

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
CatBoost и Матрикснет

Матрикснет – это алгоритм машинного обучения, разработанный в Яндексе и внедренный в 2009 году. Представляет собой градиентный бустинг на симметричных (oblivious) деревьях решений. Он используется не только для построения формулы, ранжирующей поисковую выдачу, но и для множества других задач: предсказание кликов на рекламу, обнаружение ботов, разрешение омонимии и даже определения размера вознаграждений сотрудникам. Алгоритм устойчив к переобучению, позволяет гранулированно настраивать полученную формулу (так, чтобы изменения в оценке одного класса объектов не оказывали влияние на оценку другого класса объектов). Летом 2017 года ему на смену пришел алгоритм CatBoost, поддерживающий обработку категориальных признаков.
В чем заключается принцип работы Матрикснет
Алгоритм матрикснет, по всей видимости, натравливается разработчиками на сайты, которые были высоко оценены асессорами, и на них учится вычленять какие-то незаметные взгляду человека факторы, которые свидетельствуют о высоком качестве сайта. Специалисты из Яндекса утверждают, что матрикснет позволяет корректировать формулу ранжирования сайта, делая выдачу более качественной для пользователя, на основании оценки меньшего числа сайтов, нежели требуется другим алгоритмам. Также утверждается, что количество оценок асессоров для корректной работы алгоритма матрикснет не увеличено по сравнению с другими алгоритмами. В компании Яндекс утверждается, что алгоритм матрикснет может корректировать алгоритмы ранжирования для каких-то областей. То есть определять факторы, специфические для, например, музыкальной сферы и включать их в формулу расчета сайтов, касающихся музыки. Тем самым конечный пользователь получает более точную выдачу по всем музыкальным запросам, но при этом такое специфическое вмешательство никак не затрагивает другие области. Например, если пользователь хочет послушать музыку, то логично выдавать ему вначале сайты, на которых композиции представлены в хорошем качестве (если о них вообще представлена информация). Но хорошее качество аудио файлов является специфичным для запросов по музыкальной теме. Если пользователь хочет почитать книжку или найти информацию про компьютеры, то качество аудио файлов на сайте учитываться поисковиком уже не будут.
Итак, это алгоритм, работающий уже пять лет, который позволяет более точно ранжировать сайты, используя меньшую выборку сайтов для самообучения. Этот алгоритм также позволяет настроить формулу расчета индекса для какой-то отдельной области, не затрагивая при этом остальных. Приведем официальную информацию от Яндекса. В нижеприведенном видео это начинается на 10-й секунде 15-й минуты.
«На самом деле Матрикснет – это целая совокупность различных методов машинного обучения, но все они так или иначе используют алгоритм под названием Gradient Boosted Regression Trees (GBRT)».
Кроме того, про Матрикснет хорошо и подробно было рассказано в феврале 2017 года.
Матрикснет – это «целая совокупность разных методов машинного обучения, но все они так или иначе используют алгоритм под названием Gradient Boosted Regression Trees (GBRT)», по официальной информации Яндекса на август 2016 года. Матрикснет был выпущен в 2009 году. «Что это такое? Это множество решающих деревьев, которые подобраны таким образом, чтобы суммируя значения в листьях этих деревьев, мы бы получили хорошее предсказание оценки релевантности, которую поставил ассесор. В узлах дерева расположены разделяющие условия, которые представляют собой приблизительно такое: фактор №50 больше, чем 0,5 или меньше? Если больше, то мы идем налево, а если меньше, то направо. И строим такие вот деревья глубиной чуть больше, чем на рисунке, и в листьях такие числа подбираем, что если множество таких деревьев просуммировать, мы бы получили хорошее предсказание ассесорской релевантности».
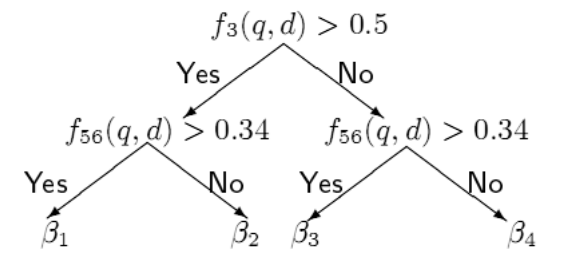
Уже в феврале 2017 года появилась более полная и более свежая информация. Подтвердилась информация о том, что матрикснет – это градиентный бустинг на деревьях решений. Оказалось, что он применяется в Яндексе практически повсеместно, даже в определении размеров денежных премий.

Еще раз про то, как выглядит суммирование деревьев решений

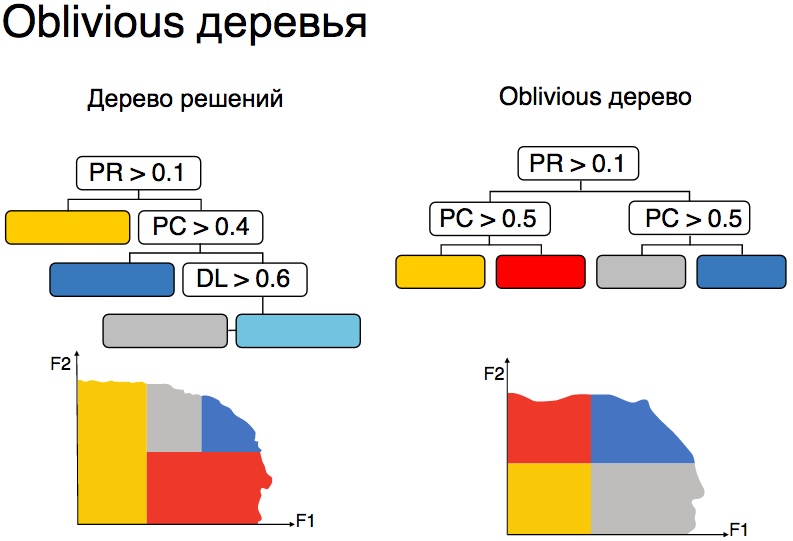
В Матрикснете используются не обычные, а так называемые oblivious-деревья решений. «Oblivious-дерево – это такое дерево, где на каждом уровне находятся разбиения по одному и тому же признаку и и одному и тому же числу». Почему используются именно такие деревья?
Модель на таких деревьях оказывается устойчивой к переобучению: очень много таких деревьев можно сложить.
Для вычисления листового значения нужно вычислить значения всех разбиений («сплитов»), значит не важно в каком порядке мы будем это делать. Это используется для оптимизации применения и обучения.
«Oblivious-дерево эквивалетно табличке просто».
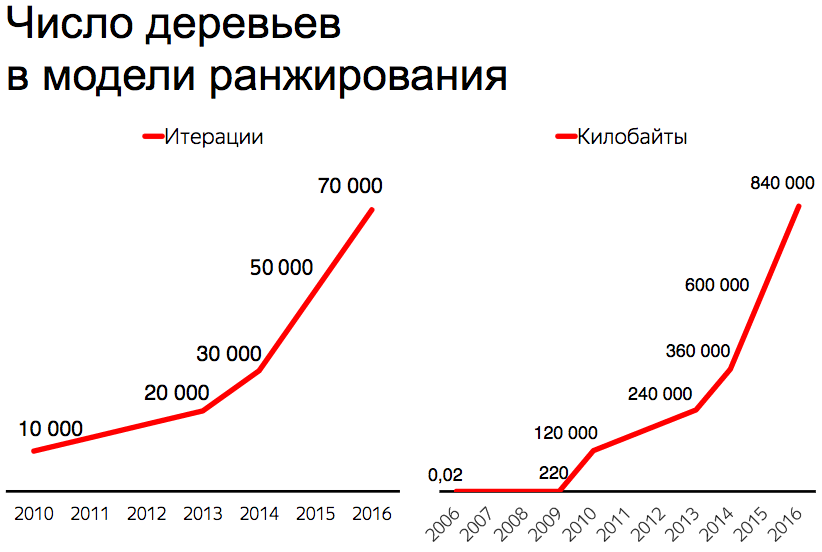
Рассмотрим, как велика формула ранжирования Яндекса: сколько в ней деревьев решений и сколько байт она занимает. Как видим, в настоящий момент в формуле суммируется более 70 000 деревьев решений, «весит» формула 840 мегабайт.
Что дает введение Яндексом матрикснета для пользователя
Пользователь, как и задумывалось, от этого выигрывает, поскольку получает более качественную выдачу. Также пользователь, задающий вопросы по каким-то узким сферам также доволен, поскольку алгоритм матрикснет занимается усовершенствованием формулы ранжирования не только широких и общих запросов, но и нишевых запросов по узким темам, так что все специалисты по коллекционированию лютневой музыки шестнадцатого века просто счастливы.
Вот иллюстрация возможности тонкой настройки матрикснета:
Матрикснет и seo. Какие можно сделать выводы для оптимизаторов
Итак, основные выводы, которые можно сделать из тех знаний о марикснете, которые сообщает Яндекс это то, что алгоритмы оценки постепенно превращаются в скайнет из просто анализаторов легкоманипулируемых внешних факторов продвижения сайтов во все более продуманному, детализированному ранжированию и оценке сайтов.
В сущности, это означает, что пора переходить к максимально честным и рекомендованным способам продвижения сайтов. Даже если Вы не знаете всего, что приведет к высоким местам в рейтинге, то главное помнить, что любой сайт – это площадка для того, чтобы доносить какую-то информацию до пользователя, а это значит, что сайт должен быть удобен пользователю и нести ему полезную информацию. Если Вы руководствуетесь этим принципом, то вероятность того, что Ваш сайт забанят приближается к нулю. Если же сайт сделан ради того, чтобы повесить кучу рекламы, содержит мало информации по теме, а вся информация – слегка переделанная копипаста из Википедиии или любых каких-нибудь других источников, то такой сайт очень быстро вылетит из индексации, его тИЦ обнулится и так далее и тому подобное. Сейчас одноходовки с раскручиванием сайта левым методом прокатывают все хуже и хуже, а через несколько лет вообще перестанут прокатывать.
Сейчас при раскрутке сайта и поднятии его в поисковой выдаче следует обращать и уделять внимание таким внутренним факторам как тексты статей. Они должны быть написаны энциклопедичным стилем, википедия-стайл, так сказать. Статьи должны подробно и с разных сторон раскрывать тот предмет, который они описывают. Поскольку развитие поисковых фильтров пошло по обучению их семантическому анализу текстов, то написание копирайтерских продающих, нахваливающих продукт статей не поможет. Это только потратит время, деньги, а пользы принесет, но не очень много.

Итак, вот небольшой список того, на что следует обратить внимание:
Качественные статьи
Перелинковка
Соотношение статей по ширине запроса. Это раскрывается более подробно здесь.
В качестве вывода можно посоветовать стараться делать честные нужные и интересные людям сайты.
CatBoost приходит на смену Матрикснету
CatBoost – это алгоритм градиентного бустинга на решающих деревьях с поддержкой категориальных признаков. Категориальными назваются признаки, представляющие собой наименование чего-либо: пород собак, разных видов облаков и так далее. Говоря более формально, можно сказать, что это признаки, представленные в шкале наименований в терминологии так называемой теории измерений.
В чём сложность использования категориальных признаков? Казалось бы, их можно достаточно просто заменить числами и работать уже с ними. Однако здесь есть подводные камни: таким образом мы передаем алгоритму машинного обучения дополнительные и в реальности не существующие отношения между признаками, и алгоритм, основываясь на них может найти несуществующие закономерности и тем самым исказить конечный результат. Например, категориальным признаком может быть наименование товара в интернет-магазине. Его легко заменить неким идентификатором товара, численное выражение которого никак не связаны ни с природой товара, ни с закономерностями, ему присущими. Но алгоритм машинного обучения этого не знает, и если идентификатор масла больше айдишника сапогов в 37 раз, он учтет это в расчетах, и это уж точно не улучшает конечного результата. Существуют различные методы предварительной обработки категориальных признаков, чтобы свести описанный эффект к минимуму. Каждый из них имеет свои достоинства и недостатки. Разработчикам Яндекса, по-видимому, удалось подобрать такую комбинацию приемов, которые оптимальным образом переводят такие признаки в числа, и пользователю уже не нужно об этом заботиться.
«Представим себе категориальную переменную, например, тип облаков, которые могут быть кучевые, перистые и так далее. Каждый из этих типов мы хотим каким-то образом заменить на число. Как это можно сделать? Мы можем использовать простые счетчики, но на самом деле они не очень хорошо работают, потому что приводят к переобучению: происходит утечка данных и модель «запоминает» свою обучающую выборку, свой пример. Давайте не будем его ей показывать! Сделаем leave-one-out: для расчета счетчика на каждом объекте обучающей выборки не будем использовать его самого, будем смотреть только на все остальные примеры. Так утечка информации будет меньше, но в конце концов это тоже не работает: рано или поздно модель все равно запомнит свою обучающую выборку и переобучится. Еще, конечно, можно делать leave-bucket-out. Это такое обобщение leave-one-out, когда мы смотрим на все, кроме некоторой группы. К сожалению, это тоже работает не лучшим образом, и опять по тем же причинам.
И тогда мы придумали вот что: давайте скажем, что у нас есть некоторый аналог «времени», как в физике, и расставим данные «по времени». И для каждого объекта обучающей выборки будем рассчитывать наш счетчик так, чтобы модель обучалась только по «прошлым» данным, не подглядывая «в будущие». Вот тогда наша модель сработает, будет происходить гораздо меньше утечек, модель меньше переобучится. А дальше мы будем улучшать это решение: будем делать эту случайную перестановку и упорядочивание по времени не один раз, на подготовительном этапе (так, кстати, сейчас делает кагглеры), а сколько-то раз в течение всего обучения. Или мы можем попробовать считать счетчики не по одному признаку, а по нескольким... Ну и много еще тонких приемов есть. Или вот, что делать, если у нас не задача классификации, а задача регрессии, или ранжирования, или мультиклассификации. Мы попробовали много разных подходов, выбрали из них хорошо работающие, внедрили в алгоритм, и теперь регрессия у тебя, или классификация, или мультиклассификация — ты просто отдаешь свои категориальные признаки, а алгоритм сам за тебя их считает наилучшим способом. То есть мы не просто выбрали или придумали лучшие на сегодняшний день подходы, но и автоматизировали их применение. Какая бы задача ни была у пользователя, CatBoost сам выберет наилучший метод».
Что же переход на CatBoost значит для поискового ранжирования? По-видимому, оно станет еще лучше, так как, очевидно, что многие из факторов ранжирования – категориальные признаки, по сути. Сейчас они будут обрабатываться еще лучше, а формула ранжирования станет еще точнее и защищенней от манипулирования. Из этого следует очевидный вывод для поискового продвижения: стоит делать еще больший упор на «белые» методы продвижения.
CatBoost и Матрикснет
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Рынок Китая открывает огромные возможности для российского бизнеса. Это самая крупная и развивающаяся экономика в мире, а значит — огромная армия потенциальных покупателей. 731 миллион китайцев ...
Выход на китайский рынок и начало рекламной кампании в Китае сопровождаются множ...
Один из самых важных элементов в SЕО оптимизации -...
Постепенно CatBoost заменит «Матрикснет» во всех продуктах компании
Давайте по порядку. На расцвете поисковиков, например, того же Яндекса, не было сложных алгоритмов ранжирования. Интернет был по карману только обеспеченным слоям общества, запросы которых вместе с требований к интернету были вполне приемлемы. Забили запрос, получили ответ и нормально.
Перемотаем ленту лет так на 10 вперед… Интернет уже особо не роскошь, количество пользователей существенно выросло, а вместе с ними количество запросов и предложений. Сайтов стало очень много и стандартные алгоритмы поисковиков просто перестали справляться с таким наплывом сайтов и нечестных вебмастеров, которые использовали серые схемы продвижений.
В помощь пришли искусственные нейронные сети, которые помогли анализировать и фильтровать информацию, для выдачи максимально релевантного содержимого по запросу пользователя. И В ноябре 2009 года выходит новый алгоритм Яндекса под названием Матрикснет. Это принципиально новый подход к оценке сайтов и построению поисковой выдачи, в основе которого лежит самообучающийся алгоритм с элементами искусственного интеллекта.
До введения Матрикснета компьютеры обрабатывали информацию алгоритмическим подходом
Алгоритмический подход отлично подходит для решения огромного круга задач. Это и поиск, и различные вычисления, да и все «бытовые» компьютерные программы, которыми мы пользуется, построены на основе алгоритмов. И безусловно, компьютер работает в миллионы раз быстрее человека.
В то же время существует ряд трудных задач, с которыми человек справляется просто и естественно, а машине они не под силу. Мы легко можем узнать знакомого нам человека, встретившись на улице или даже со спины, по походке, по интонации в голосе. Никакими алгоритмами эта задача не решаема.
Тут и пришел на помощь Матрикснет с использованием нейронных сетей
Говоря о нейронных сетях, можно привести аналогию с человеческим мозгом, который состоит из огромного числа нейронов, каждый из которых в отдельности разумом не обладает и способен лишь на самые элементарные действия. Но объединенные вместе они представляют удивительную силу.
Нейронные сети построены по тому же принципу. Множество простых «вычислительных элементов», объединенных в единую структуру.
Долгое время в Яндекс основным алгоритмом машинного обучения был Матрикснет, но сейчас на смену ему пришел CatBoost и дело здесь вовсе не в котиках.
А в чем тогда дело?
CatBoost остается все тем же градиентным бустингом, то есть методом, в котором строится серия очень слабых алгоритмов (в данном случае — решающих деревьев), последовательно минимизирующих ошибку друг друга и в итоге, в комбинации, хорошо описывающих обучающую выборку данных. Однако в отличие от Матрикснет CatBoost изначально разрабатывался для того, чтобы наилучшим образом работать не только с числовыми, но и с категориальными признаками. Речь идет о тех признаках данных, которые не имеют числового выражения. Например, если вы классифицируете бытовую технику, то «энергопотребление» и «средняя цена» — это числовые признаки, ваша компьютерная модель может с ними работать (складывать, вычитать и так далее). Но признак «тип» (стиральная машина, телевизор, кофемолка) является категориальным, то есть для модели это просто слово, которое не несет никакой смысловой нагрузки. Чтобы его эффективно вставить в модель, этот признак надо сначала оцифровать, привести к численному виду.
Опытный специалист, работающий с машинным обучением, может придумать более интеллектуальный способ превращения категориальных признаков в числовые, однако такая предварительная предобработка приведет к потере части информации и приведет к ухудшению качества итогового решения.
Именно поэтому было важно научить машину работать не только с числами, но и с категориями напрямую, закономерности между которыми она будет выявлять самостоятельно, без ручной помощи. И CatBoost разработан так, чтобы одинаково хорошо работать «из коробки» как с числовыми признаками, так и с категориальными. Благодаря этому он показывает более высокое качество обучения при работе с разнородными данными, чем альтернативные решения. Его можно применять в самых разных областях — от банковской сферы до промышленности.
CatBoost на практике
Яндекс пока не применяет CatBoost в своих проектах полноценно, но разработчики уже провели тестирование технологии, и она показала свою состоятельность.
И кстати, ранее Яндекс никогда не предоставлял сторонним разработчикам прямого доступа к алгоритму Матрикснет. Они могли использовать Матрикснет лишь косвенно — через API других продуктов компании.
Но в этот раз CatBoost доступен на GitHub по открытой лицензии Apache. Алгоритм существует в виде библиотек для Python и R и максимально настроен для пользователей с малым опытом работы с машинным обучением. Так, в CatBoost есть встроенный алгоритм для обработки категориальных признаков в зависимости от типа данных и задачи, есть встроенный детектор переобучения (он сам остановит алгоритм на оптимальном количестве построенных деревьев), а исходные параметры подобраны таким образом, чтобы выдавать удовлетворительный результат даже без тонкой настройки. Отдельной особенностью CatBoost разработчики называют наличие встроенных инструментов для визуализации и анализа результатов.
Как начать использование CatBoost
Для работы с CatBoost достаточно установить его на свой компьютер. Библиотека поддерживает операционные системы Linux, Windows и MacOS и доступна на языках программирования Python и R. Яндекс разработал также программу визуализации CatBoost Viewer, которая позволяет следить за процессом обучения на графиках.
Однозначно можно сказать, что продвигать сайты станет сложнее. CatBoost рассчитан на то, чтобы максимально персонализироваться под интересы конкретного пользователя. А любая персонализация — это лишний стресс для веб-мастера.