

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Технический подход DST Global, к разработке расширяемой и масштабируемой структуры обработки данных

В этой статье разработчики DST Global обсуждают и предлагают несколько вариантов решения проблем распределенной обработки и разработки эффективной и оптимизированной структуры.
Современные приложения распределенной обработки данных предоставляют тщательно подобранные и краткие наборы выходных данных для последующей аналитики для создания оптимизированных информационных панелей и отчетов для поддержки нескольких групп заинтересованных сторон для принятия обоснованных решений. Выходные данные конвейера обработки данных должны соответствовать цели, а также предоставлять обобщенную и точную информацию из внутреннего конвейера обработки данных. Таким образом, промежуточное программное обеспечение обработки данных становится основой этих аналитических приложений, позволяющих получать объемные наборы данных из нескольких восходящих потоков и обрабатывать сложную аналитическую логику для получения обобщенных результатов, которые затем используются аналитическими механизмами для создания различных видов отчетов и информационных панелей для различных целей. Наиболее широко определенная цель этих аналитических систем перечислена ниже:
1. Приложение прогнозирования для прогнозирования результатов на будущее на основе исторической тенденции для определения будущих стратегий организации.
2. Отчетность для высшего руководства для отображения эффективности работы организации и оценки прибыльности.
3. Отчетность перед внешними заинтересованными сторонами о деятельности компаний и рекомендации на будущее.
4. Нормативная отчетность перед внешними и внутренними регуляторами.
5. Различные виды отчетности по комплаенсу и рискам.
6. Предоставляйте обработанные и обобщенные результаты специалистам по данным, администраторам данных и инженерам данных, чтобы помочь им в анализе данных.
У организации может быть гораздо больше потребностей, которым потребуются результаты аналитической обработки для создания обобщенной информации, которая будет использоваться аналитическим приложением для создания отчетов, диаграмм и информационных панелей.
Учитывая все эти критически важные потребности в аналитике, обработка необработанных данных организаций для получения жизненно важных результатов имеет очень важное значение и становится главным проектом для всех крупных и средних организаций.
Опять же, экосистема обработки аналитики для организаций должна быть достаточно расширяемой и гибкой, чтобы реагировать на меняющиеся требования к обработке, а производительность является еще одним решающим фактором в обработке объемных данных для получения результатов в соответствии с данным агрессивным соглашением об уровне обслуживания, начиная от почасовых и ежедневных. , еженедельно, ежемесячно, ежеквартально с различной периодичностью для разных наборов потребностей в аналитике и отчетности.
При этом для организации очень важно разработать приложение для обработки аналитических данных таким образом, чтобы оно могло быстро адаптироваться к любым изменениям в требованиях к обработке и реагировать на изменения очень гибко с минимальными усилиями и нарушением работы других частей конечного продукта. конечный конвейер обработки. Первоочередное внимание уделяется определению наилучшего оптимального способа структурирования логики обработки для приложения обработки аналитики. Гибкость изменения логики обработки станет основой этих приложений и может помочь пользователям изменять логику и включать любые новые требования в шаблон обработки с минимальными усилиями и с более быстрым временем обработки для реагирования на изменения. Рекомендуется отделить логику обработки от механизма обработки, чтобы обеспечить четкое разделение задач и ответственности для группы внедрения, управляющей логикой обработки аналитики и сосредотачивающейся на ней, а также группы, управляющей структурой механизма обработки, чтобы сосредоточиться на поддержании структура обработки бесшовная и гибкая. Это поможет лучше поддерживать структуры, а также будет иметь меньшее количество смешанной логики обработки и упрощенный подход к аналитической обработке. Другие моменты, которые следует учитывать при выборе подхода, — это то, как приложение работает с наборами данных большого объема и как часто базовая логика обработки будет подвергаться каким-либо изменениям в зависимости от изменения бизнес-требований к логике обработки. У нас есть различные способы проектирования и проектирования этих аналитических приложений, некоторые из которых перечислены ниже, и у нас может быть больше способов разработки приложения. Здесь мы перечисляем лишь несколько распространенных и известных подходов к проектированию, в этой статье мы сосредоточимся на одном подходе.
1. Приложение может быть разработано как монолитное, где логика находится в форме кода и потребует изменения кода для любого изменения требований к обработке.
2. Приложение разработано с использованием аналитической базы данных с мгновенной эластичной масштабируемостью и возможностью сочетания облачных функций с механизмом запросов SQL.
3. Приложение разработано как приложение распределенной обработки, которое может масштабироваться горизонтально для удовлетворения потребностей обработки.
4. Приложение должно быть разработано как набор несвязной и несвязанной логики, которая будет выполняться в указанном порядке. Слабосвязанная логика может быть структурирована либо в виде чистого кода с использованием любого языка программирования, либо в виде настраиваемого выражения на основе метаданных, в зависимости от того, как часто она будет подвергаться изменениям. Опять же, выбор структурирования логики либо в виде настраиваемой логики, либо в форме чистого кода, либо в форме гибрида будет выбором группы реализации для повышения удобства сопровождения приложения.
В этой статье мы сосредоточимся конкретно на четвертом подходе, упомянутом выше, и объясним его подробно, а также приведем несколько иллюстраций и примеров.
Самый большой вопрос здесь заключается в том, как мы можем разработать удобное в сопровождении решение, которое сможет очень гибко реагировать на любые изменения и соответствовать жестким срокам соглашения об уровне обслуживания.
Разработчик приложения при реализации логики обработки должен будет рассмотреть наилучший оптимальный способ внедрения этой логики. Им нужно будет ответить на приведенные ниже вопросы по конкретному приложению, чтобы принять решение о правильном дизайне и архитектуре приложения.
1. Как можно обработать объемный набор данных?
1. Вертикальная обработка против горизонтальной обработки.
2. Обработка базы данных и обработка в памяти
3. Облачное решение против монолитного решения.
2. Как будет определяться логика обработки?
1. Вся логика находится в форме кода приложения, использующего любой язык обработки, такой как Java, Kotlin, Python и т. д.
2. Определите и разделите логику обработки на более мелкие части статической логики, которая не будет подвергаться частым изменениям и может меняться очень редко, и другую часть логики, которая часто подвергается изменениям и должна быть легко поддерживаемой там, где ожидается, что она будет иметь логика должна быть обновлена в зависимости от меняющихся требований, пройти все циклы тестирования и развернута в производстве с заданными сроками SLA, чтобы уложиться в сроки, предусмотренные для изменения, и приложение должно быть гибким, поскольку оно призвано к бизнесу реагировать на изменения. с быстрым оборотом.
В условиях динамично меняющихся ситуаций, на которые влияют внешние и внутренние факторы, потребность в обработке постоянно меняется, чтобы адаптироваться и соответствовать внешним и внутренним факторам. Частые изменения требований к обработке должны быть интерпретированы бизнес-аналитиком и преобразованы в бизнес-требования для группы внедрения. Затем группа внедрения должна расшифровать и перевести бизнес-требования в техническое определение логики обработки и включить изменения в приложение. То, как будут реализованы изменения, необходимо тщательно оценить и принять решение, поскольку изменения сейчас происходят очень часто, и очень много внутренних и внешних факторов вызывают и стимулируют изменения. В условиях такой меняющейся динамики ответственность за проектирование и проектирование приложения лежит на технической команде, которая поможет спроектировать его таким образом, чтобы он помогал реагировать на любые изменения в требованиях к обработке быстрее и с минимальными нарушениями, а также проводить его через несколько уровней тестирования до тех пор, пока не будет запущено производство. более быстрые сроки в соответствии с потребностями времени.
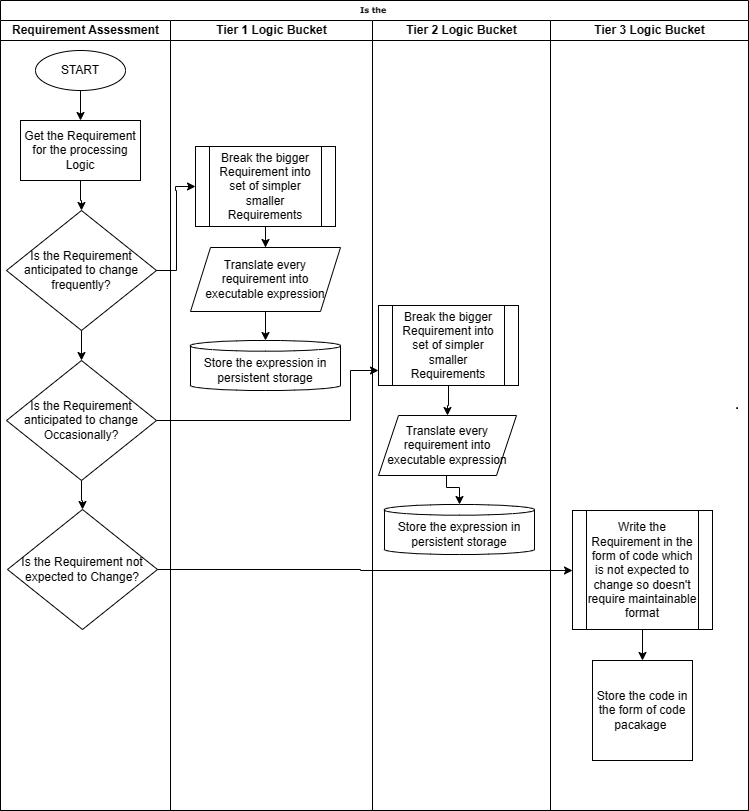
Имея этот контекст, необходимо оценить логику обработки и представить ее в удобном для сопровождения формате, чтобы ее можно было быстро изменить.
Кроме того, на этапе проектирования и анализа необходимо выполнить определение и оценку, чтобы определить, какая часть сквозной логики останется статичной, т. е. не претерпит изменений в обозримом будущем на основе прошлой исторической тенденции и потребует меньше обслуживания. Эта часть логики будет записана один раз в формате, который не очень удобен в сопровождении, возможно, в виде чистого кода, и будет установлена на более низком уровне, который вообще не будет меняться. Кроме того, какая еще часть сквозной логики будет меняться на частой и менее частой фазе? На основании результатов анализа логику необходимо разделить на отдельные уровни, как указано ниже, и соответствующим образом спроектировать и разработать. Логика, подверженная изменениям, будет размещена на более высоких уровнях и будет спроектирована и разработана в формате, который легко обслуживается и может быть изменен с минимальными усилиями и нарушением общего процесса. Ниже приведены три предложенные категории, и мы снова можем использовать другой набор категорий для любой реализации в зависимости от того, как логика обработки будет изменена для этой иллюстрации. Ниже приведено то, что предлагается, но оно может быть изменено, и ответственность за определение уровней и, соответственно, формулирование логики в соответствии с окончательным форматом для различных уровней полностью лежит на команде разработчиков:
Логика уровня 1 : Логика очень часто меняется. Мы можем назвать это горячим ведром.
Логика уровня 2 : ожидается, что логика будет время от времени меняться. Мы можем назвать это теплым ведром.
Логика уровня 3 : Никаких изменений не предполагается. Мы можем назвать это холодным ведром.
Основываясь на приведенной выше классификации сложной и запутанной логики обработки, нам необходимо разработать стратегию написания и поддержки этой логики. Различные сегменты должны быть слабо связаны, и любые изменения в логике одного сегмента не должны влиять на другие сегменты. Это поможет изолировать воздействие и свести к минимуму тестирование, а также объем работ. Поскольку логика первого уровня будет претерпевать изменения очень часто, любые изменения будут ограничиваться только компонентами, содержащими логику для корзины первого уровня. Это поможет команде внедрения сосредоточиться только на одной части всего приложения, чтобы учесть любые изменения в требованиях к обработке, а не на целом.
Кроме того, стратегии разработки логики для «горячих» сегментов верхнего уровня должны быть в форме более удобной в обслуживании структуры на основе метаданных, которая настраивается и отделена от других нижних уровней, чтобы любое изменение требований можно было быстро настроить в базовых метаданных. . Настраивая логику в структуре метаданных, группа внедрения может также спроектировать необходимые требования к управлению в форме надлежащим образом определенных проверок и контроля над метаданными, чтобы обеспечить правильную настройку и адекватную проверку логики во время ее разработки.
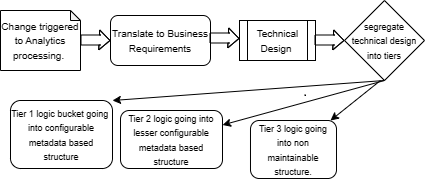
При проектировании различных уровней логики проектировщикам необходимо убедиться, что логика обработки имеет структуру, которая соответствует определению уровня и соответствует требованиям к ремонтопригодности и контролю для этой логики. Некоторые ключевые рекомендации для разных уровней изображены на диаграмме ниже и подробно объяснены для каждого уровня:
Уровень 1. Этот уровень будет содержать логику обработки, которая часто претерпевает изменения и должна быть легко поддерживаемой, а также должна обеспечивать простоту обслуживания и внесения изменений. Логика должна быть структурирована в формате, который можно легко обновлять, она должна быть легко доступна на автономной основе и обеспечивать весь контроль и проверки, предусмотренные в рамках руководящих указаний и принципов управления. Это могут быть структуры на основе метаданных, пользовательские структуры обработки, любые выражения правил с открытым исходным кодом или даже регулярные выражения. Выражения обработки можно настроить с использованием любого из форматов сериализации данных, таких как JSON, YAML, XML или любого другого подтверждающего структурированного формата, который группа реализации сочтет совместимым и согласованным с рекомендациями по созданию и управлению логикой обработки. Логику также можно сохранить во внутренней базе данных в специальной структуре и манипулировать ею непосредственно в этих структурах при любых изменениях базовых требований, управляющих логикой. Этот уровень должен очень гибко реагировать на любые изменения, а также обеспечивать быстрое внедрение логики в среду разработки нижнего уровня и проходить различные уровни среды тестирования, в конечном итоге вплоть до развертывания в рабочей среде. Все это должно соответствовать срокам SLA, определенным для реагирования на такие изменения требований.
Ключом к оптимизированному и расширяемому приложению, позволяющему учитывать любые изменения в требованиях к обработке, является гибкость, обеспечиваемая приложением, позволяющая как можно быстрее с минимальными усилиями вносить изменения в существующее приложение и развертывать его в производственной среде после прохождения всех циклов валидации и тестирования. .
Уровень 2: Этот уровень обработки будет включать в себя логику, которая время от времени претерпевает какие-либо изменения. Это будет что-то среднее между горячей логикой, которая чаще всего меняется, и холодной логикой, которая редко претерпевает изменения. Определение места между этими двумя крайностями и размещение логики в этом сегменте будет наиболее важной частью разработки общего приложения обработки и разделения логики в этом сегменте. Логика, как только она определена, должна быть помещена в структуру, которая позволит технической команде легко поддерживать любые изменения.

Уровень 3. Этот уровень статичен и редко подвергается каким-либо изменениям, поэтому логику на этом уровне рекомендуется хранить в виде кода или менее поддерживаемой структуры. Одна важная рекомендация — сохранять логику этого уровня отдельно от логики других более высоких уровней. Это будет полезно для того, чтобы изолировать масштаб воздействия любого изменения в логике обработки. Если логика более высокого уровня претерпевает частые изменения, это уменьшит влияние изменений на логику более низкого уровня, если логика на разных уровнях будет отделена и изолирована. Это поможет свести к минимуму усилия по внедрению любых изменений на любом из уровней и быстро внедрить отчет в сроки, определенные SLA. Основное внимание будет уделяться более высоким уровням для внесения изменений и их тщательному тестированию, поскольку они наиболее подвержены изменениям. Нижние уровни будут просто содержать еще одну часть общей логики обработки, которая может быть не основной логикой обработки, а любой вспомогательной логикой, необходимой для сквозной обработки.
Теперь мы можем взять вариант использования и попытаться спроектировать общее приложение сквозной обработки, а также разбить дизайн приложения в соответствии с рекомендованным выше дизайном. Давайте попробуем разработать структуру обработки прогнозной аналитики для розничного продавца электронной коммерции, чтобы помочь организации оценить текущую бизнес-модель и спрогнозировать будущие потребности в соответствии с текущей бизнес-моделью. В то же время аналитика также должна предлагать изменения в бизнес-модели, чтобы найти лучший путь вперед в нестабильные времена. Для достижения этой цели нам необходимо работать в соответствии со следующей стратегией:
1. Определите бизнес-цель, а также требования к прогнозной аналитике.
2. Получите необходимые данные для выполнения обработки.
3. Очистка, преобразование и стандартизация исходных данных перед применением прогнозного аналитического моделирования.
4. Примените модель прогнозной аналитики в соответствии с бизнес-целью для получения тщательно подобранных и кратких результатов.
5. Результаты будут переданы в аналитические приложения для создания информационных панелей и отчетов прогнозной аналитики.
После определения бизнес-цели прогнозного анализа мы начнем определять данные, необходимые для выполнения анализа, из всех необходимых разрозненных исходных систем экосистемы розничной торговли электронной коммерции.
Необходимо определить спецификацию данных и окончательно определить необходимые стратегии поиска данных. Данные будут извлечены в соответствии с окончательной стратегией и переданы в систему обработки.
Платформа обработки после получения данных выполнит необходимое преобразование данных, а также стандартизацию и очистку данных перед передачей их в реальную модель прогнозного анализа.
Преобразованные данные затем отправляются в модель прогнозного анализа для создания обобщенных, тщательно отобранных и кратких результатов для отчетов и информационной панели прогнозного анализа.
Из вышеупомянутых шагов логика уровня 1, которая, как ожидается, будет часто подвергаться изменениям, представляет собой шаг 4, описанный выше, состоящий из модели прогнозного анализа для обработки результата. Предполагается, что эта модель прогнозной аналитики будет меняться в зависимости от любых внутренних и внешних условий, влияющих на продажи и требования рынка. Модель также может претерпевать изменения в зависимости от динамических стратегий ценообразования и поведения клиентов, что может привести к обновлению моделей.
Модель должна быть легко поддерживаемой, а также расширяемой для включения любого нового шаблона и обработки. Модель также должна быть отделена от других процессов в общем приложении обработки данных.
Логика уровня 2 будет включать в себя некоторую часть этапа 3, включая этапы очистки данных, проверки качества данных, а также любые виды преобразования и стандартизации данных, необходимые перед применением прогнозных моделей. Группе внедрения необходимо оценить все эти шаги и решить, что может часто подвергаться изменениям, основываясь на опыте и вкладе бизнеса, и, соответственно, принять решение о разработке этих шагов в структурах уровня 2 или уровня 3. Основа определения уровня, на котором будет работать логика, зависит от того, как часто будет меняться базовая логика и насколько поддерживаемой должна быть логика. Рассмотрим сценарий, в котором на этапе 3 этап очистки данных представляет собой временную настройку, а проверки качества данных также не предусматривают частых изменений, но этап преобразования данных, а также стандартизация данных — это то, что может меняться с течением времени. Благодаря этой возможности мы можем разработать процесс очистки данных и проверки качества данных в соответствии с проектом уровня 1. Этап преобразования данных и стандартизация данных будут разработаны в соответствии с форматом уровня 2.
Учитывая приведенный выше вариант использования в качестве требования, предлагаемый способ проектирования и структурирования общей логики должен быть разделен и распределен по сегментам, как показано ниже.
Логика уровня 1: все шаги, требующие этапа извлечения данных, этапа очистки данных и этапа качества данных.
Логика уровня 2: часть общей логики, требующая этапа преобразования данных и этапа стандартизации данных.
Логика уровня 3. Этот уровень будет иметь логику обработки, составляющую любой этап обработки прогнозной модели, который будет включать логику обработки, которая будет применяться к выходным данным стандартизированных и преобразованных данных для создания контролируемых выходных данных. Предполагается, что этот шаг часто меняется, когда изменения будут обусловлены многими факторами, а дизайн должен быть достаточно гибким и удобным в сопровождении, чтобы любое изменение можно было применить с минимальными усилиями, а также не влиять на логику другого уровня. Это также приведет к минимальным усилиям по тестированию, которые будут ограничиваться только той частью, которая изменена. Разделение логики также имеет решающее значение для сегмента каждого уровня.
В целом интеграция сквозной обработки будет осуществляться с использованием любого инструмента планирования или оркестратора, который вызовет необходимый шаг с соответствующего уровня и передаст управление следующему шагу.
Выше приведена иллюстрация одного из подходящих вариантов использования в отрасли, позволяющего вписать его в предлагаемую структуру обработки данных. Этот подход объясняет, как различные этапы обработки в сценарии использования необходимо оценивать и распределять по разным уровням для разработки структуры обработки данных, которая является настраиваемой и управляемой метаданными. Платформа также обеспечивает гибкость, позволяющую иметь менее изменяющуюся логику в виде чистого кода, который может вызываться оркестратором. Оркестровка всех шагов будет соответствовать требованиям обработки. Платформа также предоставляет возможность масштабировать обработку за счет использования базового механизма, который будет использоваться для обработки логики. Выбираем ли мы Apache Spark, Apache Beam или любую другую среду распределенной обработки для разработки решения или используем приложение хранилища данных, такое как Snowflake. Базовое программное обеспечение предоставит функции горизонтального или вертикального масштабирования обработки в зависимости от доступной инфраструктуры. Приложение можно развернуть в собственном кластере виртуальных машин или в облаке. Базовый механизм обработки будет способен масштабироваться по горизонтали до любого уровня в зависимости от требуемой вычислительной мощности. Кроме того, конструкция обеспечивает гибкость для контейнеризации всего решения и его развертывания в любом месте. Логика обработки для уровней 3 и 2 может быть предоставлена команде внедрения с использованием упрощенного интерфейса, такого как пользовательский интерфейс или комплекс служб на основе микросервисов, чтобы обеспечить простоту настройки. При разработке логики необходимые проверки, такие как любая синтаксическая проверка конечных вычислимых выражений, а также любая функциональная проверка логики, могут быть определены и могут применяться автоматически при разработке логики. Это поможет команде внедрения сосредоточиться на определении правильной логики для типов изменений уровня 3 и уровня 2. Логика, однажды созданная и настроенная командой внедрения, может быть легко проверена и протестирована при отправке логики в платформу. Это можно сделать путем определения сервисов для синтаксической и функциональной проверки логики. Эти службы можно вызывать автоматически, пока группа реализации создает логику и передает ее в платформу.
Если мы рассмотрим общий дизайн для этого варианта использования, ниже показано, как будет выглядеть общий поток при включении этапов обработки варианта использования в предлагаемую структуру обработки данных. В приведенном ниже дизайне объясняются все этапы высокого уровня, а также то, как они будут разрабатываться и создаваться, а также уровень, на котором они будут включены. Интеграция всех этих шагов обработки снова связана с помощью оркестратора, которому будет принадлежать обработка шагов согласно порядку выполнения. Такое выполнение на основе оркестратора гарантирует, что все различные шаги не будут тесно связаны, а каждый шаг является взаимоисключающим и взаимодействует с другими шагами, используя данные, которые передаются от шага-предшественника к шагу-последующему. Все шаги будут выполнять назначенную обработку данных, полученных на предыдущем шаге, и передадут их на следующий шаг. Этот процесс будет отслеживаться на протяжении всего конвейера обработки, и к концу обработки данные пройдут обработку на всех этапах и будут переданы в нижестоящую аналитическую систему для генерации необходимых аналитических результатов для назначенных получателей. На диаграмме на высоком уровне показаны все шаги и то, как они создаются в соответствии с уровнем, к которому они относятся и будут интегрированы в общий конвейер обработки с помощью оркестратора. Наконец, обработка логики будет выполняться с использованием механизма обработки, который является самым нижним уровнем на диаграмме ниже. Механизм обработки может быть доработан архитекторами на основе потребностей обработки и топологии, которую они рекомендуют использовать. На диаграмме ниже представлены три различных варианта механизма обработки. Любой из вариантов может быть выбран на основе требований организации к обработке, бюджета и аспектов удобства обслуживания приложения обработки данных.
Процессорный механизм
В современной структуре конвейера распределенной обработки данных архитекторы и разработчики программного обеспечения имеют множество вариантов механизмов внутренней обработки. Ниже я перечисляю несколько наиболее часто используемых механизмов конвейерной обработки, которые можно рассмотреть и оценить с учетом потребностей обработки при выборе технического стека для выполнения объемной обработки данных.
В этой категории перечислены некоторые из наиболее широко используемых платформ обработки данных с открытым исходным кодом, таких как Apache Spark, Beam, Samza, Storm или Apache Flink.
Если необходимо выполнить обработку данных с использованием собственного процессора, разработанного собственными силами, команда может разработать собственную среду обработки данных с использованием технологий с открытым исходным кодом, таких как Java, Python, Kotlin и т. д. Это обеспечит полный цикл обработки данных. полный контроль над логикой обработки и отсутствие зависимости от какой-либо сторонней платформы.
Третий вариант касается сценариев, в которых необходимо выполнять обработку данных с использованием любых инфраструктур облачных хранилищ данных, таких как Snowflake, Google Cloud Big Query, Vertica, Amazon Redshift и Druid. Эти платформы очень оптимизированы по производительности, и если необходимо очень быстро обрабатывать данные с очень коротким временем обработки, в таких сценариях облачные среды хранилищ данных являются наиболее подходящим выбором для разработчиков платформ, поскольку данные не требуют должны быть перемещены в память платформы и могут сохраняться и обрабатываться непосредственно в структуре облачного хранилища данных, и это будет очень производительная система для обработки больших объемов данных с большим количеством вычислительной логики для сценариев со сложной и многоуровневой обработкой. В зависимости от необходимой вычислительной мощности платформа может масштабироваться по горизонтали до любого уровня, а также увеличиваться и уменьшаться по мере необходимости. Ее также можно настроить как динамическую модель с оплатой по факту использования, в которой узлы обработки могут создаваться при необходимости объемной обработки, а затем масштабироваться для оптимального управления стоимостью инфраструктуры.
Заключение
Предлагаемый подход предоставляет разработчикам полную гибкость при разработке общей структуры обработки данных. Ответственность за определение модели логического и прогнозного анализа будет лежать на команде внедрения . Если модель прогнозного анализа сложна и содержит много логики обработки, команде необходимо разбить ее на более мелкие, управляемые и модульные части. Ключом к эффективному проектированию является то, как разбить все требования к обработке на более мелкие самоуправляемые части, которые затем можно разделить на разные уровни в соответствии с критериями, объясненными специалистами DST Global в статье.
Каждая отдельная часть должна быть слабосвязанной и автономной, чтобы индивидуально существующие части логики, а также все части, взятые вместе, составляли модель прогнозирующей обработки. Части модели будут существовать в форме настраиваемых исполняемых выражений на основе метаданных. Выражения должны быть поддерживаемыми и настраиваемыми. Модель прогнозного анализа необходимо определить как часть структуры уровня 1, которая открыта для любых изменений и может легко, очень эффективно и плавно обновляться, не влияя на другие части общей обработки. Таким образом, решение будет отделено, а часто возникающие изменения можно будет быстро включить в общую структуру.
Технический подход DST Global, к разработке расширяемой и масштабируемой структуры обработки данных
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Когда возникает производственная проблема, начинается гонка за поиском данных, которые покажут, что пошло не так. И во многих инженерных организациях поиск данных занимает больше времени, чем понимани...
Различия и сходства между двумя наиболее влиятельными проектами с открытым исход...
От моды к здравому смыслу: почему архитектура пере...
Системы хранения данных типа «озера данных» сочета...
По мере перехода предприятий к оркестрации данных,...
Представьте, что скорость — это не только фи...
В этой статье представлен план создания масштабиру...
В этой статье разработчики компании DST Global рас...
По мере того, как предприятия ускоряют внедрение И...
Успешная аналитика медицинских данных требует комп...
Dark data — это огромные объемы неструктурир...
При оценке производительности и масштабируемости программного приложения учитывается несколько факторов. Знакомство с этими факторами может помочь разработчикам выявить узкие места, устранить неэффективность и оптимизировать свои системы для удовлетворения растущих требований:
— Проектирование программного обеспечения. Правильная разработка программного обеспечения имеет решающее значение для достижения масштабируемости и производительности. Такие методы, как модульность, развязка и разделение задач, могут помочь создать более удобные в обслуживании и масштабируемые приложения.
— Хранение и извлечение данных. Эффективная обработка данных необходима для масштабируемого программного обеспечения. Различные системы хранения, такие как реляционные базы данных, базы данных NoSQL и механизмы кэширования, могут использоваться для оптимизации операций хранения и извлечения данных.
— Сети. Задержка, пропускная способность и надежность сети существенно влияют на производительность программного обеспечения. Использование соответствующих сетевых протоколов, алгоритмов сжатия и сетей доставки контента (CDN) может помочь устранить узкие места сети и повысить производительность.
— Аппаратное обеспечение. Базовое оборудование, на котором работает программное обеспечение, включая серверы, хранилища и сетевые устройства, может ограничивать производительность и масштабируемость. Регулярные обновления оборудования и стратегии эффективного использования ресурсов могут помочь решить эти проблемы.
— Шаблоны пользователей: прогнозирование поведения пользователей и соответствующая разработка программного обеспечения могут значительно повысить производительность. Анализ пользовательских шаблонов для выявления часто используемых функций, пикового времени использования и распространенных узких мест может помочь в оптимизации программного обеспечения.
Один из ярких примеров успешного масштабирования приложений – это разработка и запуск мобильного приложения «Яндекс.Такси». Это приложение было создано в 2011 году и с тех пор стало одним из самых популярных и удобных способов вызова такси в России. Благодаря высокому качеству сервиса и удобству использования, «Яндекс.Такси» быстро завоевало доверие пользователей и стало популярным не только в России, но и за ее пределами. Сегодня это приложение предоставляет свои услуги в нескольких странах и активно развивается, привлекая все больше пользователей.
Еще одним примером успешного масштабирования приложений является разработка и запуск мессенджера «Telegram». Это приложение было создано в 2013 году и с тех пор стало одним из самых популярных и безопасных способов общения в мире. Благодаря своей простоте, надежности и высокому уровню защиты данных, «Telegram» привлек миллионы пользователей со всего мира. Команда разработчиков «Telegram» активно работает над улучшением функционала и расширением возможностей приложения, что позволяет ему успешно масштабироваться и привлекать все больше пользователей.
Еще одним примером успешного масштабирования приложений является разработка и запуск онлайн-сервиса «Delivery Club». Этот сервис был создан в 2009 году и стал одним из самых популярных способов заказа еды с доставкой. Благодаря широкой сети партнеров и удобному интерфейсу, «Delivery Club» быстро завоевал популярность среди пользователей и начал активно развиваться. Сегодня этот сервис предоставляет свои услуги во многих городах России и активно расширяется за ее пределами.
Еще одним примером успешного масштабирования приложений является разработка и запуск онлайн-платформы «Wildberries». Эта платформа была создана в 2004 году и стала одной из крупнейших интернет-магазинов в России и СНГ. Благодаря широкому ассортименту товаров, удобному интерфейсу и быстрой доставке, «Wildberries» завоевал доверие миллионов пользователей и стал популярным не только в России, но и за ее пределами. Сегодня платформа «Wildberries» успешно масштабируется и продолжает привлекать все больше клиентов, предлагая им широкий выбор товаров и удобные условия покупки.