

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Redis как основная база данных для сложных приложений

Цель этой статьи — ответить на один вопрос: как можно использовать Redis в качестве основной базы данных для сложных приложений, которым необходимо хранить данные в нескольких форматах?
Сначала мы рассмотрим, что такое Redis и как он используется, а также почему он подходит для современных сложных микросервисных приложений. Разработчики компании DST Global расскажут о том, как Redis поддерживает хранение нескольких форматов данных для различных целей с помощью своих модулей. Далее мы увидим, как Redis, как база данных в памяти, может сохранять данные и восстанавливаться после потери данных. Мы также поговорим о том, как Redis оптимизирует затраты на хранение в памяти с помощью Redis на Flash.
Затем мы увидим очень интересные примеры использования масштабирования Redis и его репликации в нескольких географических регионах. Наконец, поскольку одной из самых популярных платформ для запуска микросервисов является Kubernetes, а запуск приложений с отслеживанием состояния в Kubernetes немного сложен, мы увидим, как можно легко запустить Redis на Kubernetes.
Что такое Redis?
Redis, что на самом деле означает Remote Dictionary Server, — это база данных в памяти . Многие люди использовали ее в качестве кэша поверх других баз данных для повышения производительности приложений. Однако многие не знают, что Redis — это полноценная первичная база данных, которую можно использовать для хранения и сохранения нескольких форматов данных для сложных приложений.
Пример сложного приложения для социальных сетей
Давайте рассмотрим общую настройку для приложения микросервисов. Допустим, у нас есть сложное приложение социальных сетей с миллионами пользователей, с такой задачей разработчики компании DST Global сталкиваются регулярно создавая крупные маркетплейсы, экосистемы, порталы или социальные сети. И допустим, наше приложение микросервисов использует реляционную базу данных, например MySQL, для хранения данных. Кроме того, поскольку мы собираем тонны данных ежедневно, у нас есть база данных Elasticsearch для быстрой фильтрации и поиска данных.
Теперь все пользователи связаны друг с другом, поэтому нам нужна графовая база данных для представления этих связей. Плюс, наше приложение содержит много медиаконтента, которым пользователи делятся друг с другом ежедневно, и для этого у нас есть база данных документов . Наконец, для лучшей производительности приложения у нас есть служба кэширования, которая кэширует данные из других баз данных и делает их доступными быстрее.
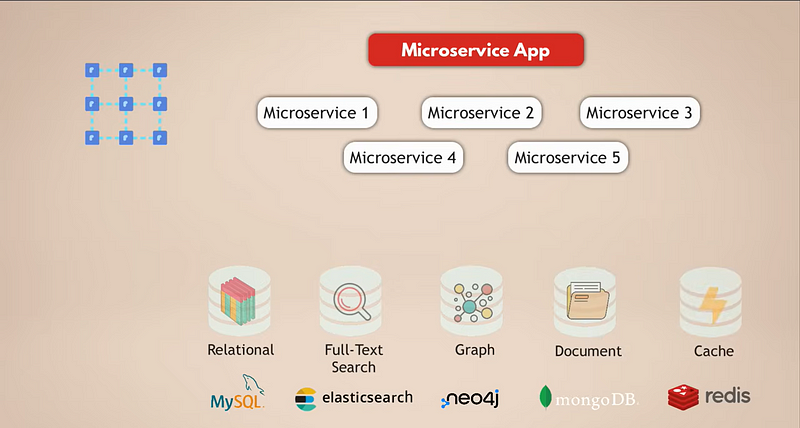
Теперь очевидно, что это довольно сложная установка. Давайте посмотрим, какие проблемы возникают в этой установке:
1. Развертывание и обслуживание
Все эти службы данных должны быть развернуты, запущены и обслуживаться. Это означает, что ваша команда должна иметь определенные знания о том, как управлять всеми этими службами данных.
2. Требования к масштабированию и инфраструктуре
Для высокой доступности и лучшей производительности вам нужно масштабировать свои сервисы. Каждый из этих сервисов данных масштабируется по-разному и имеет разные требования к инфраструктуре, и это может стать дополнительной проблемой. Таким образом, в целом, использование нескольких сервисов данных для вашего приложения увеличивает усилия по поддержанию всей настройки вашего приложения.
3. Стоимость облака
Конечно, в качестве более простой альтернативы самостоятельному запуску и управлению сервисами вы можете использовать управляемые сервисы данных от облачных провайдеров. Но это может быть очень дорого, поскольку на облачных платформах вы платите за каждый управляемый сервис данных отдельно.
4. Сложность разработки
С точки зрения разработки, ваш код приложения также становится довольно сложным, поскольку вам нужно общаться с несколькими службами данных. Для каждой службы вам понадобится отдельный коннектор и логика. Это также делает тестирование ваших приложений довольно сложным.
5. Более высокая задержка
Чем больше сервисов общаются друг с другом, тем выше задержка. Даже если каждый сервис может быть быстрым сам по себе, каждый шаг соединения между сервисами или каждый сетевой переход добавит некоторую задержку к вашему приложению.
Почему Redis упрощает эту сложность
По сравнению с многомодальной базой данных, такой как Redis, вы решаете большинство следующих проблем:
- Единая служба данных . Вы запускаете и обслуживаете только одну службу данных. Поэтому ваше приложение также должно взаимодействовать с одним хранилищем данных, что означает только один программный интерфейс для этой службы данных.
- Сокращение задержки . Задержка будет уменьшена за счет перехода к единой конечной точке данных и исключения нескольких внутренних сетевых переходов.
- Несколько типов данных в одной . Наличие одной базы данных, такой как Redis, которая позволяет хранить различные типы данных (т. е. несколько типов баз данных в одной), а также выступать в качестве кэша, решает такие проблемы.
Как Redis поддерживает несколько форматов данных
Итак, давайте посмотрим, как на самом деле работает Redis. Прежде всего, как Redis поддерживает несколько форматов данных в одной базе данных?
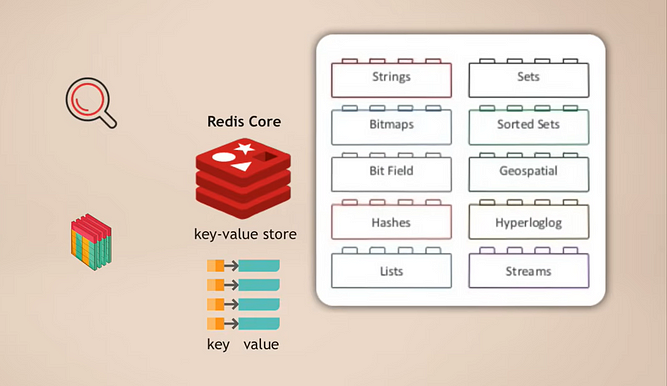
Ядро и модули Redis
Работает это так: у вас есть Redis ядро, которое является хранилищем ключей и значений, которое уже поддерживает хранение нескольких типов данных. Затем вы можете расширить это ядро с помощью так называемых модулей для различных типов данных, которые нужны вашему приложению для различных целей. Например:
- RedisSearch для функциональности поиска (как Elasticsearch)
- RedisGraph для хранения графических данных
Прелесть этого в том, что это модульно. Эти различные типы функциональности базы данных не тесно интегрированы в одну базу данных, как во многих других многомодальных базах данных, а, скорее, вы можете выбрать и точно выбрать, какая именно функциональность службы данных вам нужна для вашего приложения, а затем просто добавить этот модуль.
Встроенное кэширование
И, конечно, при использовании Redis в качестве основной базы данных вам не нужен дополнительный кэш, потому что он у вас есть автоматически из коробки с Redis. Это означает, опять же, меньшую сложность в вашем приложении, потому что вам не нужно реализовывать логику для управления, заполнения и аннулирования кэша.
Высокая производительность и более быстрое тестирование
Наконец, как база данных в памяти, Redis очень быстр и производительен, что, конечно, делает само приложение быстрее. Кроме того, он также делает запуск тестов приложения намного быстрее, потому что Redis не нуждается в схеме, как другие базы данных. Поэтому ему не нужно время на инициализацию базы данных, построение схемы и т. д. перед запуском тестов. Вы можете начинать с пустой базы данных Redis каждый раз и генерировать данные для тестов по мере необходимости. Быстрые тесты могут действительно повысить производительность вашей разработки.
Сохранение данных в Redis
Мы поняли, как работает Redis и все его преимущества. Но в этот момент вы можете задаться вопросом: как база данных в памяти может сохранять данные ? Ведь если процесс Redis или сервер, на котором работает Redis, выйдет из строя, все данные в памяти пропадут, верно? И если я потеряю данные, как я смогу их восстановить? Так что, в общем, как я могу быть уверен, что мои данные в безопасности?
Самый простой способ резервного копирования данных — репликация Redis. Таким образом, если главный экземпляр Redis выйдет из строя, реплики все равно будут работать и иметь все данные. Если у вас есть реплицированный Redis, реплики будут иметь данные. Но, конечно, если все экземпляры Redis выйдут из строя, вы потеряете данные, потому что не останется ни одной реплики.
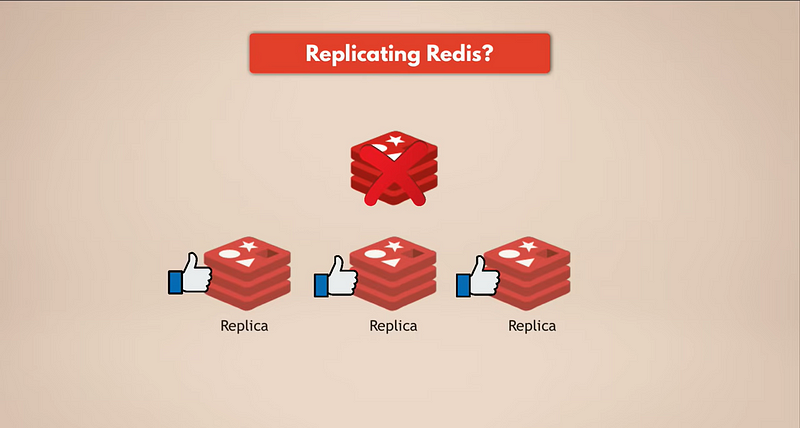
Моментальный снимок (RDB)
Redis имеет несколько механизмов для сохранения данных и обеспечения их безопасности. Первый из них — моментальные снимки, которые вы можете настроить на основе времени, количества запросов и т. д. Моментальные снимки ваших данных будут храниться на диске, который вы можете использовать для восстановления данных, если вся база данных Redis будет потеряна. Но учтите, что вы потеряете последние минуты данных, потому что вы обычно делаете моментальные снимки каждые пять минут или час, в зависимости от ваших потребностей.
AOF (только добавление файла)
В качестве альтернативы Redis использует нечто под названием AOF, что означает Append Only File (добавить только файл ). В этом случае каждое изменение сохраняется на диске для постоянного сохранения. При перезапуске Redis или после сбоя Redis воспроизведет журналы Append Only File, чтобы восстановить состояние. Таким образом, AOF более долговечен, но может быть медленнее, чем моментальный снимок.
Комбинация снимков и AOF
И, конечно, вы также можете использовать комбинацию AOF и снимков, где файл, предназначенный только для добавления, непрерывно сохраняет данные из памяти на диск, плюс у вас есть регулярные снимки между ними, чтобы сохранить состояние данных на случай, если вам понадобится восстановить их. Это означает, что даже если сама база данных Redis или серверы, базовая инфраструктура, на которой работает Redis, выйдут из строя, все ваши данные по-прежнему будут в безопасности, и вы можете легко воссоздать и перезапустить новую базу данных Redis со всеми данными.
Где находится это постоянное хранилище?
Очень интересный вопрос: где находится это постоянное хранилище? Так где же находится этот диск, на котором хранятся ваши снимки и журналы файлов только для добавления? Они находятся на тех же серверах, где работает Redis?
Этот вопрос на самом деле подводит нас к тенденции или лучшей практике сохранения данных в облачных средах, которая заключается в том, что всегда лучше отделить серверы, на которых работают ваши приложения и службы данных, от постоянного хранилища, в котором хранятся ваши данные.
Конкретный пример: если ваши приложения и сервисы работают в облаке, скажем, на экземпляре AWS EC2, вам следует использовать EBS или Elastic Block Storage для сохранения ваших данных вместо того, чтобы хранить их на жестком диске экземпляра EC2. Потому что если этот экземпляр EC2 умрет, у вас не будет доступа ни к одному из его хранилищ, будь то оперативная память, дисковое хранилище или что-то еще.

В результате, разделив эти два, если экземпляр сервера выйдет из строя или все экземпляры выйдут из строя, у вас все еще останется диск и все данные на нем. Вы просто раскручиваете другие экземпляры и берете данные из EBS, и все. Это значительно упрощает управление вашей инфраструктурой, поскольку каждый сервер равнозначен; у вас нет никаких специальных серверов с какими-либо специальными данными или файлами на нем. Поэтому вам не важно, потеряете ли вы всю свою инфраструктуру, поскольку вы можете просто воссоздать новый и извлечь данные из отдельного хранилища, и все будет готово.
Возвращаясь к примеру Redis, служба Redis будет работать на серверах и использовать оперативную память сервера для хранения данных, в то время как файлы журналов и моментальных снимков, предназначенные только для добавления, будут сохраняться на диске за пределами этих серверов, что сделает ваши данные более долговечными.
Оптимизация затрат с Redis на Flash
Теперь мы знаем, что вы можете сохранять данные с Redis для обеспечения долговечности и восстановления, используя оперативную память или хранилище памяти для высокой производительности и скорости. Поэтому у вас может возникнуть вопрос: не дорого ли хранить данные в памяти? Потому что вам понадобится больше серверов по сравнению с базой данных, которая хранит данные на диске, просто потому, что память ограничена по размеру. Существует компромисс между стоимостью и производительностью.
На самом деле, в Redis есть способ оптимизировать это с помощью сервиса Redis on Flash, который является частью Redis Enterprise.
Как работает Redis на Flash
На самом деле, это довольно простая концепция: Redis на Flash расширяет ОЗУ до флэш-накопителя или SSD, где часто используемые значения хранятся в ОЗУ, а редко используемые — на SSD. Так что для Redis это просто больше ОЗУ на сервере. Это означает, что Redis может использовать больше базовой инфраструктуры или базовых ресурсов сервера, используя как ОЗУ, так и SSD-диск для хранения данных, увеличивая емкость хранилища на каждом сервере и таким образом экономя расходы на инфраструктуру.
Масштабирование Redis: репликация и шардинг
Мы говорили о хранении данных для базы данных Redis и о том, как все это работает, включая лучшие практики. Теперь еще одна очень интересная тема — как нам масштабировать базу данных Redis?
Репликация и высокая доступность
Допустим, у моего экземпляра Redis заканчивается память, поэтому данные становятся слишком большими для хранения в памяти, или Redis становится узким местом и не может обрабатывать больше запросов. Как в таком случае увеличить емкость и размер памяти моей базы данных Redis?
У нас есть несколько вариантов для этого. Во-первых, Redis поддерживает кластеризацию, что означает, что у вас может быть основной или главный экземпляр Redis, который может использоваться для чтения и записи данных, и у вас может быть несколько реплик этого основного экземпляра для чтения данных. Таким образом, вы можете масштабировать Redis для обработки большего количества запросов и, кроме того, повысить высокую доступность вашей базы данных. Если главный экземпляр выходит из строя, одна из реплик может взять на себя управление, и ваша база данных Redis может в основном продолжать функционировать без каких-либо проблем.
Все эти реплики будут содержать копии данных основного экземпляра. Таким образом, чем больше у вас реплик, тем больше памяти вам нужно. И на одном сервере может не хватить памяти для всех ваших реплик. Плюс, если у вас все реплики на одном сервере, и этот сервер выйдет из строя, вся ваша база данных Redis пропадет, и у вас будет простой. Вместо этого вы хотите распределить эти реплики между несколькими узлами или серверами. Например, ваш главный экземпляр будет на одном узле, а две реплики на двух других узлах.
Шардинг для больших наборов данных
Ну, это кажется достаточно хорошим, но что, если ваш набор данных станет слишком большим, чтобы поместиться в памяти на одном сервере? Плюс, мы масштабировали чтения в базе данных, поэтому все запросы в основном просто запрашивают данные, но наш главный экземпляр все еще один и должен обрабатывать все записи. Так какое же решение здесь?
Для этого мы используем концепцию шардинга, которая является общей концепцией в базах данных и которую также поддерживает Redis. Шардинг в основном означает, что вы берете свой полный набор данных и делите его на более мелкие фрагменты или подмножества данных, где каждый шард отвечает за свое собственное подмножество данных.
Это означает, что вместо того, чтобы иметь один главный экземпляр, который обрабатывает все записи в полный набор данных; вы можете разделить его, скажем, на четыре шарда, каждый из которых отвечает за чтение и запись в подмножество данных. Каждому шарду также требуется меньший объем памяти, поскольку он содержит только четверть данных. Это означает, что вы можете распределять и запускать шарды на меньших узлах и, по сути, масштабировать свой кластер горизонтально. И, конечно, по мере роста вашего набора данных и необходимости еще большего количества ресурсов вы можете повторно разбить свою базу данных Redis, что по сути означает, что вы просто разбиваете свои данные на еще более мелкие фрагменты и создаете больше шардов.
Таким образом, наличие нескольких узлов, на которых запущено несколько реплик Redis, которые все сегментированы, дает вам очень производительную, высокодоступную базу данных Redis, которая может обрабатывать гораздо больше запросов, не создавая никаких узких мест.
Теперь я должен отметить, что эта настройка великолепна, но вам придется управлять ею самостоятельно, выполнять масштабирование, добавлять узлы, выполнять шардинг, а затем перешардинг и т. д. Для некоторых команд, которые больше сосредоточены на разработке приложений и бизнес-логике, а не на запуске и обслуживании служб данных, это может быть большим количеством нежелательных усилий. Поэтому, как более простая альтернатива, в Redis Enterprise вы получаете такую настройку автоматически, поскольку масштабирование, шардинг и т. д. управляются за вас.
Глобальная репликация с Redis: активно-активное развертывание
Давайте рассмотрим еще один интересный сценарий для приложений, которым требуется еще более высокая доступность и производительность в нескольких географических точках. Итак, предположим, что у нас есть этот реплицированный, шардированный кластер базы данных Redis в одном регионе, в центре обработки данных в Лондоне, Европа. Но у нас есть два следующих варианта использования:
- Наши пользователи географически распределены, поэтому они получают доступ к приложению со всего мира. Мы хотим распространить наши приложения и службы данных по всему миру, близко к пользователям, чтобы предоставить нашим пользователям лучшую производительность.
- Если, например, весь центр обработки данных в Лондоне, Европа, выйдет из строя, мы хотим немедленно переключиться на другой центр обработки данных, чтобы служба Redis оставалась доступной. Другими словами, мы хотим иметь копии всего кластера Redis в центрах обработки данных в нескольких географических точках или регионах.
Несколько кластеров Redis в разных регионах
Это означает, что отдельные данные должны быть реплицированы на множество кластеров, распределенных по нескольким регионам, при этом каждый кластер должен быть полностью способен принимать операции чтения и записи. В этом случае у вас будет несколько кластеров Redis, которые будут действовать как локальные экземпляры Redis в каждом регионе, и данные будут синхронизироваться по этим географически распределенным кластерам. Это функция, доступная в Redis Enterprise, и называется развертыванием «активный-активный», поскольку у вас есть несколько активных баз данных в разных местах.
При такой настройке у нас будет меньше задержек для пользователей. И даже если база данных Redis в одном регионе полностью выйдет из строя, другие регионы не будут затронуты. Если соединение или синхронизация между регионами прерываются на короткое время из-за какой-то сетевой проблемы, например, кластеры Redis в этих регионах могут обновлять данные независимо, и как только соединение будет восстановлено, они смогут снова синхронизировать эти изменения.
Разрешение конфликтов с CRDT
Конечно, когда вы это слышите, первый вопрос, который может возникнуть у вас в голове: как Redis разрешает изменения в нескольких регионах в одном и том же наборе данных? Итак, если одни и те же данные изменяются в нескольких регионах, как Redis гарантирует, что изменения данных любого региона не будут потеряны и данные будут правильно синхронизированы, и как он обеспечивает согласованность данных?
В частности, Redis Enterprise использует концепцию CRDTs, которая означает «conflict-free replicated Data types» (бесконфликтные реплицированные типы данных), и эта концепция используется для автоматического разрешения любых конфликтов на уровне базы данных и без потери данных. Таким образом, по сути, сам Redis имеет механизм для слияния изменений, которые были внесены в один и тот же набор данных из нескольких источников таким образом, что ни одно из изменений данных не теряется, а любые конфликты разрешаются должным образом. И поскольку, как вы узнали, Redis поддерживает несколько типов данных, каждый тип данных использует свои собственные правила разрешения конфликтов данных, которые являются наиболее оптимальными для этого конкретного типа данных.
Проще говоря, вместо того, чтобы просто переопределять изменения одного источника и отбрасывать все остальные, все параллельные изменения сохраняются и разумно разрешаются. Опять же, это автоматически делается для вас с помощью этой функции активной-активной георепликации, так что вам не нужно об этом беспокоиться.
Запуск Redis в Kubernetes
И последняя тема, которую разработчики DST Global хотят затронуть в Redis, — это запуск Redis в Kubernetes . Как я уже сказал, Redis отлично подходит для сложных микросервисов, которым необходимо поддерживать несколько типов данных и которым необходимо легкое масштабирование базы данных без беспокойства о согласованности данных. И мы также знаем, что новым стандартом для запуска микросервисов является платформа Kubernetes. Итак, запуск Redis в Kubernetes — очень интересный и распространенный вариант использования. Так как же это работает?
Redis с открытым исходным кодом на Kubernetes
С Redis с открытым исходным кодом вы можете развернуть реплицированный Redis как Helm chart или файлы манифеста Kubernetes и, по сути, используя правила репликации и масштабирования, о которых мы уже говорили, настроить и запустить высокодоступную базу данных Redis. Единственное отличие будет в том, что хосты, на которых будет работать Redis, будут модулями Kubernetes, а не, например, экземплярами EC2 или любыми другими физическими или виртуальными серверами. Но те же концепции шардинга, репликации и масштабирования применимы и здесь, когда вы хотите запустить кластер Redis в Kubernetes, и вам, по сути, придется управлять этой настройкой самостоятельно.
Redis Enterprise Оператор
Однако, как разработчики DST Global уже упоминали, многие команды не хотят прилагать усилия для поддержки этих сторонних сервисов, поскольку они предпочитают вкладывать свое время и ресурсы в разработку приложений или другие задачи. Поэтому наличие более простой альтернативы здесь также важно. Redis Enterprise имеет управляемый кластер Redis, который вы можете развернуть как оператор Kubernetes.
Если вы не знаете операторов, оператор в Kubernetes — это, по сути, концепция, в которой вы можете объединить все ресурсы, необходимые для работы определенного приложения или сервиса, чтобы вам не приходилось управлять им самостоятельно или вам не приходилось управлять им самостоятельно. Вместо того, чтобы человек управлял базой данных, у вас по сути есть вся эта логика в автоматизированной форме, чтобы управлять базой данных для вас. Во многих базах данных есть операторы для Kubernetes, и у каждого такого оператора, конечно, есть своя собственная логика, основанная на том, кто их написал и как они их написали.
Оператор Redis Enterprise on Kubernetes специально автоматизирует развертывание и настройку всей базы данных Redis в вашем кластере Kubernetes. Он также занимается масштабированием, созданием резервных копий и восстановлением кластера Redis при необходимости и т. д. Таким образом, он берет на себя полную работу кластера Redis внутри кластера Kubernetes.
Redis как основная база данных для сложных приложений
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Одним из самых фундаментальных и критически важных решений при создании современного приложения является выбор технологии для хранения данных. Этот выбор, часто стоящий перед архитекторами и разраб...
Выбор правильной базы данных является критически важным выбором при создании люб...
В этой статье разработчиками компании DST Global, ...
Программное обеспечение хранилища данных помогает ...
В этой статье разработчики компании DST Global ...
Двоичное квантование в векторных базах данных повы...
В этой статье вы узнаете от разработчиков компании...
Узнайте о преимуществах от разработчиков компании ...
Oracle — самая популярная база данных в мире...
Повысьте производительность и масштабируемость, ис...
Вот плюсы и минусы использования redis.
Плюсы
— Быстрый
— транзакция (поскольку однопоточная)
Минусы
— Отсутствие поддержки вторичного ключа
— Нет поддержки переиндексации
— Нет надежных потоков изменений, в отличие от mongodb, dynamodb
— Стоимость (поскольку все данные должны храниться в памяти, нам нужно всё больше и больше оперативной памяти)
— Нет надёжного сохранения данных. (P.S. Люди говорят, что моментальный снимок rdb служит резервным хранилищем для Redis, но помогите мне понять, что происходит, когда у нас 12 ГБ оперативной памяти и мы помещаем 13 ГБ данных. В Redis будет только 12 ГБ данных, но если я использую моментальный снимок rdb и запускаю другой Redis с 20 ГБ оперативной памяти, будут ли в нём все мои данные или 1 ГБ исчезнет навсегда. Насколько надёжен этот механизм??)
— Отсутствует автоматическая балансировка ключей. (сегментирование на уровне приложения является обязательным)
Учитывая вышеперечисленные плюсы и минусы, я вижу лишь несколько вариантов использования, при которых мы можем использовать Redis в качестве единственного и основного хранилища данных.
— Хранилище сеансов.
Я что-нибудь упускаю? Каких дополнительных возможностей не хватает redis по сравнению с другими базами данных, такими как mongodb, mysql (Здесь я говорю только о готовности к производству и надежности, а не о том, чтобы начинать дебаты nosql vs sql
Итак, для чего может подойти Redis? Redis может подойти для хранения таких данных, как состояние сеанса приложения. Как правило, это небольшие объёмы информации, и в случае сбоя Redis риск невелик (возможно, в худшем случае некоторым пользователям придётся снова войти в систему).
Точнее всего описать Redis можно, сказав, что это — сервер структур данных. Уникальные особенности сервера Redis стали основной причиной его популярности и того, что он применяется во множестве реальных проектов.
Вместо того чтобы работать со строками базы данных, перебирать, сортировать, упорядочивать их, что если информация с самого начала будет находиться в структурах данных, которые нужны программисту? Первое время Redis использовали практически так же, как Memcached. Но, по мере развития Redis, эта система управления базами данных (СУБД) нашла применение и во многих других ситуациях. В частности — в реализациях механизма издатель/подписчик, в задачах потоковой обработки данных, в системах, где нужно работать с очередями.
Вот какие типы данных поддерживает Redis:
— Строка (String)
— Битовый массив (Bitmap)
— Битовое поле (Bitfield)
— Хеш-таблица (Hash)
— Список (List)
— Множество (Set)
— Упорядоченное множество (Sorted set)
— Геопространственные данные (Geospatial)
— Структура HyperLogLog (HyperLogLog)
— Поток (Stream)
Redis — это база данных, размещаемая в памяти, которая используется, в основном, в роли кеша, находящегося перед другой, «настоящей» базой данных, вроде MySQL или PostgreSQL. Кеш, основанный на Redis, помогает улучшить производительность приложений. Он эффективно использует скорость работы с данными, характерную для памяти, и смягчает нагрузку центральной базы данных приложения, связанную с обработкой следующих данных:
— Данные, которые редко меняются, к которым часто обращается приложение.
— Данные, не относящиеся к критически важным, которые часто меняются.
Примеры таких данных могут включать в себя сессионные кеши или кеши данных, а так же содержимое панелей управления — вроде списков лидеров и отчётов, включающих в себя данные, агрегированные из разных источников.
Но во многих случаях Redis гарантирует достаточно высокий уровень сохранности данных, что позволяет использовать эту СУБД в роли настоящей основной базы данных. А добавление в систему плагинов Redis и различных конфигураций высокой доступности (High Availability, HA) делает базу данных Redis крайне интересной для определённых сценариев использования и рабочих нагрузок.
Ещё одна важная особенность Redis заключается в том, что эта СУБД размывает границы между кешем и хранилищем данных. Тут важно понять то, что чтение данных из памяти и работа с данными, находящимися в памяти, гораздо быстрее чем те же операции, выполняемые традиционными СУБД, использующими обычные жёсткие диски (HDD) или твердотельные накопители (SSD).
Изначально Redis чаще всего сравнивали с Memcached, с системой, в которой тогда не было и намёка на долговременное хранение данных.
Хранилище Memcached создал в 2003 году Брэд Фицпатрик. Оно появилось на 6 лет раньше Redis. Сначала это был Perl-проект, а позже его переписали на C. В своё время Memcached был стандартным инструментом кеширования. Главные различия между ним и Redis заключаются в том, что в Memcached имеется меньше типов данных, и в ограничениях, связанных с политикой вытеснения ключей. Memcached поддерживает лишь политику LRU (Least Recently Used), когда первыми вытесняются данные, которые не использовались дольше всех.
Ещё одно отличие этих хранилищ заключается в том, что Redis — это однопоточная система, а Memcached — многопоточная. Memcached может показывать отличные результаты производительности в ограниченных окружениях кеширования. А при использовании этой системы в распределённом кластере нужны дополнительные настройки. Redis же поддерживает подобные сценарии работы сразу после установки.
В наши дни Redis поддерживает настройку того, как именно данные сохраняются на диск. А в самом начале эта система использовала снепшоты, когда асинхронные копии данных, находящихся в памяти, отправляли на диск для долговременного хранения. К сожалению, у этого механизма имеется недостаток, выражающийся в возможной потере данных, изменённых или добавленных в хранилище на временных интервалах между снепшотами.
Хранилище Redis, с момента его появления в 2009 году, серьёзно развилось. Мы рассмотрим большую часть архитектурных и топологических решений, характерных для Redis, что позволит вам, изучив эту систему, включить её в состав своего арсенала систем хранения данных.
Архитектура Redis
Прежде чем мы начнём разговор о внутренних механизмах Redis — рассмотрим различные варианты развёртывания этого хранилища и обсудим компромиссы, на которые приходится идти тем, кто выбирает тот или иной вариант.
Мы, в основном, уделим внимание следующим конфигурациям:
— Единственный экземпляр Redis.
— Redis HA.
— Redis Sentinel.
— Redis Cluster.
Вы можете выбрать ту или иную конфигурацию в зависимости от особенностей вашего проекта и его масштабов.
Единственный экземпляр Redis
Самый простой вариант развёртывания Redis — это использование одного экземпляра системы. При таком подходе в распоряжении пользователя оказывается небольшое хранилище, которое поможет проекту расти и развиваться и ускорит сервисы этого проекта. Но у такого способа использования Redis есть и недостатки. Например, если используемый в проекте экземпляр Redis даст сбой или окажется недоступным — все обращения клиентов к Redis окажутся неудачными, в результате упадёт общая производительность и скорость работы системы.
Если дать экземпляру Redis достаточно памяти и серверных ресурсов, этот экземпляр может оказаться довольно-таки мощной сущностью. Такой подход, в основном, используется для кеширования, позволяет, потратив минимум сил и времени на настройку системы, получить серьёзный рост производительности проекта. При наличии достаточных серверных ресурсов развернуть подобный сервис Redis можно на той же машине, на которой работает основное приложение.
Для обеспечения успешной работы с Redis важно понимать некоторые концепции этой системы, связанные с управлением данными. Запросы, поступающие к базе данных Redis, обрабатываются путём работы с данными, хранящимися в памяти. Если используемый экземпляр Redis предусматривает применение постоянного хранения данных, в системе будет форк процесса. Он использует RDB (Redis Database, база данных Redis) для организации постоянного хранения снепшотов (снимков) данных. Это — весьма компактное представление данных Redis на определённый момент времени. Вместо RDB могут использоваться файлы, предназначенные только для добавления данных (Append-Only File, AOF).
Эти два механизма позволяют Redis иметь долговременное хранилище данных, поддерживать различные стратегии репликации, помогают реализовывать на базе Redis более сложные топологии. Если сервер Redis не настроен на постоянное хранение данных, то, при перезагрузке или сбое системы, данные теряются. Если же постоянное хранение включено, то при перезагрузке системы осуществляется загрузка в память данных из снепшота RDB или из AOF. После этого экземпляр Redis сможет обрабатывать запросы клиентов.
Учитывая вышесказанное — рассмотрим конфигурации Redis, которые характеризуются, так сказать, большей распределённостью, чем рассмотренная.
Redis HA
Ещё одна популярная конфигурация Redis представляет собой систему, состоящую из ведущего и подчинённого узлов, состояние которых синхронизируется посредством репликации. По мере того, как данные записываются в ведущем экземпляре Redis, копии соответствующих команд отправляются в выходной буфер для подчинённых узлов, что обеспечивает выполнение репликации данных. В состав подчинённых узлов может входить один или большее количество экземпляров Redis. Эти экземпляры способны помочь в масштабировании операций чтения данных или обеспечить отказоустойчивость системы при потере связи с ведущим узлом.
«Высокая доступность» (HA, High Availability) — это характеристика системы, которая нацелена на обеспечение согласованного уровня показателей её деятельности (обычно — времени безотказной работы системы) на временных интервалах, превышающих средние.
В системах высокой доступности важно отсутствие единой точки отказа. Это позволяет им корректно и быстро восстанавливать нормальную работу после сбоев. Конфигурации высокой доступности предусматривают наличие надёжных линий связи, что исключает потерю данных при их передаче от ведущего узла к подчинённому. Кроме того, в таких системах осуществляется автоматическое обнаружение сбоев и восстановление после них.
Так как теперь мы перешли к распределённым системам, с которыми связано множество заблуждений, нам нужно ознакомиться с несколькими новыми понятиями. То, что раньше было простым и ясным, теперь становится сложнее.
Репликация данных в Redis
Каждый ведущий узел Redis имеет идентификатор (ID) и смещение репликации. Эти два показателя чрезвычайно важны для того, чтобы выяснить момент времени, когда подчинённый узел может продолжать процесс репликации, или чтобы определить, что необходимо выполнить полную синхронизацию данных. Смещение инкрементируется при выполнении любого действия, которое происходит в ведущем узле Redis.
Если описать это более конкретно, то окажется, что когда подчинённый узел Redis отстаёт лишь на несколько шагов смещения от ведущего узла, он получает оставшиеся необработанными команды от ведущего узла, эти команды применяются к данным, так происходит до момента синхронизации узлов. Если два экземпляра не могут договориться об ID репликации, или ведущий узел не имеет сведений о смещении, подчинённый узел запрашивает полную синхронизацию данных. Сюда входит создание ведущим узлом нового снепшота RDB и отправка его подчинённому узлу. В процессе передачи этих данных ведущий узел буферизует промежуточные обновления данных, произошедшие между моментом создания снепшота и текущим моментом. Эти обновления будут отправлены подчинённому узлу после того, как он синхронизируется со снепшотом. После завершения этого процесса репликация может продолжаться в обычном режиме.
Если у разных экземпляров Redis имеются одинаковые ID и смещение, это значит, что они хранят в точности одни и те же данные. Тут может появиться вопрос о том, почему в Redis используется ID репликации. Дело в том, что когда уровень экземпляра Redis повышается до ведущего узла, или если экземпляр сразу запускается как ведущий, ему назначается новый ID репликации. Он используется для выяснения того, какой экземпляр Redis был до этого ведущим. А именно, выясняется то, из какого экземпляра раньше копировал данные узел, уровень которого был только что повышен. Это даёт возможность выполнения частичной синхронизации (с другими подчинёнными узлами), так как новый ведущий узел помнит свой старый ID репликации.
Например, два экземпляра Redis, ведущий и подчинённый, имеют один и тот же ID репликации, а их смещения отличаются на несколько сотен команд. То есть — если на «отстающем» экземпляре воспроизвести соответствующие команды, в распоряжении обоих экземпляров будет идентичный набор данных. Предположим, что ID репликации экземпляров различаются и нам неизвестен предыдущий ID (у экземпляров нет общего предка) узла, уровень которого недавно понижен до подчинённого (он подключён к ведущему узлу). В такой ситуации нужно выполнить ресурсозатратную операцию полной синхронизации данных.
С другой стороны, если предыдущий ID репликации известен — мы можем подумать о том, как синхронизировать данные двух узлов. Так как нам известен общий предок узлов, это значит, что они хранят общие данные, а значит, воспользовавшись смещением, мы можем провести частичную синхронизацию данных.
Redis Sentinel
Redis Sentinel — это сервис, обеспечивающий создание распределённых систем. И, как и в случае со всеми распределёнными системами, у Sentinel имеются и сильные, и слабые стороны. В основе Sentinel лежит кластер Sentinel-процессов, работающих совместно. Они координируют состояние системы, реализуя конфигурацию высокой доступности Redis. Sentinel — это сервис, защищающий хранилище Redis от сбоев. Поэтому логично то, чтобы этот сервис не имел бы единой точки отказа.
Сервис Sentinel решает несколько задач. Во-первых — он обеспечивает работоспособность и доступность текущих ведущих и подчинённых узлов. Благодаря этому текущий Sentinel-процесс (вместе с другими подобными процессами) может отреагировать на ситуацию, когда теряется связь с ведущими и/или подчинёнными узлами. Во-вторых — он играет определённую роль в деле обнаружения сервисов. Похожим образом в других системах работают Zookeeper и Consul. То есть — когда новый клиент пытается что-то записать в хранилище Redis, Sentinel сообщит клиенту о том, какой экземпляр Redis в этот момент является ведущим.
Получается, что узлы Sentinel постоянно мониторят доступность экземпляров Redis и отправляют сведения о них клиентам, что позволяет клиентам предпринимать определённые действия в тех случаях, когда хранилище даёт сбой.
Вот какие функции выполняют узлы Sentinel:
— Мониторинг. Обеспечение того, что ведущие и подчинённые узлы работают так, как ожидается.
— Отправка уведомлений администраторам. Система отправляет администраторам уведомления о происшествиях в экземплярах Redis.
— Управление восстановлением системы после отказа. Узлы Sentinel могут запустить процесс восстановления системы после сбоя в том случае, если ведущий экземпляр Redis недоступен и достаточное количество (кворум) узлов согласно с тем, что это так.
— Управление конфигурацией. Узлы Sentinel, кроме того, играют роль системы, позволяющей обнаруживать текущий ведущий экземпляр Redis.
Использование Redis Sentinel для решения вышеописанных задач позволяет обнаруживать сбои Redis. Процедура обнаружения сбоя включает в себя получение согласия нескольких узлов Sentinel с тем, что текущий ведущий экземпляр Redis недоступен. Процесс получения такого согласия называют кворумом (quorum). Это позволяет повысить надёжность системы, защититься от ситуаций, когда один из процессов ведёт себя неправильно и не может подключиться к ведущему узлу Redis.
Кворум — это минимальное число голосов, которое нужно получить распределённой системе для того, чтобы ей было бы позволено выполнять определённые операции, наподобие восстановления после сбоя. Это число поддаётся настройке, но оно должно отражать количество узлов в рассматриваемой распределённой системе. Размеры большинства распределённых систем равняются трём или пяти узлам, в них, соответственно, кворум равен двум или трём голосам. Нечётные количества узлов предпочтительны в случаях, когда системе необходимо разрешать неоднозначности.
У Redis Sentinel есть и недостатки. Поэтому мы рассмотрим несколько рекомендаций и практических советов, касающихся этого сервиса.
Redis Sentinel можно развернуть несколькими способами. Честно говоря, чтобы дать какие-то адекватные рекомендации, мне нужны подробности о той системе, в составе которой планируется использовать Redis Sentinel. В качестве общего правила я посоветовал бы запускать узел Sentinel вместе с каждым из серверов приложения (если это возможно). Это позволит не обращать внимания на различия, связанные с сетевыми подключениями узлов Sentinel и клиентов, которые используют Redis.
Sentinel можно запустить и на тех же машинах, на которых работают экземпляры Redis, или даже в виде независимых узлов, но это, в различных формах, усложняет ситуацию. Рекомендую применять как минимум три узла с кворумом, как минимум, из двух. Вот простая таблица, в которой описано количество серверов в кластере, даны сведения о кворуме и о количестве допустимых отказов.
Подобные показатели будут, от системы к системе, различаться, но общая идея остаётся подобной той, что выражена в таблице.
Подумаем о том, что может пойти не так в системе, в которой используется Sentinel. Если такая система будет работать достаточно долго — можно столкнуться со всеми этими проблемами.
— Что если узлы Sentinel выйдут из состава кворума?
— Что если сеть разделится и старый ведущий экземпляр Redis окажется в меньшей группе узлов Sentinel? Что произойдёт с данными, записанными в этот экземпляр Redis? (Подсказка: эти данные, после полного восстановления системы, будут утеряны.)
— Что произойдёт, если сетевые топологии узлов Sentinel и клиентских узлов (узлов приложения) окажутся несогласованными?
У нас нет гарантий устойчивости системы, особенно учитывая то, что операции по сохранению данных на диск (об этом — ниже) выполняются асинхронно. Тут ещё имеется неприятная проблема, связанная с тем, когда именно клиенты узнают о появлении новых ведущих узлов. Сколько команд записи данных уйдут в никуда, будучи отправленными в ситуации, когда новый ведущий узел неизвестен? Разработчики Redis рекомендуют запрашивать сведения о новом ведущем узле при установлении новых соединений. Это, что зависит от конфигурации системы, может приводить к серьёзным потерям данных.
Есть несколько способов уменьшить масштабы потерь данных в том случае, если принудить ведущий экземпляр Redis к репликации операций записи на как минимум один подчинённый экземпляр. Помните о том, что репликация в Redis выполняется асинхронно, и что у неё есть свои недостатки. Поэтому понадобится независимо отслеживать подтверждения получения данных, а если не удастся получить подтверждение от хотя бы одного подчинённого узла, главный узел должен прекратить принимать запросы на запись данных.
Redis Cluster
Уверен, что многие размышляют о том, как быть в том случае, если не получится хранить все необходимые данные в памяти на одной машине. В наши дни максимальный объём оперативной памяти, доступный на одном сервере, составляет 24 ТиБ, такие конфигурации есть в AWS. Понятно, что это много, но некоторым системам этого не хватит даже для организации кеша.
Redis Cluster позволяет горизонтально масштабировать хранилища Redis.
По мере роста некоей системы её владелец может выбрать один из следующих трёх вариантов действий:
— Меньше работать (никто так не поступает, потому что мы — ненасытные монстры).
— Повышать мощность отдельных компьютеров.
— Распределять нагрузку на большее количество небольших компьютеров.
Серьёзно мы отнесёмся лишь к двум последним пунктам этого списка. Они, соответственно, известны как вертикальное и горизонтальное масштабирование. При вертикальном масштабировании для ускорения работы системы используют более продвинутые компьютеры, надеясь, что возросшая вычислительная мощность позволит успешно справляться с растущей нагрузкой. Но, даже если на первых порах ожидания и оправдаются, в итоге тот, кто пользуется вертикальным масштабированием, столкнётся с ограничениями аппаратного обеспечения.
После того, как вертикальное масштабирование себя исчерпало (а скорее всего, хочется надеяться, задолго до этого), нужно будет обратиться к горизонтальному масштабированию. Это — распределение нагрузки по множеству небольших машин, ответственных за решение небольших подзадач одной большой задачи.
Разберёмся с терминологией. После того, как мы решили использовать Redis Cluster, это будет значить, что мы решили распределить хранимые нами данные по множеству машин. Это называют шардингом. В результате каждый экземпляр Redis, входящий в состав кластера, считается хранилищем шарда, или фрагмента, всех данных.
Такой подход вызывает к жизни новую проблему. Если отправить в кластер данные — как узнать о том, какой именно экземпляр Redis (шард) хранит эти данные? Есть несколько способов это сделать. Redis Cluster использует алгоритмический шардинг.
Для того чтобы найти шард для заданного ключа, мы хешируем ключ, а результат делим по модулю на количество шардов. Затем, используя детерминистическую хеш-функцию (благодаря этому конкретный ключ всегда будет соответствовать одному и тому же шарду), мы, когда нужно будет прочитать соответствующие данные, сможем узнать о том, где именно они хранятся.
Что произойдёт, если через некоторое время в систему будет добавлен новый шард? А произойдёт то, что называют решардингом.
Исходя из предположения о том, что ключ foo был назначен шарду 0, он, после решардинга, может быть назначен шарду 5. Но перемещение данных ради того, чтобы их размещение соответствовало бы новой конфигурации шардов, окажется медленной и нереалистичной задачей в том случае, если мы хотим, чтобы операции по увеличению хранилища выполнялись бы быстро. Такое перемещение данных, кроме того, окажет негативное влияние на доступность Redis Cluster.
В рамках Redis Cluster создан механизм, направленный на решение этой проблемы. Это — так называемые «хеш-слоты», в которые и отправляют данные. Имеется около 16 тысяч таких слотов. Это даёт нам адекватный способ распределения данных по кластеру, а при добавлении новых шардов нужно просто переместить в системе хеш-слоты. Поступая так, нам нужно лишь перемещать хеш-слоты из шарда в шард и упростить процесс добавления новых ведущих экземпляров Redis в кластер.
Сделать это можно без простоев системы и с минимальным воздействием на её производительность. Рассмотрим пример.
Узел M1 содержит хеш-слоты с 0 по 8191.
Узел M2 содержит хеш-слоты с 8192 по 16383.
Назначая хеш-слот ключу foo, мы вычисляем детерминистический хеш от ключа (foo) и делим по модулю на количество хеш-слотов (16383). В результате данные, соответствующие этому ключу, попадают на узел M2. Теперь, предположим, мы добавляем в систему новый узел — M3. Новое соответствие узлов и хеш-слотов будет таким:
Узел M1 содержит хеш-слоты с 0 по 5460.
Узел M2 содержит хеш-слоты с 5461 по 10922.
Узел M3 содержит хеш-слоты с 10923 по 16383.
Все ключи, которые попали в хеш-слоты узла M1, теперь принадлежащие узлу M2, понадобилось бы перенести. Но соответствие отдельных ключей и хеш-слотов сохраняется, так как ключи уже распределены по хеш-слотам. Таким образом данный механизм решает проблему решардинга при использовании алгоритмического шардинга.
Протокол Gossip
Redis Cluster использует протокол Gossip для определения общего состояния кластера. На вышеприведённой иллюстрации имеется 3 ведущих (M) узла и 3 подчинённых (S) узла. Все эти узлы постоянно обмениваются друг с другом информацией для того чтобы знать о том, какие шарды доступны и готовы обрабатывать запросы. Если достаточное количество шардов согласно с тем, что узел M1 не отвечает на запросы, они могут решить повысить S1 — подчинённый узел узла M1, до уровня ведущего узла, чтобы поддержать кластер в работоспособном состоянии. Количество узлов, необходимое для запуска подобной процедуры, поддаётся настройке. Очень важно правильно выполнить подобную настройку. Если сделать что-то не так, можно оказаться в ситуации, когда кластер окажется разделённым на части в том случае, если он не сможет разрешить неоднозначную ситуацию, когда «за» и «против» голосует одинаковое количество систем. Этот феномен называют «split brain» (разделение вычислительных мощностей). Поэтому, в качестве общего правила, важно, чтобы в кластере было бы нечётное количество ведущих узлов, у каждого из которых имеется два подчинённых узла. Это послужит хорошей основой для построения надёжной системы.
Модели постоянного хранения данных в Redis
Если в Redis планируется размещать какие-либо данные в расчёте на их надёжное постоянное хранение, важно понимать то, как именно это организовано в Redis. Существует множество ситуаций, когда потеря данных, хранящихся в Redis — это не такая уж и катастрофа. Например — использование Redis в роли кеша, или в ситуациях, когда в Redis хранятся данные некоей аналитической системы реального времени.
В других случаях разработчикам нужны некие гарантии относительно постоянного хранения данных и возможности их восстановления.
Redis — быстрое хранилище, а все гарантии относительно целостности данных второстепенны в сравнении со скоростью. Это, вероятно, спорная тема, но, на самом деле, так оно и есть.
Постоянное хранение данных не используется
Если нужно — постоянное хранение данных можно отключить. Это — конфигурация, при использовании которой Redis работает быстрее всего, но при этом не гарантируется надёжное хранение данных.
RDB-файлы
Постоянное хранение данных в файлах RDB подразумевает создание снепшотов, содержащих данные, актуальные на определённые моменты времени. Снепшоты создаются с заданными временными интервалами.
Главный минус этого механизма заключается в том, что данные, поступившие в хранилище между моментами создания снепшотов, будут, при сбое Redis, утеряны. Кроме того, этот механизм хранения данных полагается на создание форка главного процесса. При работе с большими наборами данных это может привести к кратковременным задержкам в обработке запросов. Но, при этом, RDB-файлы загружаются в память гораздо быстрее, чем AOF.
AOF
Механизм постоянного хранения данных, основанный на AOF, осуществляет журналирование каждой операции записи, запрос на выполнение которой получает сервер. Эти операции будут воспроизведены при запуске сервера, что приведёт к воссозданию исходного набора данных.
Такой подход к постоянному хранению данных гораздо надёжнее RDB. Ведь речь идёт не о снимках состояния хранилища, а о файлах, рассчитанных только на присоединение к ним данных. Когда происходят операции, их буферизуют в журнале, но они не оказываются сразу после этого размещёнными в постоянном хранилище. В журнале содержатся реальные команды, которые, если нужно восстановить данные, запускают в том порядке, в котором они выполнялись.
Затем, когда это возможно, журнал сбрасывают на диск с помощью fsync (то, когда именно запускается этот процесс, поддаётся настройке). После этого данные оказываются в постоянном хранилище. Минус этого подхода в том, что такой формат хранения данных не является компактным, он требует больше места на диске, чем RDB-файлы.
Вызов fsync() переносит («сбрасывает») все модифицированные данные из памяти (то есть — модифицированные страницы файлового буфера), имеющие отношение к файлу, представленному файловым дескриптором fd, на дисковое устройство (или на другое устройство для постоянного хранения информации). В результате вся изменённая информация может быть восстановлена даже после серьёзного сбоя или перезагрузки системы.
По разным причинам изменения, которые вносят в открытый файл, сначала попадают в кеш, а вызов fsync() гарантирует то, что они будут физически сохранены на диск, то есть — позже их можно будет с диска прочитать.
— Включите AOF (хранилище файлов только для добавления) см. документацию по AOF. Это позволит вести журнал всех команд Redis, выполняемых с вашим набором данных, в режиме реального времени.
— Запускайте Redis с помощью репликации Master-Slave см. документацию по репликации. Это позволит обеспечить высокую доступность в случае сбоя одного из ваших экземпляров.
— Если вы используете что-то вроде EC2, вы можете использовать EBS для резервного копирования раздела Redis, чтобы обеспечить дополнительный уровень защиты от сбоев инстанса.
На горизонте маячит Redis Cluster — это специально разработанная система для запуска Redis, которая должна помочь с высокой доступностью и масштабируемостью. Однако она появится не раньше, чем через полгода.
Но все же я не уверен, что redis еще не в состоянии действительно хранить в нем критически важные данные (пока?). Если, например, это не большая проблема, когда появляется еще 1 твит (twitter.com ) или что-то подобное приведет к потерям, тогда я бы обязательно использовал redis. Также много информации о постоянстве доступно на собственном веб-сайте redis.
Вам также следует знать о некоторых проблемах с сохранением данных, которые могут возникнуть при чтении статьи в блоге antirez (разработчиков Redis). Вам стоит почитать его блог, потому что у него есть несколько интересных статей.
Плюсы:
— Redis был непревзойденным по производительности. Мы получали 10 000 транзакций в секунду «из коробки» (обратите внимание, что одна транзакция включала в себя несколько команд Redis). После нескольких оптимизаций и использования скриптов LUA мы смогли достичь скорости 25 000+ транзакций в секунду. Таким образом, когда дело касается производительности на один сервер, Redis не имеет себе равных.
— Redis очень прост в настройке и имеет очень небольшую кривую обучения по сравнению с другими хранилищами данных SQL и NoSQL.
Минусы:
— Redis поддерживает лишь несколько примитивных структур данных, таких как хэши, множества, списки и т. д., а также операции с этими структурами данных. Этого более чем достаточно, если вы используете Redis в качестве кэша, но если вы хотите использовать Redis в качестве полноценного хранилища данных, вы будете ограничены в возможностях. Нам было сложно моделировать наши требования к данным с помощью этих простых типов.
— Самая большая проблема, с которой мы столкнулись при работе с Redis, — это отсутствие гибкости. Как только вы определяете структуру своих данных, любые изменения в требованиях к хранилищу или шаблонах доступа практически требуют переосмысления всего решения. Не уверен, что это относится ко всем хранилищам данных NoSQL (я слышал, что MongoDB более гибкая, но сам её не использовал).
— Поскольку Redis работает в однопоточном режиме, загрузка процессора очень низкая. Вы не можете разместить несколько экземпляров Redis на одном компьютере, чтобы повысить загрузку процессора, так как они будут конкурировать за один и тот же диск, что приведёт к его перегрузке.
— Отсутствие горизонтальной масштабируемости — это проблема, о которой упоминалось в других ответах.
Конечно, вы можете распределить большие данные по нескольким экземплярам Redis, но вам придётся делать это вручную. Обычно эта операция выполняется следующим образом (при условии, что изначально у вас есть только один экземпляр):
— Используйте механизм «ведущий-ведомый» для репликации данных на второй компьютер. Теперь у вас есть две копии одних и тех же данных.
— Оборвите соединение между ведущим и ведомым устройством.
— Удалите первую половину (разделенную с помощью хеширования и т. д.) данных на первом компьютере и удалите вторую половину данных на втором компьютере.
— Скажите всем клиентам (PHP, C и т. д.) работать на первом компьютере, если указанные ключи находятся на этом компьютере, в противном случае работайте на втором компьютере.
Именно так масштабируется Redis! Вам также нужно остановить свой сервис, чтобы предотвратить запись данных во время миграции.
Исходя из нашего опыта, мы пришли к следующему выводу о Redis: Redis не подходит для хранения более 30 ГБ данных, Redis не масштабируется, Redis вполне подходит для разработки прототипов.
Позже мы нашли альтернативу Redis — SSDB(github.com/ideawu/ssdb), сервер уровня БД, который поддерживает почти все API-интерфейсы Redis и подходит для хранения более 1 ТБ данных, что зависит только от размера вашего жёсткого диска.