

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Elasticsearch - масштабируемая и распределенная система поиска и аналитики

Что такое Elasticsearch?
Elasticsearch — это масштабируемая и распределенная система поиска и аналитики, построенная на основе библиотеки поиска Apache Lucene. Он предназначен для обработки больших объемов структурированных, полуструктурированных и неструктурированных данных, что делает его хорошо подходящим для широкого спектра случаев использования, включая поисковые системы, анализ журналов, электронную коммерцию и аналитику безопасности.
Elasticsearch использует распределенную архитектуру, которая позволяет хранить и обрабатывать большие объемы данных на нескольких узлах кластера. Данные индексируются и хранятся в сегментах, которые распределяются по узлам для улучшения масштабируемости и отказоустойчивости. Elasticsearch также поддерживает поиск и аналитику в реальном времени, позволяя пользователям запрашивать и анализировать данные практически в реальном времени.
Одной из ключевых особенностей Elasticsearch являются мощные возможности поиска. Он поддерживает широкий спектр поисковых запросов, включая полнотекстовый поиск, геопространственный поиск и т. д. Он также обеспечивает поддержку расширенных аналитических функций, таких как агрегирование, метрики и визуализация данных.
Elasticsearch часто используется в сочетании с другими инструментами Elastic Stack, включая Logstash для сбора и обработки данных и Kibana для визуализации и анализа данных. Вместе эти инструменты представляют собой комплексное решение для поиска и аналитики, которое можно использовать для широкого спектра приложений и вариантов использования.
Что такое Apache Lucene?
Apache Lucene — это библиотека поиска с открытым исходным кодом, предоставляющая мощные возможности текстового поиска и индексирования. Он широко используется разработчиками и организациями для создания поисковых приложений, от поисковых систем до платформ электронной коммерции.
Lucene индексирует текстовое содержимое документов и сохраняет индекс в структурированном формате, в котором можно эффективно осуществлять поиск. Индекс состоит из серии инвертированных списков, которые обеспечивают сопоставление между терминами и документами, которые их содержат. При отправке поискового запроса Lucene использует индекс для быстрого поиска документов, соответствующих запросу.
В дополнение к своим основным возможностям поиска и индексирования Lucene предоставляет ряд расширенных функций, включая поддержку нечеткого и пространственного поиска. Он также предоставляет инструменты для выделения результатов поиска и ранжирования результатов поиска по релевантности.
Lucene используется широким кругом организаций и проектов, включая Elasticsearch. Богатый набор функций, гибкость и расширяемость делают его популярным выбором для создания поисковых приложений всех видов.
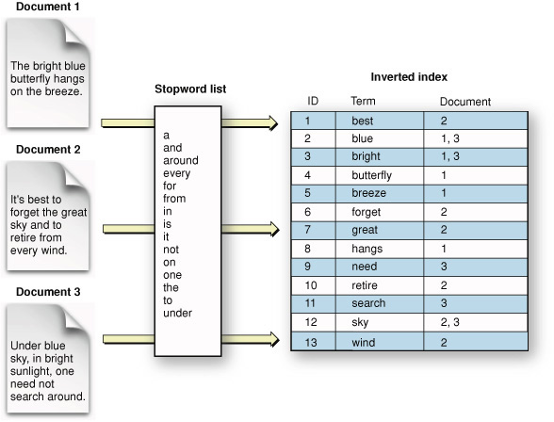
Что такое инвертированный индекс?
Инвертированный индекс Lucene — это структура данных, используемая для эффективного поиска и извлечения текстовых данных из коллекции документов. Инвертированный индекс является центральной функцией Lucene и используется для хранения терминов и связанных с ними документов, составляющих индекс.
Инвертированный индекс дает несколько преимуществ по сравнению с другими стратегиями поиска. Во-первых, он позволяет быстро и эффективно находить документы на основе условий поиска. Во-вторых, он может обрабатывать большие объемы текстовых данных, что делает его хорошо подходящим для случаев использования с большими коллекциями документов. Наконец, он поддерживает широкий спектр расширенных функций поиска, таких как нечеткое сопоставление и стемминг, которые могут повысить точность и релевантность результатов поиска.
Почему Elasticsearch?
Есть несколько причин, по которым Elasticsearch является популярным выбором для создания приложений поиска и аналитики:
Легко масштабируется (распределено): Elasticsearch изначально создан для горизонтального масштабирования. Всякий раз, когда вам нужно увеличить емкость, просто добавьте больше узлов и позвольте кластеру реорганизоваться, чтобы воспользоваться преимуществами дополнительного оборудования.
Один сервер может содержать одну или несколько частей одного или нескольких индексов, и всякий раз, когда в кластер вводятся новые узлы, они просто добавляются в группу. Каждый такой индекс или его часть называется шардом, и шарды Elasticsearch можно очень легко перемещать по кластеру.
Все на расстоянии одного вызова JSON (RESTful API): Elasticsearch управляется API. Практически любое действие можно выполнить с помощью простого RESTful API с использованием JSON через HTTP. Ответы всегда в формате JSON.
Раскрытая мощь Lucene под капотом: Elasticsearch использует Lucene внутри компании для создания своих современных возможностей распределенного поиска и аналитики. Поскольку Lucene — это стабильная, проверенная технология, в которую постоянно добавляются новые функции и лучшие практики, Lucene является базовым движком, лежащим в основе Elasticsearch.
Отличный DSL для запросов. REST API предоставляет очень сложный и функциональный DSL для запросов, который очень прост в использовании. Каждый запрос — это просто объект JSON, который может содержать практически любой тип запроса или даже несколько из них вместе взятых. Использование фильтрованных запросов, некоторые из которых выражены в виде фильтров Lucene, помогает эффективно использовать кэширование и, таким образом, ускорить общие запросы или сложные запросы с частями, которые можно использовать повторно.
Мультитенантность: несколько индексов могут храниться в одной установке Elasticsearch — узле или кластере. Приятно то, что вы можете запросить несколько индексов с помощью одного простого запроса.
Поддержка расширенных функций поиска (полнотекстовый): Elasticsearch использует Lucene под прикрытием, чтобы предоставить самые мощные возможности полнотекстового поиска, доступные в любом продукте с открытым исходным кодом. Поиск имеет многоязычную поддержку, мощный язык запросов, поддержку геолокации, контекстно-зависимые предложения, автозаполнение и фрагменты поиска.

Настраиваемые и расширяемые: многие конфигурации Elasticsearch можно изменить во время работы Elasticsearch, но для некоторых потребуется перезапуск (а в некоторых случаях и переиндексация). Большинство конфигураций также можно изменить с помощью REST API.
Ориентация на документы: храните сложные объекты реального мира в Elasticsearch в виде структурированных документов JSON. Все поля индексируются по умолчанию, и все индексы можно использовать в одном запросе для получения результатов с потрясающей скоростью.
Без схемы: Elasticsearch позволяет легко начать работу. Отправьте документ JSON, и он попытается определить структуру данных, проиндексировать данные и сделать их доступными для поиска.
Управление конфликтами. При необходимости можно использовать оптимистичный контроль версий, чтобы гарантировать, что данные никогда не будут потеряны из-за конфликтующих изменений в нескольких процессах.
Активное сообщество: сообщество, помимо создания хороших инструментов и плагинов, очень помогает и поддерживает. Общая атмосфера отличная, и это важный показатель любого проекта OSS. Есть также несколько книг, которые в настоящее время пишутся членами сообщества, и множество сообщений в блогах в сети, в которых делятся опытом и знаниями.
Архитектура Elasticsearch
Основными компонентами архитектуры Elasticsearch являются:
Узел: Узел — это экземпляр Elasticsearch, который хранит данные и предоставляет возможности поиска и индексирования. Узлы можно настроить как главный узел, узел данных или и то, и другое. Главные узлы отвечают за управление в масштабе всего кластера, а узлы данных хранят данные и выполняют операции поиска.
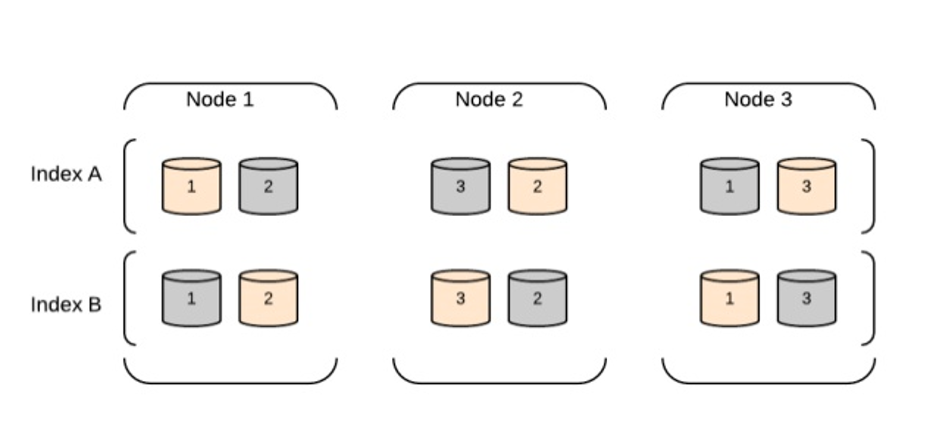
Кластер: Кластер — это группа из одного или нескольких узлов, работающих вместе для хранения и обработки данных. Кластер может содержать несколько индексов (коллекций документов) и шардов (способ распределения данных по нескольким узлам).
Индекс: Индекс — это набор документов, имеющих схожую структуру. Каждый документ представлен как объект JSON и содержит одно или несколько полей. Elasticsearch по умолчанию индексирует все поля, что упрощает поиск и анализ данных.
Осколки. Индекс можно разделить на несколько фрагментов, которые, по сути, представляют собой меньшие подмножества индекса. Шардинг позволяет параллельно обрабатывать данные и распределять их хранилище по нескольким узлам.
Реплики: Elasticsearch может создавать реплики каждого сегмента, чтобы обеспечить отказоустойчивость и высокую доступность. Реплики представляют собой копии исходного шарда и могут располагаться на разных узлах.
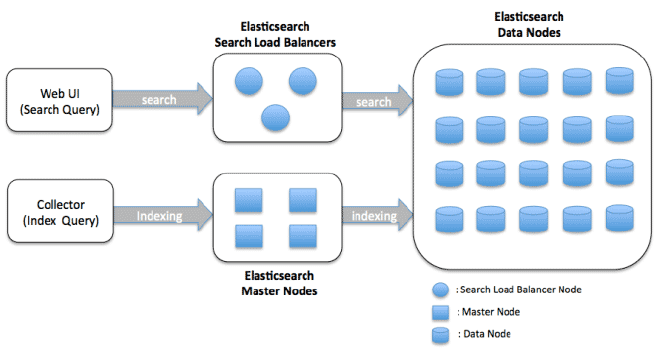
Архитектура кластера узлов данных
Узлы данных отвечают за хранение и индексирование данных, а также за выполнение операций поиска и агрегирования. Архитектура спроектирована так, чтобы быть масштабируемой и распределенной, что позволяет осуществлять горизонтальное масштабирование за счет добавления дополнительных узлов в кластер.
Вот основные компоненты кластерной архитектуры узлов данных Elasticsearch:
Узел данных. Узел — это экземпляр Elasticsearch, который хранит данные и предоставляет возможности поиска и индексирования. В кластере узлов данных каждый узел отвечает за хранение части индексных данных и выполнение поисковых запросов к этим данным.
Состояние кластера. Состояние кластера — это структура данных, содержащая информацию о кластере, включая список узлов, индексов, сегментов и их местоположений. Главный узел отвечает за поддержание состояния кластера и распространение его на все остальные узлы кластера.
Обнаружение и транспорт. Узлы в кластере Elasticsearch взаимодействуют друг с другом, используя два протокола: обнаружение и транспорт. Протокол обнаружения отвечает за обнаружение новых узлов, присоединяющихся к кластеру, или узлов, покинувших кластер. Транспортный протокол отвечает за отправку и получение данных между узлами.
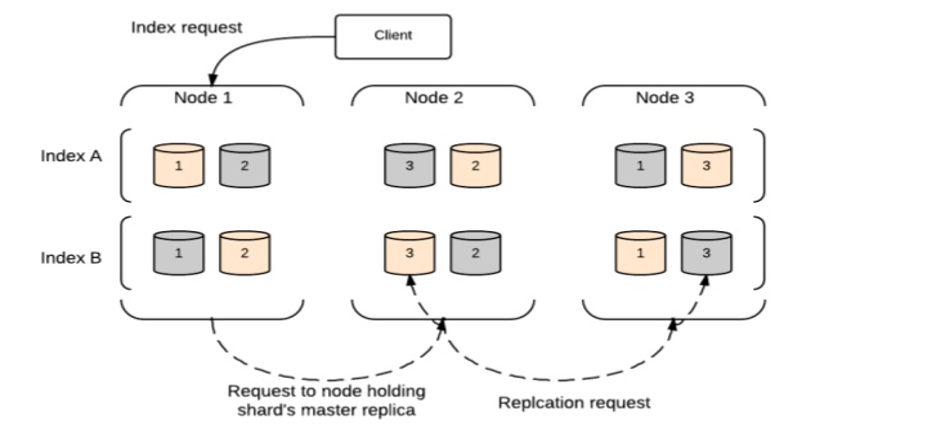
Запрос индекса
Запрос индекса выполняется в Elasticsearch, как показано ниже.
Кто использует Elasticsearch?
Несколько компаний и организаций, использующих Elasticsearch:
Netflix: Netflix использует Elasticsearch для работы своей системы поиска и рекомендаций, что позволяет пользователям быстро находить контент для просмотра.
GitHub: GitHub использует Elasticsearch для обеспечения быстрого и эффективного поиска по репозиториям кода, проблемам и запросам на включение.
Uber: Uber использует Elasticsearch для работы своей аналитической платформы в реальном времени, что позволяет им отслеживать и анализировать данные в своей службе заказа поездок в режиме реального времени.
Википедия: Википедия использует Elasticsearch для работы своей поисковой системы и предоставления пользователям быстрых и точных результатов поиска.
Elasticsearch - масштабируемая и распределенная система поиска и аналитики
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Когда возникает производственная проблема, начинается гонка за поиском данных, которые покажут, что пошло не так. И во многих инженерных организациях поиск данных занимает больше времени, чем понимани...
Различия и сходства между двумя наиболее влиятельными проектами с открытым исход...
От моды к здравому смыслу: почему архитектура пере...
Системы хранения данных типа «озера данных» сочета...
По мере перехода предприятий к оркестрации данных,...
Представьте, что скорость — это не только фи...
В этой статье представлен план создания масштабиру...
В этой статье разработчики компании DST Global рас...
По мере того, как предприятия ускоряют внедрение И...
Успешная аналитика медицинских данных требует комп...
Dark data — это огромные объемы неструктурир...
Самое первое и главное заблуждение — «нужен поиск, так бери эластик!». Но в действительности, если вам нужен шустрый поиск для небольшого или даже вполне себе крупного проекта, вам стоит разобраться в теме поподробней и вы откажетесь от использования именно этой системы.
Вторая проблема заключается в том, что пытаясь разобраться с начала, получить общую картину окажется непросто. Да инфы навалом, но последовательность в ее изучении выстраивается постфактум. Придется из книг бежать в документацию, а из документации обратно в книги, параллельно разгугливая тонкости, только чтобы понять, что такое Elasticsearch, почему он работает именно так и для чего же его вообще использовать, а где стоит выбрать что-то попроще.
Graylog — в каком-то смысле «обёртка» над Elastic.
Elastic поверх Lucene добавляет отказоустойчивость, удобный API и другие плюшки.
А вот чего такого добавляет Graylog, что для поиска он становится удобней Elastic'a?
У Graylog есть фишки заточенные под сбор логов: доставка логов, алёрты из коробки и т.д., но в плане поиска есть ли у него какие преимущества?
Для Graylog создаётся Elastic (вернее Graylog его создаёт и активно им управляет).
Плюс у Graylog своя обвязка вместо Kibana, Logstash и *beats.