

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Надежный обмен данными микросервисов с потоковой базой данных

В этой статье специалисты компании DST Global расскажут, как реализовать шаблон исходящих сообщений с потоковой базой данных, который может обеспечить надежное решение для микросервисов или обмена данными между несколькими сервисами.
В настоящее время мы обычно создаем несколько сервисов для работы одного продукта, а клиентские приложения должны использовать функциональные возможности более чем одного сервиса. Архитектура микросервисов стала популярным подходом к созданию масштабируемых и отказоустойчивых приложений. В системе на основе микрослужб несколько слабо связанных служб работают вместе, чтобы обеспечить желаемую функциональность. Одной из ключевых проблем в таких системах является надежный и эффективный обмен данными между микросервисами. Одним из шаблонов, который может помочь решить эту проблему, является шаблон Исходящие .
В этой статье разработчики DST Global рассмотрят, как реализовать шаблон исходящих сообщений с потоковой базой данных , который может обеспечить надежное решение для микросервисов или обмена данными между несколькими сервисами.
Потребность в надежном обмене данными микросервисов
В архитектуре микросервисов каждый микросервис имеет бизнес-логику, отвечает за свои собственные данные, имеет собственное локальное хранилище данных и выполняет свои собственные операции с этими данными ( данные для шаблона службы). Однако существуют сценарии, в которых микрослужбам необходимо обмениваться данными друг с другом или уведомлять другие службы о любых конкретных изменениях данных в режиме реального времени, чтобы поддерживать согласованность и предоставлять конечным пользователям согласованное взаимодействие. Например, в службе заказа такси может быть несколько микросервисов, отвечающих за различные функции, такие как управление пользователями, бронирование поездок, управление водителями и обработка платежей. Когда пользователь заказывает поездку, он запускает серию событий, которые необходимо передать различным микросервисам для обработки и обновления их данных.
Традиционная синхронная связь между микросервисами может привести к жесткой связи и потенциальным проблемам с производительностью и надежностью. Отправляющая служба должна знать местоположение, интерфейс и контракт других микрослужб, что может привести к сложной сети зависимостей. Это может затруднить разработку, тестирование и независимое развертывание микросервисов, поскольку любое изменение в одном микросервисе может потребовать изменений в нескольких зависимых микросервисах. Иногда эти целевые службы могут быть временно недоступны и могут привести к снижению производительности из-за необходимости ожидания и блокировки до получения ответа.
Асинхронный и развязанный обмен данными
С другой стороны, шаблон Outbox поддерживает асинхронный и несвязанный обмен данными между микросервисами. Когда событие или изменение происходит в одном микросервисе, он записывает событие или изменения в свой исходящий ящик, который действует как буфер. Исходящие можно реализовать как отдельную таблицу базы данных , которой владеет служба.
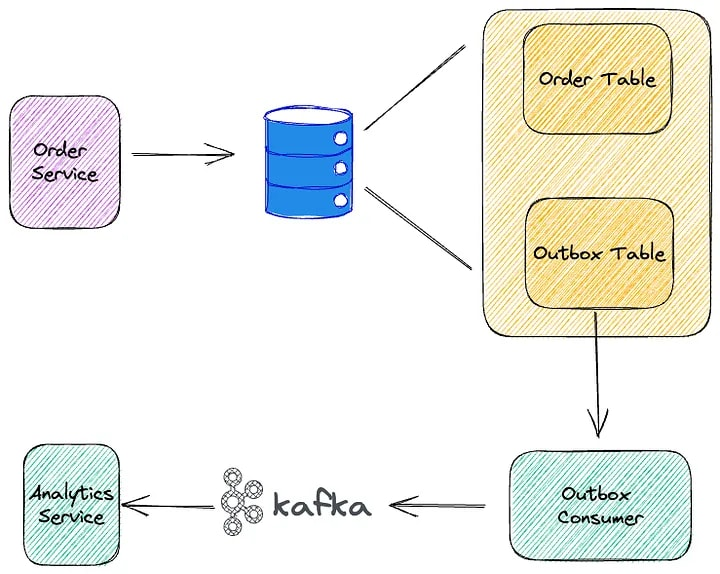
Исходящие сообщения микрослужбы затем обрабатываются обработчиком исходящих сообщений (отдельным компонентом или службой, например потоковой базой данных RisingWave, которая описана в разделе ниже), который считывает события или изменения из исходящих сообщений и отправляет их в другие микрослужбы или хранилища данных. асинхронно. Это позволяет микросервисам продолжать обработку запросов, не дожидаясь завершения обмена данными, что приводит к повышению производительности и масштабируемости .
Микросервис B, который необходимо обновить с учетом изменений из микросервиса A, получает события или изменения от обработчика исходящих сообщений и применяет их к своему собственному состоянию или хранилищу данных. микросервиса B Это гарантирует, что данные останутся согласованными с изменениями, внесенными в микросервис A.
Теперь давайте посмотрим, как можно реализовать паттерн Outbox с помощью потоковой базы данных на примере RisingWave. На рынке есть и другие варианты потоковой базы данных; Этот пост поможет вам понять, что такое база данных потоковой передачи, когда и зачем ее использовать , а также обсудит некоторые ключевые факторы, которые следует учитывать при выборе правильной базы данных потоковой передачи для вашего бизнеса.

RisingWave
RisingWave — это потоковая база данных, которая помогает создавать сервисы, управляемые событиями, в реальном времени. Он может напрямую считывать события изменения базы данных из традиционных бинарных журналов баз данных или тем Kafka и создавать материализованное представление, объединяя несколько событий вместе. RisingWave будет обновлять представление по мере поступления новых событий и позволит вам запрашивать с помощью SQL, чтобы иметь доступ к последним изменениям, внесенным в данные.
Шаблон исходящих сообщений с потоковой базой данных
База данных потоковой передачи может действовать как платформа потоковой передачи в реальном времени (процессор исходящих сообщений). Он прослушивает любые операции записи/обновления в указанной таблице базы данных, используя встроенный коннектор Change Data Capture (CDC) , фиксирует изменения и распространяет эти изменения на другие микросервисы в режиме реального времени или почти в реальном времени с помощью Kafka.
Одним из ключевых преимуществ использования потоковой базы данных является то, что вам не нужно использовать и Debezium, и Kafka Connect, чтобы добиться того же. Кроме того, у него есть собственное хранилище, вы никогда не потеряете потоковые данные и можете создавать материализованные представления, оптимизированные для запросов к микросервисам, что объясняется в другом посте в DST Club.
Кроме того, это дает нам возможность анализировать данные, передавая их на платформы бизнес-аналитики и анализа данных для принятия более эффективных бизнес-решений на основе использования вашего приложения. Например, просмотр истории поездок — важная функция службы заказа такси, позволяющая пассажирам и водителям получить доступ к истории их поездок. Вместо того, чтобы запрашивать отдельные записи о поездках и вычислять различные статистические данные, такие как общее количество поездок, заработок, рейтинги и т. д., можно использовать материализованное представление для хранения предварительно вычисленной информации об истории поездок для каждого пользователя в потоковой базе данных.
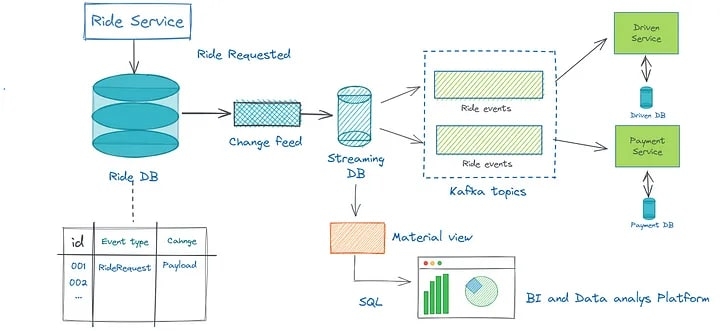
Вот как может работать обмен данными с шаблоном «Исходящие» и потоковой базой данных для нашего примера службы заказа такси:
Служба Ride (микрослужба A). Когда пользователь запрашивает поездку, служба Ride создает сведения о поездке и записывает событие, например RideRequested, в свою таблицу исходящих сообщений в собственной базе данных, скажем, в MySQL.
По умолчанию база данных потоковой передачи захватывает событие «RideRequested» из исходящей таблицы Ride Service, используя свой коннектор для MySQL CDC . Он обрабатывает событие и отправляет его другим микрослужбам, которые необходимо обновить, таким как служба драйверов (микрослужба B), служба платежей (микрослужба C) и служба уведомлений (микрослужба D), используя брокер сообщений, такой как Apache Kafka.
Служба водителя (микрослужба B). Служба водителя получает событие RideRequested от процессора исходящих сообщений и находит доступного водителя для поездки на основе сведений о поездке. Затем он записывает событие, такое как «DriverAssigned», в свой собственный почтовый ящик.
Платежная служба (микрослужба C). Платежная служба также получает событие «RideRequested» из другой темы Kafka и рассчитывает стоимость поездки на основе сведений о поездке. Затем он записывает событие, например «FareCalculated», в свой собственный почтовый ящик.
Мы можем создать несколько тем Kafka, чтобы предоставить потребительским службам возможность подписываться только на определенные типы событий.
Заключение
Как мы поняли, синхронная связь между микросервисами может привести к жесткой связи, снижению производительности, отсутствию отказоустойчивости, ограниченной масштабируемости, проблемам с версиями и снижению гибкости и маневренности. Используя платформы потоковой передачи в реальном времени, такие как RisingWave, и отделяя процесс обмена данными от основного потока транзакций, применяя шаблон исходящих сообщений, вы можете добиться высокой производительности, надежности и согласованности в своей архитектуре микросервисов.
Надежный обмен данными микросервисов с потоковой базой данных
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Одним из самых фундаментальных и критически важных решений при создании современного приложения является выбор технологии для хранения данных. Этот выбор, часто стоящий перед архитекторами и разраб...
Выбор правильной базы данных является критически важным выбором при создании люб...
Цель этой статьи — ответить на один вопрос: ...
В этой статье разработчиками компании DST Global, ...
Программное обеспечение хранилища данных помогает ...
В этой статье разработчики компании DST Global ...
Двоичное квантование в векторных базах данных повы...
В этой статье вы узнаете от разработчиков компании...
Узнайте о преимуществах от разработчиков компании ...
Oracle — самая популярная база данных в мире...
Принцип работы: когда в одном микросервисе происходит событие или изменение, он записывает его в свой выходной буфер, который выступает буфером. Буфер можно реализовать как отдельную таблицу базы данных, которая принадлежит сервису.
Затем выходной буфер микросервиса обрабатывается процессором Outbox (отдельным компонентом или сервисом, например, потоковой базой RisingWave). Он читает события или изменения из буфера и асинхронно отправляет их другим микросервисам или хранилищам данных. Это позволяет микросервисам продолжать обработку запросов, не ожидая завершения обмена данными, что повышает производительность и масштабируемость системы.
Также для обмена данными микросервисов с потоковой базой данных можно использовать платформу потоковой обработки событий, например, Apache Kafka. Она позволяет публиковать и подписываться на потоки событий, отказоустойчиво хранить и обрабатывать их в реальном времени.
Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в управлении данными
Микросервисная архитектура для распределенных систем позволяет обеспечить гибкость, масштабируемость и отказоустойчивость. Однако, как мы уже упоминали здесь, запрос данных из нескольких микросервисов в режиме реального времени может оказаться сложной задачей, поскольку для этого могут потребоваться сложные и трудоемкие операции извлечения данных. Материализованные представления вместе с паттерном проектирования разделения ответственности команд и запросов (CQRS, Command Query Responsibility Segregation) могут решить эту проблему, обеспечивая эффективный запрос данных микросервисов в режиме реального времени.
В качестве примера возьмем интернет-магазин с микросервисной архитектурой. Разделим большую систему по микросервисам на основании ключевых объектов управления: товары, каталоги, клиенты, запасы и заказы. Каждый микросервис отвечает за обработку определенного домена или бизнес-функции и хранение данных в своем собственном хранилище данных, реализуя шаблон Database per Service.
Без материализованных представлений запрос данных из нескольких микросервисов в режиме реального времени может быть затруднен. Например, когда клиент ищет продукт на веб-сайте, необходимо получить информацию о продукте, каталог, цены и состояние запасов из различных микросервисов. Это приводит к множеству двусторонних запросов к разным микросервисам, увеличивая время отклика и нагрузку на базы данных. Самое простое решение, чтобы агрегировать клиентские запросы к нескольким микросервисам в одном вызове API.
Это решение соответствует шаблону композиции API (API Composition). Суть этого паттерна в том, что он реализует запрос, вызывая сервисы, владеющие данными, и выполняет объединение результатов в памяти. Этот прием часто использует другой шаблон проектирования микросервисной архитектуры, шлюз API (API Gareway). Шаблон композиции API является достаточно простым в реализации. В частности, реализовать его можно с помощью технологии GraphQL, которая позволяет клиенту запрашивать только нужные данные из нескольких источников в одном запросе, выполняя федерализацию нескольких схем данных.
Однако, для GraphQL характерны риски доступа клиента к непредназначенным для него данным. Кроме того, при использовании шаблона композиции API некоторые запросы могут привести к неэффективному объединению больших наборов данных в памяти. Поэтому для этого шаблона характерны проблемы с масштабируемостью и обслуживанием. Также такое архитектурное решение приводит к тесной связи между микросервисами, что считается антипаттерном. Сильная связность между микросервисами противоречит самой идее микросервисной архитектуры. В частности, при запросах к микросервисам необходимо знать структуру данных, возвращаемую запрашиваемыми микросервисами. Кроме того, усложняется реализация, поскольку требуется дополнительная логика для агрегирования и объединения данных из нескольких микросервисов. Композиция API может привести к дополнительным потерям производительности, поскольку микросервису оркестратора нужно дождаться ответов от нескольких микросервисов, прежде чем возвращать результат клиенту. При этом не получиться обеспечить обновление данных из нескольких микросервисов в режиме реального времени. Если данные в запрошенных микросервисах часто изменяются, композиция API может не отражать самые последние данные, что чревато снижением качества данных и устаревшеми сведениями в результатах запроса. Альтернативой является использование материализованных представлений и CDC-подход, что мы рассмотрим далее.
Изменим архитектуру проектируемой системы, используя захват измененных данных (CDC, Change Data Capture) и материализованные представления для оптимизации запросов к микросервисам в режиме реального времени и повышения производительности.
CDC-подход используется в микросервисах для отслеживания изменений в базах данных. Обычно это реализуется с помощью специализированных продуктов или самописные решения, о чем мы писали здесь. Это позволяет уведомлять несколько микросервисов о любых изменениях данных, чтобы их можно было соответствующим образом обновить. Такой механизм экономит много времени, позволяя работать только с ограниченным объемом измененных данных вместо полного сканирования базы. Чтобы использовать CDC с микросервисами, механизм захвата измененных данных должен быть интегрирован в каждый из них еще на этапе проектирования приложения. При этом необходимо решить следующие вопросы:
Как фиксировать изменения данных – через триггеры на таблицах БД, опросы, логи или готовые решения типа Debezium. Триггеры, как частный случай хранимых процедур, могут использоваться для выполнения действия при определенных событиях. Подробнее о сходстве и различии триггеров и хранимых процедур мы писали здесь на примере Greenplum. Опрос регулярно запрашивает базу данных, чтобы узнать, были ли внесены изменения. Логи фиксируют всю активность базы данных, включая изменения, и могут использоваться для обработки в реальном времени. Каждый из подходов имеет свои достоинства и недостатки, которые следует учитывать для каждого конкретного сценария.
Как передавать изменения данных – синхронно или асинхронно. Синхронная связь полезна для кратковременных транзакций, а асинхронная связь идеальна для длительных процессов.
Как обеспечить согласованность данных между сервисами – через использование распределенных транзакций, что чревато проблемами с производительностью, или через согласованность в конечном счете, когда каждый сервис работает со своими собственными данными и в конечном итоге становится согласованным с другими приложениями.
В рассматриваемом примере интернет-магазина CDC-подход можно использовать для управления запасами. Например, каждый раз, когда товар добавляется, обновляется или удаляется из каталога, механизм CDC фиксирует изменение и отправляет его в микросервисы, отвечающие за управление товарами и запасами. Так CDC позволяет поддерживать актуальность наличия товаров, гарантируя клиентам постоянный доступ к нужным им продуктам.
CDC позволяет реализовать инкрементные обновления хранилища данных, фиксируя изменения, внесенные в системе-источнике, чтобы загружать только их в DWH. Это сокращает время, необходимое для полной загрузки, и обеспечивает постоянную актуальность данных в хранилище данных. Также CDC можно использовать для потоковой передачи данных из нескольких источников с целью их анализа в реальном времени. Наконец, CDC пригодится для обновления моделей AI/ML новыми данными. CDC фиксирует изменения, внесенные в исходную базу данных, и обновляет модели AI/ML новыми данными. Это помогает обновлять ML-модели с использованием самых последних данных, повышая их точность.
Впрочем, помимо CDC-подхода в рассматриваемом кейсе интернет-магазина имеет смысл использовать и другой паттерн управления данными в микросервисной архитектуре – CQRS, суть которого в отделении запросов от команд. CQRS предполагает наличие базы данных представления, которая является доступной только для чтения репликой, предназначенной для поддержки запросов. Приложение поддерживает реплику в актуальном состоянии, подписываясь на события домена, публикуемые сервисом, которому принадлежат данные. Этот шаблон поддерживает несколько денормализованных представлений, которые являются масштабируемыми и производительными. Он позволяет упростить модели команд и запросов, что полезно в EDA-архитектуре, управляемой событиями в реальном времени.
Однако, CQRS как шаблон проектирования, имеет следующие недостатки: повышенная сложность, возможное дублирование кода, задержка репликации и представления, согласованные в конечном счете.
Тем не менее, CQRS позиционируется как альтернатива шаблону композиция API без проблем с масштабируемостью и производительностью. Для реализации CQRS следует определить команды, которые будут изменять данные, и запросы, которые будут считывать данные. Такое разделение позволяет оптимизировать каждую операцию независимо. Например, товары могут храниться и обновляться в классической базе данных, а списки товаров, результаты поиска, история заказов или рекомендации пользователей могут быть материализованными представлениями в потоковой база данных, которые обновляются в режиме реального времени на основе входящих событий.
Материализованные представления — это предварительно вычисленные представления данных, которые хранятся и обновляются независимо от основной транзакционной базы данных. Их можно использовать для оптимизации операций чтения за счет уменьшения сложности и задержки, связанных с запросами к основной базе данных.
Сперва идентифицируем запросы, требующие доступа к данным интернет-магазина в режиме реального времени, например, списки недавно просмотренных товаров. Основная цель здесь — сохранить данные, требуемые службой запросов, в денормализованном формате, чтобы обеспечить быстрый поиск. Материализованные представления денормализованы и оптимизированы для конкретного запроса или представления в пользовательском интерфейсе, чтобы быстрее и эффективнее извлекать данные. Материализованные представления могут быть созданы с использованием баз данных или специализированных систем кэширования. Чтобы получать обновления в режиме реального времени и поддерживать согласованность этих данных, подписавшись на изменения состояния баз других микросервисов, целесообразно использовать потоковую СУБД, например, Rockset, Materialise, RisingWave и DeltaStream. Подробнее о потоковых базах данных, которые поддерживают аналитические операции с непрерывными потоками данных в реальном времени с помощью SQL-запросов, мы писали здесь и здесь.
Потоковая СУБД может принимать данные в режиме реального времени из различных источников в виде потоков событий с помощью CDC-процесса и встроенного коннектора. Потоковая база данных создает материализованное представление, объединяя потоки событий вместе, и поддерживает актуальность представления по мере поступления новых событий обновления, добавления и удаления данных. Например, когда новый товар добавляется в каталог, соответствующее событие фиксируется и используется для обновления материализованного представления списков товаров, гарантируя актуальность и согласованность данных.
Возвращаясь к паттерну CQRS, который предполагает разделение команд и запросов, следует добавить микросервис, который будет обслуживать запросы на чтение, поступающие из пользовательского интерфейса клиентского приложения. Эти запросы API преобразуются в SQL-запросы, которые извлекают данные из материализованных представлений потоковой базы. Например, когда пользователь ищет товар, результаты поиска можно получить из материализованного представления для списков поиска, вместо того чтобы выполнять несколько вызовов API к различным микросервисам.
Таким образом, материализованные представления упрощают логику запросов, заранее агрегируя данные, избавляя разработчика от работы со сложными SQL-запросами со множеством JOIN-операторов. Благодаря оптимизации материализованных представлений под конкретные запросы, можно снизить нагрузку на основную базу данных и повысить общую производительность системы. Материализованные представления в потоковой базе данных могут предоставлять данные в режиме реального времени из нескольких микросервисов, реализуя шаблон CQRS. Разделение операций чтения и записи с предварительным вычислением представления данных также обеспечивает масштабируемость и отказоустойчивость. Потоковая база может быть развернута независимо от основной, что соответствует горизонтальному масштабированию запросов. Наконец, базу данных потоковой передачи можно использовать в качестве резерва на случай, если основная база выйдет из строя.