

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Стратегии масштабирования баз данных в DST Global

В этой статье от разработчиков компании DS Global, вы узнаете о различных решениях и методах масштабирования сервера базы данных, разделенных на стратегии чтения и записи.
Знание различных методов масштабирования баз данных поможет нам выбрать подходящую стратегию для адаптации к нашим потребностям и целям.
Следовательно, в этом посте мы продемонстрируем различные решения и методы масштабирования сервера баз данных. Они делятся на стратегии чтения и письма.
Чтение/загрузка
Иногда у нас есть приложения, которые находятся под такой большой нагрузкой . И чтобы решить эту проблему, мы демонстрируем три различных метода , которые мы можем реализовать.
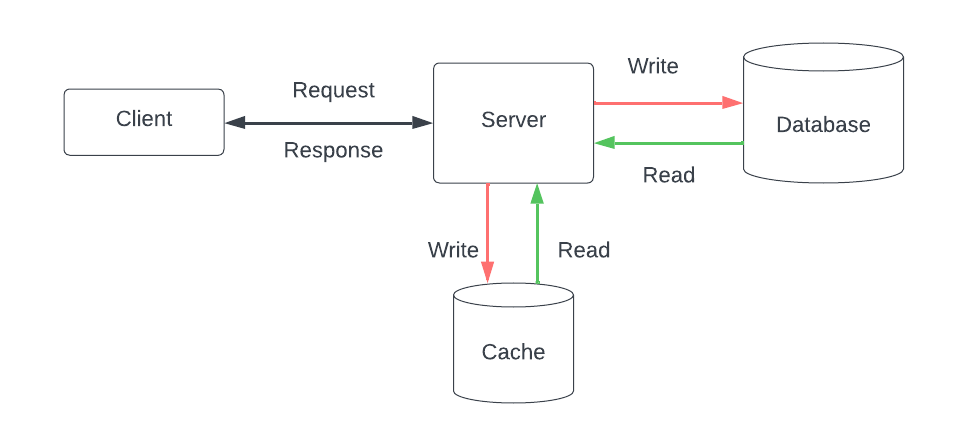
Кэширование
Техника кэширования сохраняет часто запрашиваемые данные или ответы на дорогостоящие вычислительные операции во временной памяти. Данные, хранящиеся в кеше, должны быть изменены по характеру приложения, и для их обновления можно использовать технику аннулирования кеша и вытеснения для поддержания согласованности данных. Это может быть достигнуто с помощью метода времени жизни кэша с истекшим сроком действия ( TTL ) или других методов, зависящих от используемых шаблонов кэширования.
Различные шаблоны кэширования можно использовать в качестве стратегии реализации решений кэширования. Кэширование в стороне поддерживает тяжелые чтения и работает, даже если кеш выходит из строя. Сквозное чтение и сквозная запись используются вместе. Они являются отличной альтернативой для рабочих нагрузок с интенсивным чтением, но сбой кэша приводит к сбою системы. Обратная запись полезна для написания больших рабочих нагрузок и используется различными реализациями СУБД.
В зависимости от требований, таких как интенсивное чтение или запись, или сочетание того и другого, мы можем решить, какой шаблон использовать таким образом, чтобы мы могли позволить себе сбой кэша или базы данных.
Репликация
Репликация работает с одной базой данных, называемой основной , куда направляются все запросы на запись. Кроме того, мы делаем точную копию этой основной базы данных в виде новых реплик узла, известных как вторичные, ответственные только за обработку запросов на чтение. Основная база данных постоянно снабжает подчиненные узлы более свежими данными, сохраняя нашу информацию согласованной между всеми узлами в кластере.
Репликация — отличная стратегия для обеспечения отказоустойчивости и поддержания теоремы CAP и масштабируемости системы. Предположим, что один из узлов выходит из строя, мы продолжаем обслуживать, поскольку у нас есть те же данные, реплицированные в других узлах. Также в кластере узел может вступить во владение и стать основной базой данных в случае отказа основного узла. Репликация также помогает уменьшить задержку в приложении, поскольку мы можем развернуть нашу базу данных и реплицировать данные в разных регионах, таких как CDN, и локальные пользователи могут легко получить к ним доступ.
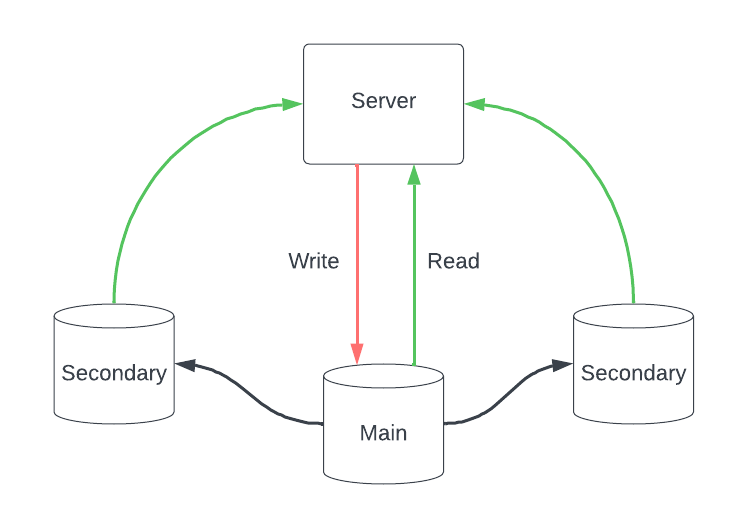
Синхронный и асинхронный
Помимо этих преимуществ, поддержание согласованности в узле реплики усложнялось с увеличением количества узлов. Эту проблему можно решить с помощью стратегии синхронной или асинхронной репликации в зависимости от требований.
Преимущество синхронной стратегии заключается в том, что задержка равна нулю , а данные всегда согласованы, но в качестве недостатка производительность снижается, когда необходимо дождаться обновления и подтверждения всех реплик эмитентом. С другой стороны, в асинхронной стратегии запись стала быстрее, поскольку основной узел не ждет подтверждения, а создает проблему несогласованного состояния, если реплике не удается обновить значение.
Имейте в виду, что серебряной пули не существует, лучшая стратегия зависит от наших потребностей. Необходимо принять компромисс между согласованностью, доступностью или разделением ( теорема CAP ). Теорема CAP утверждает, что мы можем гарантировать только два из них одновременно.
Индексация
Индексация используется для поиска и быстрого доступа к данным, повышая производительность операций базы данных. С таблицей базы данных может быть связан один или несколько индексов.
Индексирование повышает производительность запросов за счет более быстрого извлечения данных, повышает эффективность доступа к данным, уменьшая количество операций ввода-вывода для извлечения данных. Это оптимизирует сортировку данных, поскольку базе данных не нужно сортировать всю таблицу, а только соответствующие строки. Индексация поддерживает согласованность данных даже при увеличении объема данных. Кроме того, индексация обеспечивает целостность базы данных, позволяя избежать дублирования данных.
Недостатком индексации является необходимость в большем объеме памяти, что увеличивает размер базы данных. Это также увеличивает накладные расходы на обслуживание при добавлении, удалении и изменении таблицы. Индексация может снизить производительность операций вставки и обновления.

Письмо
Для приложений, которые много пишут в базу данных, а пользователи постоянно наносят ей вред новыми данными, у нас есть стратегии сегментирования и NoSQL.
Разделение
Разделение или разделение данных позволяет разделить данные больших баз данных на более мелкие, более быстрые и более простые в управлении части, разделив базу данных на несколько основных баз данных. Существует два вида сегментирования: вертикальное и горизонтальное .
Преимущество раздела данных заключается в оптимизации запросов, обеспечивающей лучшую производительность и сокращающую задержку. Это позволяет иметь данные пользователей в разных местах, к которым можно получить более быстрый доступ для пользователей в определенных регионах. Кроме того, он имеет то преимущество, что позволяет избежать единой точки отказа.
Один из недостатков шардинга — перегрузка раздела, если мы неправильно распределили данные по разделу. В зависимости от выбранной стратегии мы можем получить некоторые разделы с большим количеством данных, а некоторые с меньшим количеством данных, и запрос к этому большому разделу может стать медленнее. Другим недостатком является возможность вернуться и восстановить предыдущее состояние стратегии отсутствия сегментирования после ее реализации и разделения данных по разным базам данных.
Применение раздела может быть логическим или физическим. Логическое сегментирование — это когда у нас есть другое подмножество данных на одной и той же физической машине, а физическое сегментирование может иметь более одного подмножества разделов на физической машине.
Для разделения данных мы можем выбирать между алгоритмическим или динамическим разделением. Существуют различные алгоритмы и методы динамического сегментирования, поскольку сегментирование на основе ключей , диапазонов и каталогов является наиболее используемым.
Вертикальное разделение
Для вертикального шардинга мы берем каждую таблицу и помещаем их на разные машины. Например, пользовательские таблицы, таблицы журналов или таблицы комментариев, каждая на разных машинах. Вертикальное сегментирование эффективно, когда запросы обычно возвращают только подмножество столбцов данных. Например, если одни запросы запрашивают только имена, а другие запрашивают только адреса, то имена и адреса могут быть разнесены на отдельные серверы.
Горизонтальное разделение
Если у нас есть одна таблица, которая стала очень большой, мы применяем горизонтальное сегментирование. Мы берем одну таблицу и разделяем порцию связанных данных на несколько машин. Горизонтальное сегментирование эффективно, когда запросы обычно возвращают подмножество строк, которые часто группируются. Например, запросы, которые фильтруют данные на основе коротких диапазонов дат, идеально подходят для горизонтального сегментирования, поскольку диапазон дат обязательно ограничивает запросы только подмножеством серверов.
NoSQL
NoSQL не является реляционной базой данных и по сути является парой ключ-значение. Модели пары ключ-значение, естественно, могут легко масштабироваться сами по себе на нескольких разных машинах. NoSQL подразделяется на четыре основные категории: ориентированный на столбцы , который хранит данные в виде семейств столбцов, график хранит данные в виде узлов и ребер, ключ-значение хранит данные в виде пар ключ-значение, а документ хранит данные в виде полуструктурированных документов.
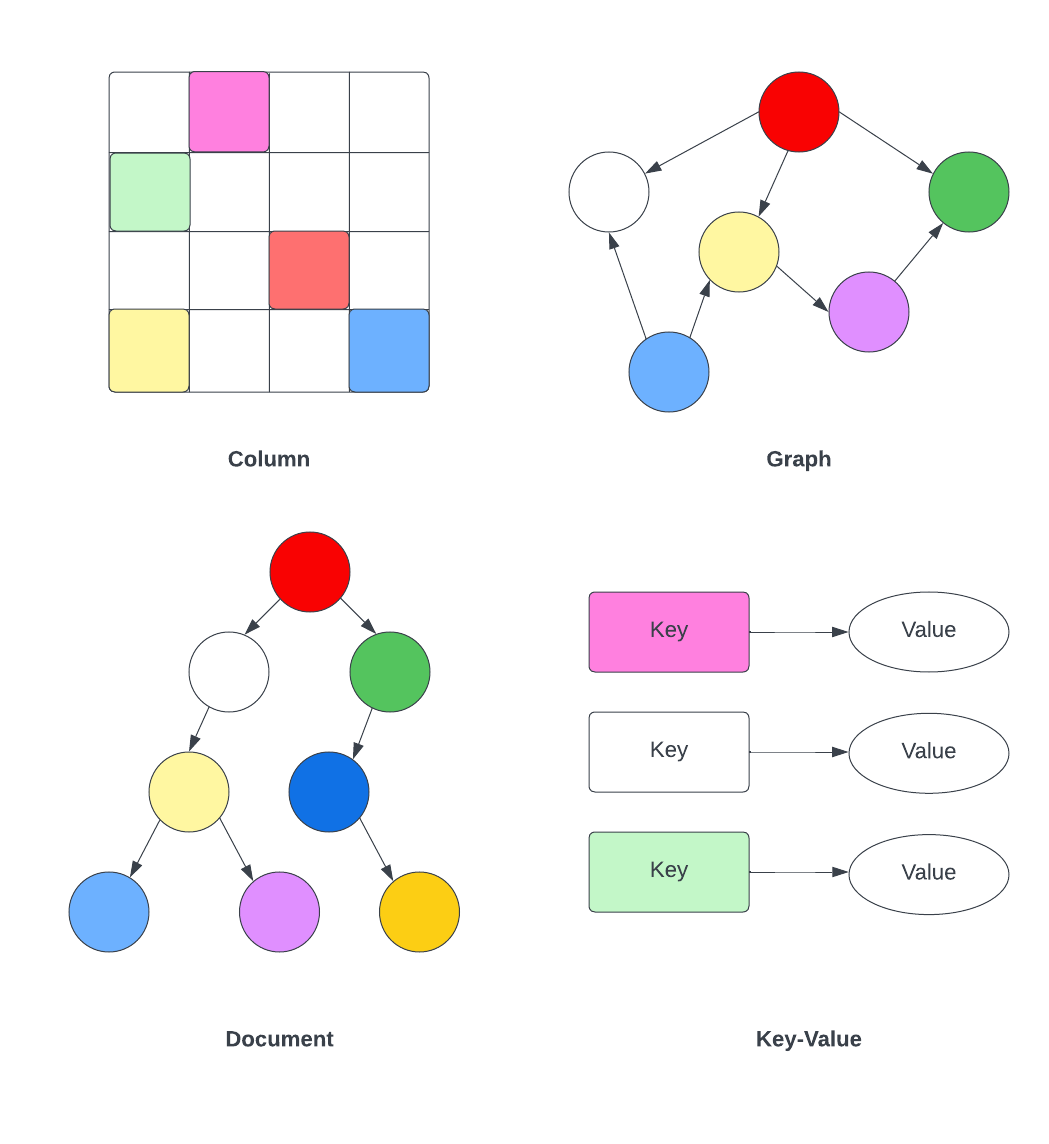
Это позволяет использовать динамическую схему , которая может вносить изменения без изменения схемы. Кроме того, он обеспечивает горизонтальную масштабируемость , поскольку был разработан для масштабирования путем добавления дополнительных узлов в кластер базы данных. Он также предназначен для обеспечения высокой доступности для автоматической обработки сбоев узлов и репликации данных между несколькими узлами в кластере.
Эта нереляционная база данных предлагает несколько преимуществ по сравнению с реляционными базами данных, таких как масштабируемость , гибкость и экономичность . Однако у них также есть несколько недостатков, таких как отсутствие стандартизации , отсутствие ACID соответствия и отсутствие поддержки сложных запросов.
Заключение
В этой статье разработчики компании DST Global продемонстрировали стратегии, которые необходимо реализовать при работе с масштабируемостью базы данных.
Мы разделили его между стратегиями чтения и письма. Для чтения мы можем применять различные механизмы кэширования , репликацию с первичными и вторичными базами данных, а также реализовывать индексирование для поиска и быстрого доступа к данным. Для написания масштабируемости есть стратегии сегментирования или NoSQl, как со своими преимуществами, так и со своими недостатками.
Наконец, имейте в виду, что идеальных решений не существует, нам нужно понимать наши требования и применять компромиссы, чтобы выбрать лучшие стратегии для нашего приложения.
Стратегии масштабирования баз данных в DST Global
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Одним из самых фундаментальных и критически важных решений при создании современного приложения является выбор технологии для хранения данных. Этот выбор, часто стоящий перед архитекторами и разраб...
Выбор правильной базы данных является критически важным выбором при создании люб...
Цель этой статьи — ответить на один вопрос: ...
В этой статье разработчиками компании DST Global, ...
Программное обеспечение хранилища данных помогает ...
В этой статье разработчики компании DST Global ...
Двоичное квантование в векторных базах данных повы...
В этой статье вы узнаете от разработчиков компании...
Узнайте о преимуществах от разработчиков компании ...
Oracle — самая популярная база данных в мире...
Масштабирование базы данных
Прежде всего нужно понять, какие данные требуют масштабирования базы данных, почему они требуют. Единого решения и ответа здесь нет, а все зависит от конкретного проекта. Все зависит от множества нюансов, например, от того, как и где храняться данные. А ведь хранить разные данные можно по разному.
Давайте кратко вспомним какие основные модели хранения данных обычно используют.
— Реляционные базы данных — все данные хранятся в виде набора отношений, связанных между собой данных.
— Иерархические базы данных — данные хранятся в объектах в виде отношений между этими объектами.
— Сетевые базы данных — данные хранятся в структуре в виде графа.
— Объектно-ориентированные базы данных — данные храняться в виде моделей объектов.
Выбор и использование модели базы данных зависит от самих данных и все вопросы, которые касаются работы с данными, должны решаться на стадии выбора способа хранения данных.
С ростом количества пользователей, растет и количество данных, а соответственно и количество запросов и действий для работы с этими данными.
При масштабировании базы данных следует учитывать особенности сервера базы данных, какие настройки это сервера используются, правильно ли сервер вообще настроен. Нужно анализировать, какие запросы в приложении используются и какие затрудняют работу с данными, улучшить такие запросы, проверить структура базы в целом: таблицы, индексы полей этих таблиц.
Шардинг базы данных
И конечно же, здесь применимо масштабирование в горизонтальном направлении, разделение данных на несколько баз данных на разных серверах. Но при масштабировании базы данных это не просто горизонтальное масштабирование, а шардинг. Шардинг — это когда вы разделяете данные по базам данных на отдельных серверах, при этом разбиение данных должно производиться с учетом их максимальной связности в одном шарде и минимальной связанности в остальных шардах.
Репликация
Любой сервер, на котором расположена база данных, может выйти из строя и перестать работать. Чтобы не потерять данные используется репликация.
Репликация — это осуществление связи между серверами баз данных, перенос данных между этими серверами в тот момент, когда данные добавляются. При выходе из строя одного сервера базы данных, к работе подключается другой сервер, с точно такими же данными и все продолжает работать. Когда нерабочий сервер восстанавливается в работе, он вновь подключается для репликации и на него копируются данные добавленные в момент выхода из строя.Более подробней о репликации можно почитать в моем посте о репликации данных в MongoDB.
Партиционирование
Еще один метод масштабирования базы данных — партиционирование. Партиционирование — это функциональное разделение базы данных на некие отдельные места хранения: в разных таблицах, в разных типах баз данных (одни данные в MySQL, другие в MongoDB), в разных моделях хранения данных.
Денормализация
В некоторых случаях, разработчики прибегают к использованию денормализации для обеспечения быстрого доступа к данным. Денормализация — это когда данных дублируются при сохранении. Например, при создании поста для сайта, производится добавление тегов к этому посту. Вместо того, чтобы сохранять теги в отдельную таблицу, проверяя каждый раз тег на существование, чтобы не плодить дубли текста, а связь с постами и тегами во вторую таблицу, при денормализации все добавляет в одну таблицу, дублируя каждый раз текст. В некоторых случаях, денормализация данных приемлема, в остальных от нее лучше отказаться.
Но это «по идее». В реальной разработке предпочтение, как правило, отдается тем инструментам и технологиям, которые знают главные специалисты команды. Однако, это не отменяет того факта, что специализированные решения можно применять для отдельных типов хранимых данных.
Есть базы данных общего назначения, которые все знают — MySQL и PostgreSQL. Они применяются на большинстве проектов и при правильном обращении их вполне достаточно. Если перечислять специализированные решения, то получится большой список из десятков проектов. Наиболее популярные — это MongoDB, Redis (у Mail.ru есть своя NoSQL база данных Tarantool, которая тоже показывает неплохие результаты). Однако, для большинства проектов в общем случае будет достаточно стандартных MySQL или PostgreSQL.
База данных — это все-таки не просто слой хранения данных и инструмент. Это ответственность за данные, рискованным экспериментам здесь, скорее всего, не место. Отсюда следует, что очень важна экосистема вокруг проекта — то, что заставляет его развиваться. Важно большое сообщество, которое может помочь с решением практически любой задачи. Поэтому лучше пользоваться продуктами с хорошей поддержкой. Ну, это все лирика, давайте перейдем к более практическим темам.