже несколько терабайт данных могут храниться в некоторых базах данных, называемых очень большими базами данных (VLDB).
Эти хранилища данных подвергаются сложным запросам для получения бизнес-аналитики и поддержки принятия решений. Такие запросы занимают очень много времени для обработки. Вы можете сократить общее время, потраченное на то, что все еще предоставляя необходимое время ЦП, одновременно запустив эти запросы.
Соотношение времени выполнения с использованием одного процессора к времени выполнения с использованием нескольких процессоров известно как ускорение.
Следующая формула используется для его вычисления. Он оценивает преимущество производительности, полученное с использованием более одного процессора вместо одного процессора:
Ускорение равна времени 1 / Тимону
Time1 - это количество времени, необходимое для выполнения задачи с помощью одного процессора, тогда как Тимон - это количество времени, необходимое для выполнения той же работы с M -процессорами.
Кривая ускорения
В идеальном сценарии ускорение от параллельной обработки будет соответствовать количеству процессоров, используемых для каждой заданной операции.
В качестве альтернативы, 45-градусная линия является оптимальной формой для кривой ускорения.
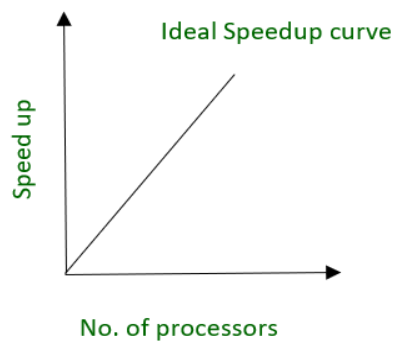
Поскольку параллелизм включает в себя некоторые накладные расходы, оптимальная кривая ускорения редко получается. Степень ускорения, которую вы можете получить, значительно зависит от присущего применения параллелизма .
Компоненты некоторых задач могут быть обработаны параллельно с легкостью. Например, можно сделать два огромных таблица одновременно.
Однако некоторые задачи не могут быть разделены. Одним из таких экземпляров является необоснованное индексное сканирование. Количество ускорения будет минимальным или не существует, если приложение имеет незначительное или нет присутствующего параллелизма.
Эффективность рассчитывается как ускорение, деленное на общее количество процессоров. В нашем примере четыре процессора, а ускорение также четыре. Следовательно, эффективность составляет 100%, что представляет собой идеальный случай.
Пример:
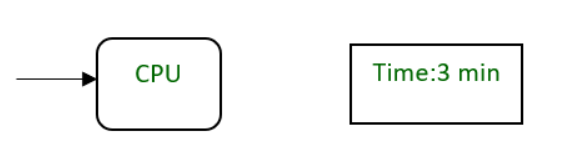
ЦП требует три минуты для выполнения процесса.
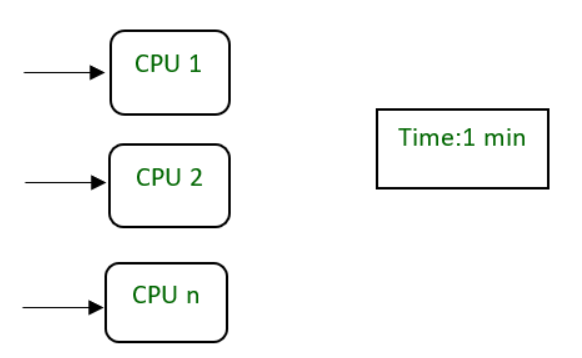
N 'CPU требует одной минуты, чтобы выполнить процесс, разделив его на меньшие задачи.
Типы ускорения
- Линейное ускорение
- Суб-линейное ускорение
Линейное ускорение
Если ускорение n, то ускорение линейное. Другими словами, время прошедшего времени крошечной системы народе времени больше, чем время, проведенное большой системой (n - это количество ресурсов, скажем, процессор).
Например, если одна машина выполняет задачу за 10 секунд, но десять отдельных машин, работающих параллельно, выполняют ту же задачу за 1 секунду, ускорение составляет (10/1) = 10 (см. Уравнение выше), которое равно N, размер большей системы. В десять раз более мощный механизм - это то, что позволяет ускорить.
Суб-линейное ускорение
Если ускорение меньше n, оно является суб-линейным (что обычно в большинстве параллельных систем).
Более проницательные дискуссии: если ускорение является n или линейным, это означает, что производительность такая же ожидаемое.
Два сценария возможны, если ускорение меньше n
Случай 1: Если ускорение превышает n, система работает лучше, чем предполагалось. В этом сценарии значение ускорения будет ниже 1.
Случай 2: Это суб-линейно, если ускорение N. Знаменатель (огромное время прошло время) в этой ситуации превышает истеченное время одной машины.
В этой ситуации значение будет варьироваться от 0 до 1, и нам нужно было бы установить пороговое значение, так что любое значение, под порогом, предотвратило бы параллельную обработку.
Перераспределение рабочей нагрузки между процессорами в такой системе требует особой осторожности.
Несколько методов ускорения вашей базы данных
Теперь давайте посмотрим на некоторые методы, чтобы ускорить базу данных
Индексы
Сохранение эффективной структуры данных поиска, индексы позволяют базе данных быстрее определять местонахождение соответствующих строк (например, B-три ).
Каждая таблица должна выполнить это. Индекс может быть добавлен редко, потому что он может быть вычислительно интенсивным и требует производственной системы.
С SQL ( MySQL , PostgreSQL ), создание индекса просто:
CREATE INDEX random index name
ON your table name
(col1, col2);
Базу данных можно найти быстрее, добавив индекс; Однако UPDATE, INSERT и DELETE Команды занимают больше времени для выполнения, если только пункт «Где» занимает много времени.
Повышение запроса
Пользователь базы данных выполняет оптимизацию запросов для каждого запроса. Есть множество способов написать запросы, и некоторые из них могут быть более эффективными, чем другие.
Проблема n+1 и использование цикла для отправки многочисленных запросов, а не только одного, чтобы получить данные, попадают под слегка отдельную подкатегорию темы оптимизации запросов.
Изменения в бизнесе и разделении
Вы хотите произвести впечатление на своих клиентов по мере расширения вашей фирмы. Вы пытаетесь включить любые незначительные новые функции, которые клиенты запрашивают. Это может привести к ползучести.
Это была проблема довольно давно, согласно философии UNIX:
Сравнимо, разделение данных ваших онлайн -сервисов на группы пользователей может быть приемлемым. Может быть, разделение их на области имеет смысл? Это то, что разработчики DST Global наблюдали в Secure Code Warrior и AWS .
Можно было бы разделить его на «частных клиентов», «клиентов малого бизнеса» и «крупных бизнес -клиентов». Возможно, часть приложения может функционировать в качестве собственной службы с отдельной базой данных.
Репликация
Если чтения являются вашей проблемой, и небольшая задержка времени обновления не является основной сделкой, репликация является простым решением. База данных непрерывно копируется в другую систему во время репликации. Он служит механизмом аварийного переключения и ускоряет чтения.
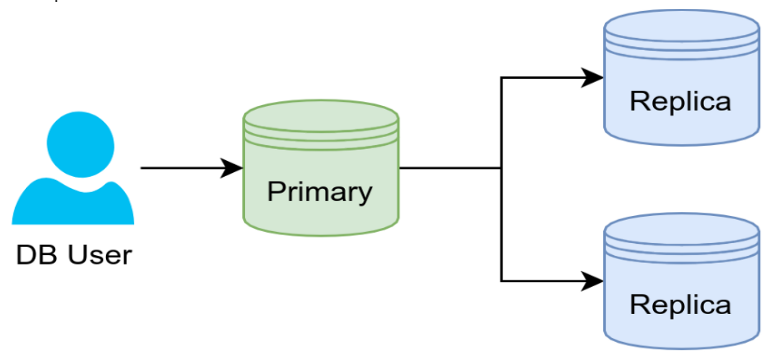
Один основной сервер и многочисленные серверы репликации, которые были ранее известны под разными именами, являются предполагаемой конфигурацией. Обновления данных обрабатываются основным сервером, а не серверами репликации, которые просто отражают основной сервер.

Горизонтальное распределение
Если бы стол был действительно большим, мы могли бы хранить несколько рядов на одной машине, а другие на другой. Горизонтальное разделение - это концепция деления данных на строки.
Вертикальное разделение
Большая база данных может быть разделена на меньшие секции, используя столбцы, а не строки. Вы можете беспокоиться об этом, потому что вас учили в школе, что нормализация базы данных - это хорошо.
То, что мы обсуждаем различные этапы архитектуры базы данных, имеет решающее значение. Логический дизайн связан с многочисленными нормальными видами баз данных. Физический дизайн - это то, на чем мы сосредоточены прямо сейчас.
Возможно, не все столбцы строки требуются всеми компонентами приложения. Может быть приемлемо разделить их из -за этого. Разделение строк - это еще одно название для вертикального разделения из -за этого.
Следует иметь в виду, что масштабирование вертикально не имеет ничего общего с вертикальным разделением!
Вертикальное разделение может быть выгодным, если конфиденциальность или юридические проблемы не участвуют. Рассмотрим информацию о вашей платежной карте.
Хотя было бы логично объединить это с другими данными, большая часть приложения не требует этого, даже лучше, вы можете скрыть его за частным микросервисом и сохранить его в совершенно новой базе данных.
Sharding: следующий шаг в перегородке
Вы видели, что есть два разных способа группировать данные. Чтобы помочь процессу базы данных частые запросы быстрее, возможно, уже имеет смысл разделить данные на одну и ту же систему.
Тем не менее, было бы разумно использовать разные машины, если база данных использует весь процессор или оперативную память на текущем.
Единственный логический набор данных окрашивается и распространяется по различным устройствам.
У этого есть много проблем, как вы можете ожидать, поэтому вы должны использовать его только в качестве последнего средства. Например, в октябре 2010 года проблема с шардингом привела к недоступности Foursquare в течение 11 часов.
Первая очевидная проблема заключается в том, что ваше приложение должно знать, какой у Shard есть желаемые данные. Следовательно, на вашу логику приложения может повлиять повсюду.
Кластеризация баз данных
Только после того, как разработчики DST Global посмотрели на Vitess и столкнулись с этой фразой. Концепция, по -видимому, скрывает проблемы с шардингом, используя репликацию в качестве техники прикрытия.
Масштаб
Добавляя больше процессоров и дисков, масштаб - это способность приложения сохранять время отклика по мере роста размер рабочей нагрузки или объема транзакций. Масштаб часто обсуждается с точки зрения масштабируемости.
Масштаб в приложениях базы данных может основываться на пакетировании или транзакциях. Большие партийные задания могут быть поддержаны с помощью пакетного масштаба без ущерба от времени ответа. Большие количества транзакций могут быть подтверждены с помощью масштаба транзакций, не жертвуя временем ответа.
Больше процессоров добавляется в обоих сценариях для поддержания времени отклика. Например, система с четырьмя процессорами может обеспечить такое же время отклика с 400 транзакциями в минуту бремени, что и система с одним процессором, которая поддерживает 100 транзакций в минуту дежурства.
Идеальная кривая масштабирования
Рисунок показывает идеал в виде кривой или действительно плоской линии. По правде говоря, даже если добавлено больше процессоров, время реакции в конечном итоге увеличивается для увеличения объемов транзакции.
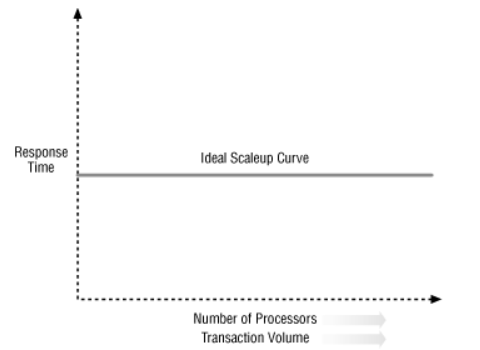
Способность масштабировать определяется тем, насколько больше мощности обработки может быть добавлена, сохраняя при этом постоянное время отклика. Формула ниже используется для определения масштаба:
ScaleUp = Volumem/Volume1
Объем1 - это объем транзакций, проведенных за тот же период времени с использованием одного процессора, тогда как объемный объем - это объем транзакций, выполняемых с использованием M -процессоров. Для предыдущего экземпляра:
ScaleUp = 400/100.
Масштабированный = 4,
Используя четыре процессора, этот масштаб 4 достигается.
Типы масштабирования
- Шкаф в лайнере
- Суб-линейный масштаб
Линейное масштабирование
Если ресурсы растут пропорционально величине проблемы, масштаб является линейным (это очень редко). В предыдущем уравнении говорится, что масштабирование = 1 и является линейным, если время, необходимое для решения небольшой системы, малая проблема равен времени для решения большой системы.
Суб-линейный масштаб
Масштаб является суб-линейным, если истекшее время для крупных систем с огромными проблемами длиннее, чем для небольших систем с незначительными проблемами.
Дополнительные дискуссии, которые имеют отношение к тому, чтобы: система работает безупречно, если масштаб является одним или линейным.
Мы должны проявить дополнительную осторожность при выборе нашего плана для параллельного выполнения, если масштаб сублинерна, а значение колеблется от 0 до 1. Например, если время, необходимое для решения небольшой проблемы, составляет 5 секунд, а большая система с большой Проблема занимает 5 секунд, чтобы решить.
Это демонстрирует линейность ясно. Следовательно, 5/5 = 1. Система превосходно работает для различных значения значения, особенно низких значений (невозможных за пределами предела).
Тем не менее, масштабное значение снижается ниже 1, что требует значительного внимания для лучшего перераспределения задач для более высоких значений знаменателя, таких как 6, 7, 8 и т. Д.
Разница между ускорением и масштабным
Масштаб и ускорение значительно различаются в том, что ускорение вычисляется путем поддержания фиксированного размера задачи, тогда как масштаб определяется путем увеличения размера задачи или объема транзакции.
Насколько объем транзакции может быть увеличен, добавив дополнительные процессоры, однако сохраняя постоянное время отклика, - это то, как измеряется масштаб.
Заключение
Надеемся, эта статья на масштабе и ускорение помогла вам узнать основы того же самого. Спасибо за чтение!
Что такое ускорение и масштаб в СУБД?
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Одним из самых фундаментальных и критически важных решений при создании современного приложения является выбор технологии для хранения данных. Этот выбор, часто стоящий перед архитекторами и разраб...
Выбор правильной базы данных является критически важным выбором при создании люб...
Цель этой статьи — ответить на один вопрос: ...
В этой статье разработчиками компании DST Global, ...
Программное обеспечение хранилища данных помогает ...
Двоичное квантование в векторных базах данных повы...
В этой статье вы узнаете от разработчиков компании...
Узнайте о преимуществах от разработчиков компании ...
Oracle — самая популярная база данных в мире...
Повысьте производительность и масштабируемость, ис...
Масштабирование через партиционирование, репликацию и шардинг (SQL и NoSQL)
В момент, когда даже корректно настроенный сервер баз данных на достаточно мощном железе уже недостаточно хорошо справляется с нагрузками, производится масштабирование при помощи партиционирования, репликации и шардинга. Далее рассмотрим эти способы увеличения производительности СУБД.
Описанные ниже схемы масштабирования применимы как для реляционных баз данных, тах и для NoSQL‑хранилищ. Разумеется, что у всех баз данных и хранилищ есть своя специфика, поэтому мы рассмотрим только основные направления, а в детали реализации вдаваться не будем.
Репликация (replication)
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие серверы часто называют мастерами (master), а ведомые серверы — слэйвами (slaves), иногда используются и другие названия — лидер и фолловеры (leader & followers), праймари и реплики (primary & replicas). Один ведущий узел (мастер, лидер, праймари) принимает запросы как на запись, так и на чтение, а ведомые (реплики, слейвы или фолловеры) синхронизируются с ним и обслуживают только запросы на чтение.
Ведущие серверы используются для чтения и изменения данных, а ведомые — только для чтения. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб‑проектов операций чтения на несколько порядков больше, чем операций записи, поэтому масштабировать систему целесообразно в направлении увеличения производительности запросов на чтение и схемы с несколькими слейвами с этим отлично справляются. Однако в более сложных схемах репликации может быть и несколько мастеров.
Репликация бывает синхронной и асинхронной. При синхронной репликации как минимум один слейв должен быть на 100% актуален, а при асинхронной — допустима некоторая задержка в репликации данных от мастера к слейвам. Таким образом, при асинхронной репликации мы получаем высокую скорость работы, но при выходе из строя мастер‑сервера вероятна потеря некоторого количества данных. Синхронная же репликация предусматривает, что транзакции подтверждаются мастером только после записи на заданное количество слейвов — в итоге получается крайне высокая согласованность данных, но низкая производительность. Подробнее про этот выбор между быстродействием и согласованностью — см. PACELC‑теорема.
С практической точки зрения, создание нескольких дополнительных slave‑серверов позволяет снять с основного сервера нагрузку по запросам на чтение и повысить общую производительность системы, а также можно организовать слэйвы под конкретные ресурсоёмкие задачи и таким образом, например, упростить составление серьёзных аналитических отчётов — используемый для этих целей slave может быть нагружен на 100%, но на работу других пользователей приложения это не повлияет. Если нужна максимальная надёжность и сохранность данных при адекватной производительности, то обычно достаточно реализовать синхронную репликацию на 1-2 слэйва при большем их количестве в общем.
Партиционирование (partitioning)
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. По сути, это разделение таблицы на логические части (партиции) для ускорения запросов и управления большими объемами данных. Партиционировать таблицы можно горизонтально (на уровне строк, например, через разделение на партиции по диапазонам значений) и вертикально (на уровне столбцов, например, через вынесение редко используемых полей в отдельную таблицу). В результате будет ускорение запросов за счет работы с меньшими объемами данных и упрощения управления информацией (в частности, при архивации старых партиций или при разделении данных на «горячие» и «холодные»).
Например, на новостных сайтах имеет смысл партиционировать записи по дате публикации, так как свежие новости на несколько порядков более востребованы и чаще требуется работа именно с ними, а не со всех архивом за годы существования новостного ресурса.
Шардинг (sharding)
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных. По сути, это горизонтальное разделение данных между независимыми базами (шардами), которые могут находиться на разных серверах
Стратегии шардинга могут отличаться в зависимости от задач. Ключевой шардинг (Key-Based) — данные распределяются по шардам посредством хэш‑функции или через остаток от деления (например, user_id % N). Диапазонный шардинг (Range-Based) — шарды хранят данные из определенных диапазонов (например, пользователи A–M, N–Z). Географический шардинг — данные хранятся ближе к пользователям (шард для РФ, шард для ЕС, шард для США).
Например, в системах типа социальных сетей ключом для шардинга может быть ID пользователя, таким образом все данные пользователя будут храниться и обрабатываться на одном сервере, а не собираться по частям с нескольких.
Использование репликации, шардинга и партиционирования
Репликация, партиционирование и шардинг — взаимодополняющие технологии, их выбор зависит от требований к масштабируемости, отказоустойчивости и производительности.
Репликация на практике используется наиболее часто. Благодаря ей достигается отказоустойчивость и масштабируются запросы на чтение, которых сильно больше почти во всех прикладных системах. Сочетание репликации с шардингом позволяет масштабировать крупные системы, обеспечивая при этом отказоустойчивость.
Партиционирование и шардинг используются относительно реже. Обе этих техники ускоряют выполнение запросов внутри одной партиции / шарда, так как количество обрабатываемых данных внутри отдельной партиции или отдельного шарда меньше, нежели их общее количество. Шардинг также позволяет горизонтально масштабироваться и повышает устойчивость к сбоям — падение одного шарда приводит к деградации сервиса, но не к падению всей системы.
Стоит помнить, что репликация и шардинг (как вместе, так и по отдельности) превращают систему в распределённую, поэтому при разработке надо учитывать ограничения по теореме CAP: нельзя одновременно гарантировать согласованность данных (C — consistency), доступность (A — availability) и устойчивость к фрагментации (P — partition tolerance). В лучшем случае можно получить только два свойства из трёх перечисленных. В финтехе, например, обычный выбор — C+P, а в системах с менее значимой информацией — A+P.
С практической точки зрения, репликация бывает полезна для проектов любого масштаба, где нужна отказоустойчивость и высокая сохранность данных. Наличие реплики позволяет сохранить данные и быстро восстановить работоспособность сервиса даже при полной потере мастера. Масштабирование под нагрузку обычно тоже первоначально производится при помощи репликации БД, реже — через партиционирование. Шардинг же обычно рационально использовать только в достаточно крупных системах с очень большим количеством данных.
Быстродействие зависит как от производительности серверного оборудования, так и от качества кодовой базы клиентской и серверной частей приложения. Качество бэкенд‑разработки и используемого хостинга определяет скорость обработки запроса пользователя и время до предоставления ответа. Качество фронтенд-разработки определяет скорость загрузки интерфейса и время, необходимое для перехода веб‑интерфейса к готовности для взаимодействия.
Быстродействие бэкенда и хостинга
Основной показатель производительности бэкенда и хостинга — это время генерации страницы: интервал времени, который необходим, чтобы сервер принял запрос, обработал его и сформировал ответ. Ключевой метрикой тут является Time to First Byte (TTFB) — время от запроса до получения первого байта данных.
В плане используемых платформ наиболее высокие показатели демонстрируют сайты, написанные на базе фреймворков, а сайты на базе CMS обычно чуть более медленные. Однако, во многом скорость работы сайта зависит еще и от уровня квалификации разработчика.
В плане хостинга наиболее быстрыми являются сайты, расположенные на физических выделенных серверах, затем следуют VPS и облачные системы, а самые низкие показатели демонстрируют сайты на виртуальном хостинге.
Для повышения быстродействия на уровне бэкенда и хостинга производится оптимизация программного кода (ускорение и упрощение обработки данных, оптимизация алгоритмов), настройка кеширования («запоминание» результатов вычислений и их многократное использование) и смена серверного оборудования на более производительное.
Повышение быстродействия благотворно сказывается на устойчивости сайта к высоким нагрузкам — чем быстрее приложению удаётся обработать каждый отдельный запрос, тем больше запросов за единицу времени может быть обработано и тем больше пользователей одновременно может работать с приложением.
Быстродействие фронтенда
Основные метрики — объём передаваемых данных и среднее требуемое время до возможности взаимодействия с интерфейсом.
На уровне фронтенда определяется необходимый объём данных, который требуется загрузить в браузер, чтобы приложением можно было полноценно пользоваться. Здесь важна целесообразность загрузки ресурсов, их минификация и оптимизация, а также настройка клиентского кеширования. Положительно на скорость загрузки влияет использование современных форматов изображений (WebP, AVIF), декомпозиция приложений с помощью модулей JS и применение tree-shaking для JavaScript-бандлов. Также полезен переход на серверный рендеринг (SSR) для приложений, которые используют клиентский рендеринг (CSR) — SSR + регидрация на клиенте обеспечивает более быструю отрисовку, а также сокращает время до интерактивности (Time To Interactive, TTI).
На время до интерактивности влияет как требуемый объём загрузки ресурсов, описанный выше, так и сложность DOM‑дерева для отрисовки и ресурсоёмкость клиентских подпрограмм на JavaScript. Упрощение процесса отрисовки и оптимизация JS‑скриптов в сочетании с возможностями ленивой загрузки компонентов (или загрузки по требованию) позволяет сократить время, требуемое для готовности клиентской части веб‑приложения к взаимодействию с пользователем.
Рекомендации по быстродействию
Относительно нормальным показателем времени генерации сложной страницы сайта является 0.1-0.5 секунд — это показатель вполне достижим на любой коробочной CMS. Если страницы сайта генерируются более 0.5 секунды, то это может вызывать дискомфорт пользователей и вам стоит рассмотреть варианты оптимизации производительности серверной части.
Если вы только создаёте сайт или новое веб‑приложение, то перед стартом проекта сформулируйте перед разработчиками требования к быстродействию системы — для достижения высоких показателей (генерация страниц менее чем за 0.1 секунды) обычно требуется использовать подходящие платформы и особые подходы к архитектуре приложения.
Обязательно оптимизируйте не только время ответа бэкенда приложения, но и клиентскую часть. Не грузите лишнее, используйте минификацию ресурсов и клиентское кеширование. В разработке интерфейсов по возможности используйте отложенную загрузку и загрузку по требованию.
Оптимальное время полной загрузки страницы на сегодняшний день — 2-3 секунды. Для сложных веб‑приложений допустимо ≤ 5 секунд, но только при условии визуальной индикации процесса загрузки. Помните, что воспринимаемое быстродействие — это субъективный показатель: если пользователь получает обратную связь от интерфейса в процессе обновления, то он значительно позитивнее воспринимет даже относительно длительные интервалы загрузки.
Быстродействие — это важно
Воспринимаемая пользователями скорость работы — это всегда сумма скоростей работы бэкенда и фронтенда. Необходимо работать как над повышением скорости генерации страниц, так и над сокращением объёма загружаемых данных и над ускорением отрисовки интерфейса. А работа над UI/UX позволяет улучшить клиентский опыт даже в тех случаях, когда пользователям приходится немного подождать.
Статические ресурсы должны иметь хотя бы недельное время жизни кеша, а лучше кешировать их сразу на год. Таким образом, эти ресурсы будут только один раз скачиваться с сервера, а затем браузер будет либо сразу использовать локальную копию (если указан заголовок Expires или Cache-Control), либо после проверки на неизменность (если указан заголовок Last-Modifed или ETag).
Заголовки Expires и Cache-Control: max-age
В качестве значения у этих заголовков используется дата. До тех пор, пока она не настала, браузер будет без каких‑либо дополнительных проверок использовать закешированную версию ресурса. Expires поддерживается чуть шире, чем Cache-Control: max-age, поэтому лучше использовать именно его.
Заголовки Last-Modifed и ETag
В качестве значения заголовка Last-Modifed используется дата, а для заголовка ETag — произвольная строка. Если используются эти заголовки, то браузер, прежде чем использовать закешированный ресурс, получит с сервера текущее значение заголовка и сравнит его с заголовком закешированной версии — если данные совпадут, то будет использоваться локальная версия, а если нет — произойдёт повторная загрузка. Запросы проверки происходят быстрее, чем полная загрузка ресурсов, что даёт прирост производительности сайта при повторном использовании ресурсов.
Оптимальная стратегия клиентского кеширования
Для редко меняющихся файлов стоит поставить Expires на дату, которая наступит через год, а в момент изменения этих ресурсов использовать метод «отпечатков пальцев» (fingerprinting) — добавлять к имени файла небольшую часть хеша, которая фомируется на основе его содержания. Таким образом, вся статика всегда закеширована на клиенте, а при изменении этой самой статики меняются имена файлов и они автоматически перезагружаются браузером.
Собственно техника fingerprinting активно используется для статичных ресурсов (стилей и скриптов) во многих фреймворках (в частности, в Ruby on Rails). А массовую простановку для всех типов статичных файлов заголовка Expires можно реализовать на стороне веб‑сервера (в nginx, например).
Бывает так, что некоторое содержание страницы нужно не всем или не всегда, но на генерацию этого материала или для его передачи тратится много ресурсов. В этом случае имеет смысл сделать загрузку «ленивой», то есть не генерировать и не загружать в браузер информацию до тех пор, пока она не понадобится.
Реализуется ленивая загрузка при помощи AJAX и инициируется событиями, отслеживаемыми при помощи JavaScript. То есть для работы методики необходима поддержка JS браузером, то есть перед тем, как применить ленивую загрузку, стоит знать, что пользователи без JS воспользоваться функцией не смогут, а поисковые роботы скрытый таким образом контент скорее всего не увидят (или увидят отдельные страницы, с которых этот контент браться будет).
Разновидности ленивой загрузки:
— Загрузка «по клику» — например, раскрывающийся текст по ссылке «показать больше» или «подробнее», справочная информация в модальных окнах или загрузка большого изображения при нажатии на миниатюру. Это наиболее распространённый способ для представления контента, который с не очень высокой вероятностью заинтересует пользователя. В случае, если контент скорее всего заинтересует или текст важен для поисковых систем, а цель скрытия — экономия пространства, то лучше реализовывать функциональность не на AJAX, а на простом JS — загружать сразу, но отображать по требованию.
— Загрузка «при скроллинге» — загрузка следующей партии материалов в тот момент, когда пользователь уже почти ознакомился с изначально загруженным содержанием. Этот способ ленивой загрузки используется в социальных сетях («бесконечные» ленты новостей), но также применим для интернет-магазинов, каталогов и сайтов СМИ. В случае «бесконечных» лент стоит помнить о доступности навигации: нужна либо фиксированная панель меню, либо кнопка «наверх».
— Фоновая загрузка «по времени» — если страница уже загружена, а пользователь остаётся на открытой странице сайта, то можно в фоновом режиме загрузить какие‑либо ресурсы (большие изображения, например), которые понадобятся ему при дальнейшей работе с сайтом. Метод может ускорить сайт, если загружать действительно необходимые при дальнейшей работе материалы, но требует осторожного применения — необходимо знать, что именно загружать (это можно определить на основании статистики посещений, например), а также учитывать скорость доступа посетителя к сети интернет (пользователь медленного мобильного интернета не будет вам благодарен за такую «заботу»).