

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Преимущества синтетических данных для тестирования, соответствия и генеративного ИИ

Примечательно, когда Microsoft и другие говорят о новых подходах и стандартах. Одним из примеров является то, как дифференциальная конфиденциальность и синтетические данные предпочитают для конфиденциальности и соблюдения данных. В этой статье разработчиками компании DST Global рассматривается, как используются синтетические данные, и преимущества, направляющие переход к синтетическим данным для конфиденциальности и соблюдения данных.
Смоделированные синтетические данные обеспечивают превосходную конфиденциальность данных
Microsoft и другие обращаются к синтетическим данным для превосходной конфиденциальности данных и удобства использования. Поскольку смоделированные синтетические данные могут выглядеть и вести себя как исходные данные, отражая распределение исходных данных. Полученный набор данных защищен конфиденциальностью и поддерживает точность, необходимую в инициативах машинного обучения и ИИ. Простая маскировка данных и анонимизация больше не считается наилучшей практикой.
Другим драйвером для синтетических данных является возникающий спрос на генеративный ИИ и необходимость в высоких объемах корпоративных текстовых данных для получения добычи из поиска (RAG). Поддержка билетов, документов Word и другие текстовые данные сканируются для идентификации личной информации (PII), которая либо отредактирована, либо заменена с помощью конфиденциальности, защищающих синтетические данные. Этот процесс создания озеро защищенного конфиденциальности является основополагающим для предприятий, занимающихся генеративными решениями искусственного интеллекта. Озеро Data проходит для создания авторитетного набора бизнес -знаний для поддержки извлечения дополненного поколения (RAG), что, в свою очередь, дополняет крупные языковые модели для решений искусственного интеллекта для бизнеса.
Синтетические данные для генеративного ИИ
Предприятия должны быть знакомы с требованиями конфиденциальности данных, такими как GDPR и Закон о конфиденциальности GDPR и Калифорнии, и защита информации в базах данных была легко доступна за последнее десятилетие или более. Новая задача заключается в том, как защитить текстовые данные, которые сейчас востребованы для генеративного ИИ?
Большие языковые модели (LLMS) основаны на широко доступном и публичном тексте, а предприятия добавят ценность авторитетной базой знаний, основанной на документах частных предприятий (поддержка билетов, документы Word и т. Д.). Эти документы отражают знания в контексте и включены в генеративный ИИ путем создания получения добычи (RAG).
Генеративное решение AI на основе RAG включает текстовые данные, включая билеты на поддержку, каталоги продуктов, в документах House Word, PDFS и других источниках. Эти данные должны быть очищены от личной информации (PII), так как данные PII не могут быть просочены к клиенту, обращенному к генеративному приложению ИИ!

Векторная база данных становится авторитетной базой знаний и запрашивается LLM в реагировании на подсказки клиентов. Этот генеративный ИИ, основанный на тряпке, является самым популярным подходом к ИИ предприятия.
Генеративный ИИ, основанный на тряпке, является наиболее распространенным подходом к генеративному ИИ предприятия. Генеративный ИИ быстро развивается, и одна область, которая привлекает внимание,-это необходимость в практически в реальном времени, которая обычно хранится в базах данных. Различные методы включения реляционных данных включают структурирование генеративного приложения ИИ для исходных данных с помощью запросов SQL или определение конкретных запросов в векторной базе данных, чтобы искать явно связанные данные для доставки через генеративное приложение AI.
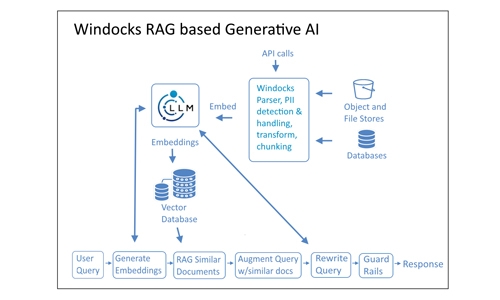
Это изображение иллюстрирует поток информации от необработанных документов до информации, которая может быть извлечена из приложения на основе LLM.
Ключевые преимущества синтетических данных
Смоделированные синтетические данные смотрят и ощущаются как исходные данные
Маскированные и анонимные данные включают замену первичных идентификаторов, таких как «Джон Смит», замененный «Тоби Джонс». Полученные данные являются анонимизированными, но не отражают межколонные корреляции, такие как возраст с доходом, географическое распределение и другие нюансы исходных данных.
Моделированные синтетические данные отражают распределения исходных данных, заполняя конфиденциальные данные значениями, которые выглядят как источник. Результатом является более высокое качество и полезность в защищенных данных, которые можно использовать для аналитики или использовать для увеличения наборов данных машинного обучения с высокой точностью данных.
Синтетические данные обеспечивают гарантированную конфиденциальность и соответствие данных
Маскированные и анонимные базы данных подлежат атакам сцепления, где анонимные данные соединены с другим набором данных для повторных идентификаторов. Существует много примеров атак сцепления, в том числе данных о здравоохранении, и даже публичный конкурс, включающий рекомендации фильма Netflix.
Чтобы избежать этих проблем, Microsoft, Amazon и другие обращаются к синтетически заполненным данным с дифференциальной конфиденциальностью для математически гарантированной конфиденциальности данных. Дифференциальная конфиденциальность - это математическое решение, которое включает в себя достаточный шум в результатах запроса, чтобы гарантировать, что ни один человек не может быть идентифицирован из синтетически заполненного набора данных.
Точность синтетических данных необходима для машинного обучения и генеративного искусственного интеллекта на основе Generative AI
Соответствие данных с GDPR, CCPA и другими правовыми стандартами не ограничивается табличными и реляционными данными, но включает в себя личные данные в билетах поддержки, текстовых файлах, документах, PDF и журналах. Современные растворы синтетических данных считывают и обнаруживают конфиденциальные текстовые данные в ведрах S3, Blobs Azure и хранилищах файлов, и либо отредактируют, либо заменяют конфиденциальные данные синтетическими данными.
Стратегия конфиденциальности синтетических данных, применяемая к документам и базам данных, является наилучшей практикой для конфиденциальности и соответствия, но также поддерживает бизнес -императив для защищенных конфиденциальности данных для разработки крупных языковых моделей (LLMS) и генеративного искусственного интеллекта.
Преимущества синтетических данных для тестирования, соответствия и генеративного ИИ
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Интеграция LLM повышает эффективность, автоматизирует рабочие процессы и улучшает качество принимаемых решений, но успех зависит от стратегии, исполнения и соответствия бизнес-целям.До недавнего време...
Распределенные системы искусственного интеллекта выходят из строя быстрее, чем л...
Использование средств генеративного искусственного...
Периферийный искусственный интеллект (Edge AI) сег...
Современные ИИ-агенты для программирования —...
Многие решения на базе искусственного интеллекта д...
Искусственный интеллект (ИИ) и машинное обучение (...
В настоящее время ИИ использует разнообразные типы...
В этой статье рассматривается LLMOps, принцип его ...
Представьте идеального инженера технической поддер...
Синтетические данные — это данные, которые генерируются с помощью алгоритмов, имитирующих реальные процессы. Такие данные могут представлять собой цифровую “копию” или “модель” поведения и характеристик окружающей среды, не прибегая к реальным источникам.
Зачем нужны синтетические данные?
Основное назначение синтетических данных — восполнить недостаток реальных данных, особенно в случаях, когда их сбор осложнен из-за вопросов конфиденциальности, высокой стоимости или соображений безопасности. Например, в таких сферах, как:
• Беспилотные автомобили: чтобы обучить ИИ, отвечающий за автономное вождение, необходимо множество сценариев дорожного движения. В реальной жизни собрать такой объем данных сложно, а вот синтетические данные могут смоделировать нужные ситуации.
• Финансовая аналитика: создание моделей ИИ, анализирующих и предсказывающих изменения в финансах, требует больших массивов данных, которые зачастую защищены законодательством или коммерческой тайной.
• Медицина: в сфере здравоохранения использовать реальные данные пациентов зачастую невозможно из-за конфиденциальности, но синтетические данные могут помочь ИИ, моделируя необходимые медицинские сценарии.
Кроме того, синтетические данные могут помочь снизить предвзятость, часто присутствующую в реальных датасетах, что улучшает качество и объективность моделей ИИ. Они создаются по запросу, быстро и практически без ограничений по объему, обеспечивая нужное разнообразие для более точной работы ИИ.
Кто использует синтетические данные?
Сегодня многие лидеры технологий и автомобильной промышленности активно используют синтетические данные для обучения своих моделей. Примеры таких компаний:
• Meta: новая языковая модель Llama 3.1 использует синтетические данные для решения задач, связанных с программированием и математикой.
• Toyota и Waymo: используют синтетические данные для тренировки и тестирования своих моделей в области автономного вождения.
• Amazon: применяет синтетические данные в анализе и разработке своих продуктов.
• Microsoft и Google: малые языковые модели, такие как Phi (Microsoft) и Gemma (Google), частично обучены на синтетических данных, что позволяет этим ИИ-системам решать широкий спектр задач.
• Nvidia: недавно выпустила модель Nemotron-4 340B Instruct, которая генерирует синтетические данные, имитируя реальные характеристики, что делает ее универсальной для различных исследований и задач.
Риски и вызовы использования синтетических данных
Однако, несмотря на явные преимущества, синтетические данные несут и определенные риски. Проблемы с качеством, возникающие из-за генерации только алгоритмами, могут привести к так называемым «галлюцинациям» — когда модель делает ошибочные предположения, а порой и вовсе выдаёт неправильные результаты. Это может стать причиной серьезных сбоев в работе ИИ и снизить его эффективность.
Чтобы снизить эти риски, разработчики внедряют тщательную проверку синтетических данных и комбинируют их с реальными — так называемые гибридные данные. Этот подход позволяет улучшить качество модели, оставаясь при этом в рамках требований к конфиденциальности и безопасности.
Синтетические данные — это инновационное решение, которое может обеспечить непрерывное развитие ИИ, несмотря на дефицит реальных данных.
Тем не менее, данные из реального мира подпитывает инициативы любой организации в области машинного обучения и искусственного интеллекта. Однако получение качественных обучающих данных для их проектов является сложной задачей. Это потому, что только несколько компаний могут получить доступ к потоку данных, в то время как остальные делают свой собственный. И эти самодельные обучающие данные, называемые синтетическими данными, эффективны, недороги и доступны.
Но что именно синтетические данные? Как бизнес может генерировать эти данные, преодолевать трудности и использовать свои преимущества?
Что такое синтетические данные?
Синтетические данные — это компьютерные данные, которые быстро становятся альтернативой реальным данным. Вместо того, чтобы собирать из реальной документации, компьютерные алгоритмы генерируют синтетические данные.
Синтетические данные искусственно генерируется с помощью алгоритмов или компьютерного моделирования, которые статистически или математически отражают данные реального мира.
Синтетические данные, согласно исследованиям, обладают теми же прогностическими свойствами, что и фактические данные. Он генерируется путем моделирования статистических закономерностей и свойств реальных данных.
Тенденции отрасли?
Согласно Gartner исследования, синтетические данные могут быть лучше для целей обучения ИИ. Предполагается, что синтетические данные иногда могут оказаться более полезными, чем реальные данные, собранные на основе реальных событий, людей или объектов. Эта эффективность синтетических данных объясняет, почему глубокое обучение разработчики нейронных сетей все чаще используют его для разработки высококлассных моделей ИИ.
В отчете о синтетических данных прогнозируется, что к 2030 году большая часть данных, используемых для модель машинного обучения в целях обучения будут использоваться синтетические данные, полученные с помощью компьютерного моделирования, алгоритмов, статистических моделей и т. д. Однако на синтетические данные в настоящее время приходится менее 1% рыночных данных, однако к 2024 ожидается, что на него будет приходиться более 60% всех генерируемых данных.
Зачем использовать синтетические данные?
По мере разработки передовых приложений ИИ компаниям становится все труднее приобретать большие объемы качественных наборов данных для обучения моделей машинного обучения. Тем не менее, синтетические данные помогают ученым и разработчикам данных преодолевать эти трудности и разрабатывать надежные модели машинного обучения.
Но зачем использовать синтетические данные?
Время, необходимое для генерировать синтетические данные намного меньше, чем получение данных из реальных событий или объектов. Компании могут получать синтетические данные и разрабатывать индивидуальные наборы данных для своего проекта быстрее, чем зависимые наборы данных из реального мира. Таким образом, в сжатые сроки компании могут получить аннотированные и помеченные данные о качестве.
Например, предположим, что вам нужны данные о событиях, которые происходят редко, или о событиях, для которых очень мало данных. В этом случае можно генерировать синтетические данные на основе выборок данных из реального мира, особенно когда данные требуются для крайних случаев. Еще одно преимущество использования синтетических данных заключается в том, что они устраняют проблемы с конфиденциальностью, поскольку данные не основаны на каком-либо существующем человеке или событии.
Дополненные и анонимные данные против синтетических
Синтетические данные не следует путать с дополненными данными. Увеличение данных это метод, который разработчики используют для добавления нового набора данных к существующему набору данных. Например, они могут сделать изображение ярче, обрезать его или повернуть.
Анонимизированные данные удаляет всю информацию личного идентификатора в соответствии с государственными политиками и стандартами. Поэтому анонимные данные очень важны при разработке финансовых моделей или моделей здравоохранения.
Хотя анонимизированные или дополненные данные не считаются частью синтетические данные. Но разработчики могут делать синтетические данные. Комбинируя эти две техники, например смешивание двух изображений автомобилей, можно разработать совершенно новый синтетический образ автомобиля.
Типы синтетических данных
Разработчики используют синтетические данные, поскольку это позволяет им использовать высококачественные данные, которые маскируют личную конфиденциальную информацию, сохраняя при этом статистические качества реальных данных. Синтетические данные обычно делятся на три основные категории:
1. Полностью синтетический
Он не содержит информации из исходных данных. Вместо этого компьютерная программа, генерирующая данные, использует определенные параметры из исходных данных, например плотность признаков. Затем, используя такую реальную характеристику, он случайным образом генерирует предполагаемую плотность признаков на основе генеративных методов, что обеспечивает полную конфиденциальность данных за счет их актуальности.
2. Частично синтетический
Он заменяет определенные значения синтетических данных реальными данными. Кроме того, частично синтетические данные заменяют некоторые пробелы, присутствующие в исходных данных, и специалисты по данным используют методологии на основе моделей для создания этих данных.
3. Гибридный
Он сочетает в себе как реальные данные, так и синтетические данные. Этот тип данных выбирает случайные записи из исходного набора данных и заменяет их синтетическими записями. Он обеспечивает преимущества синтетических и частично синтетических данных, сочетая конфиденциальность данных с полезностью.