В этой статье рассматривается, что такое потоковая база данных, поскольку она является основным компонентом системы потоковой обработки, и описываются некоторые доступные решения.
В этой статье разработчики компании DST Global опишут, что такое потоковая база данных, поскольку она является основным компонентом системы потоковой обработки. Мы также предоставим некоторые коммерчески доступные решения, чтобы сделать информативный выбор, если вам нужно его выбрать.
Оглавление
- Основы потоковых баз данных
- Проблемы при реализации потоковых баз данных
- Архитектура потоковых баз данных
- Примеры потоковых баз данных
Основы потоковых баз данных
Учитывая природу потоковой обработки , целью которой является управление данными как потоком, инженеры не могут полагаться на традиционные базы данных для хранения данных, и именно поэтому в этой статье мы говорим о потоковых базах данных.
Мы можем определить потоковую базу данных как хранилище данных в реальном времени для хранения, обработки и расширения потоков данных. Итак, фундаментальной характеристикой потоковых баз данных является их способность управлять данными в движении, когда события фиксируются и обрабатываются по мере их возникновения.
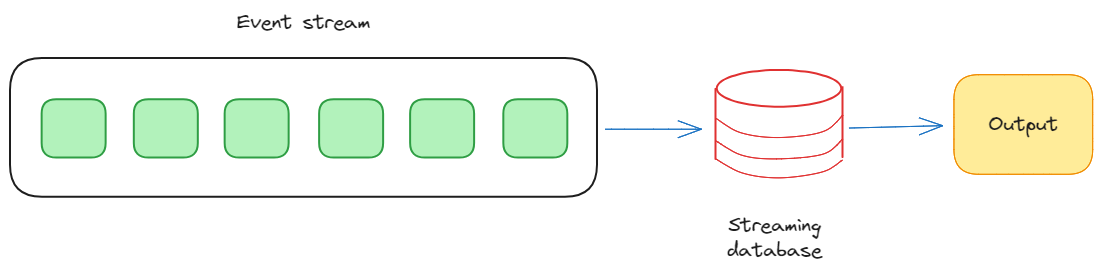
Таким образом, в отличие от традиционных баз данных, которые хранят статические наборы данных и требуют периодических обновлений для их обработки, потоковые базы данных используют модель, управляемую событиями, реагируя на данные по мере их создания. Это позволяет организациям извлекать полезную информацию из реальных данных, обеспечивая своевременное принятие решений и реагирование на динамические тенденции.
Одно из ключевых отличий потоковой передачи от традиционных баз данных заключается в их подходе ко времени. В потоковых базах данных время является критически важным измерением, поскольку данные — это не просто статические записи, а связанные с временными атрибутами.
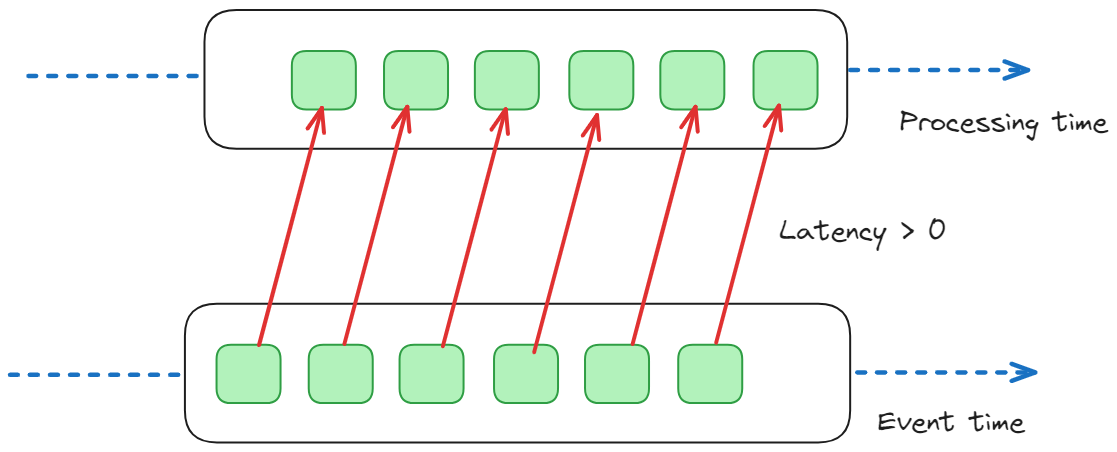
В частности, мы можем определить следующее:
- Время события: это относится к времени, когда событие или точка данных действительно произошли в реальном мире. Например, если вы обрабатываете поток данных датчиков от устройств, измеряющих температуру, временем события будет фактическое время, когда каждое измерение температуры было записано датчиками.
- Время обработки: это относится ко времени, в которое событие обрабатывается в системе обработки потока. Например, если при обработке измерений температуры после их получения возникает задержка или задержка, время обработки будет позже времени события.
Эта временная осведомленность облегчает создание агрегированных данных на основе времени, позволяя предприятиям получить правильное понимание тенденций и закономерностей на протяжении временных интервалов, а также обрабатывать события, выходящие за рамки очередности.
Фактически, события не всегда могут поступать в систему обработки в том порядке, в котором они происходили в реальном мире, по нескольким причинам, таким как задержки в сети, различные скорости обработки или другие факторы.
Таким образом, включив время события в анализ, потоковые базы данных могут изменить порядок событий в зависимости от их фактического возникновения в реальном мире. Это означает, что временные метки, связанные с каждым событием, можно использовать для выравнивания событий в правильной временной последовательности, даже если они приходят не по порядку. Это гарантирует, что аналитические вычисления и агрегирование отражают временную реальность событий, обеспечивая точное понимание тенденций и закономерностей.
Проблемы при реализации потоковых баз данных
Хотя потоковые базы данных предлагают революционный подход к обработке данных в реальном времени, их реализация может оказаться сложной задачей.
Среди прочих можно назвать следующие проблемы:
Огромный объем и скорость потоковой передачи данных
Потоки данных в реальном времени, особенно высокочастотные, распространенные в таких приложениях, как Интернет вещей и финансовые рынки, генерируют большой объем новых данных с высокой скоростью. Таким образом, потоковые базы данных должны эффективно обрабатывать непрерывный поток данных без ущерба для производительности.
Обеспечение согласованности данных в режиме реального времени
При традиционной пакетной обработке согласованность достигается за счет периодических обновлений. В потоковых базах данных обеспечение согласованности между распределенными системами в реальном времени создает сложности. Для решения этих проблем используются такие методы, как обработка времени событий, водяные знаки и идемпотентные операции, но они требуют тщательной реализации.
Проблемы безопасности и конфиденциальности
Потоковая передача данных часто содержит конфиденциальную информацию, а ее обработка в режиме реального времени требует надежных мер безопасности. Механизмы шифрования, аутентификации и авторизации должны быть интегрированы в архитектуру потоковой базы данных, чтобы защитить данные от несанкционированного доступа и потенциальных нарушений. Более того, соблюдение правил защиты данных добавляет дополнительный уровень сложности.
Инструменты и интеграция
Разнообразие источников потоковых данных и разнообразие доступных инструментов требуют продуманных стратегий интеграции. Важнейшими факторами становятся совместимость с существующими системами, простота интеграции и возможность поддержки различных форматов данных и протоколов.
Потребность в квалифицированном персонале
Поскольку потоковые базы данных по своей сути связаны с аналитикой в реальном времени , необходимо учитывать потребность в квалифицированном персонале для разработки, управления и оптимизации этих систем. Нехватка опыта в этой области может задержать повсеместное внедрение потоковых баз данных, и организациям придется инвестировать в обучение и развитие, чтобы преодолеть этот разрыв.
Архитектура потоковых баз данных
Архитектура потоковых баз данных создана для эффективной обработки тонкостей обработки потоков данных в реальном времени.
По своей сути эта архитектура воплощает принципы распределенных вычислений, обеспечивающие масштабируемость и реагирование на динамический характер потоковых данных.
Фундаментальным аспектом архитектуры потоковых баз данных является способность обрабатывать непрерывные высокоскоростные потоки данных. Это достигается за счет сочетания компонентов приема, обработки и хранения данных.
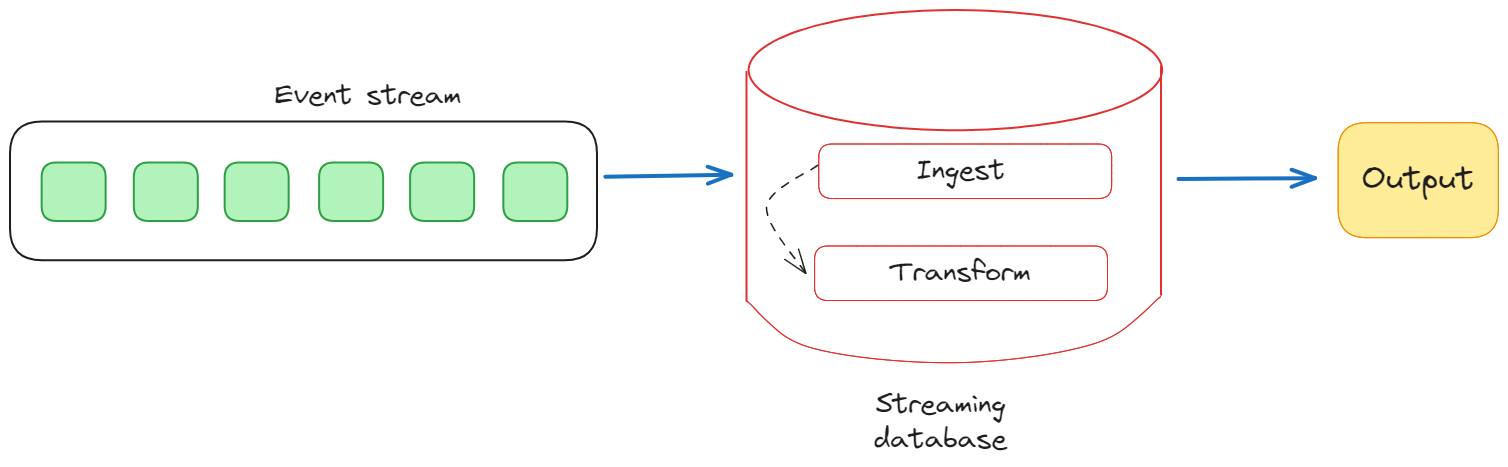
Уровень приема данных отвечает за сбор и прием данных из различных источников в режиме реального времени. Это может включать в себя коннекторы к внешним системам, очереди сообщений или прямую интеграцию API.
После приема данные обрабатываются на уровне потоковой передачи, где они анализируются, преобразуются и обогащаются практически в реальном времени. На этом уровне часто используются механизмы или платформы потоковой обработки, которые позволяют выполнять сложные вычисления над потоковыми данными, что позволяет получить значимую информацию.
Поскольку они имеют дело с данными в реальном времени, отличительной чертой потоковой архитектуры базы данных является парадигма, управляемая событиями.
Фактически каждая точка данных рассматривается как событие, и система реагирует на эти события в режиме реального времени. Эта временная осведомленность имеет основополагающее значение для агрегирования на основе времени и обработки событий, не соответствующих последовательности, что способствует детальному пониманию временной динамики данных.
Проектирование схемы в потоковых базах данных также является динамичным и гибким, что позволяет изменять структуры данных с течением времени. В отличие от традиционных баз данных с жесткими схемами, потоковые базы данных фактически учитывают изменчивую природу потоковых данных, где схема может меняться по мере введения новых полей или атрибутов: такая гибкость обеспечивает возможность обработки различных форматов данных и адаптации к меняющимся требованиям. потоковых приложений.
Пример потоковой базы данных
Теперь давайте представим пару примеров коммерчески доступных потоковых баз данных, чтобы подчеркнуть их особенности и области применения.
Восходящая волна
RisingWave — это распределенная потоковая база данных SQL, которая обеспечивает простую, эффективную и надежную потоковую обработку данных. Он потребляет потоковые данные, выполняет дополнительные вычисления при поступлении новых данных и динамически обновляет результаты.
Поскольку это распределенная база данных, RisingWave использует распараллеливание для удовлетворения требований масштабируемости. Фактически, распределяя задачи обработки по нескольким узлам или кластерам, он может эффективно обрабатывать большие объемы входящих потоков данных одновременно. Такая распределенная природа также обеспечивает отказоустойчивость и отказоустойчивость, поскольку система может продолжать бесперебойно работать даже при наличии сбоев узлов.
Кроме того, база данных RisingWave — это распределенная потоковая база данных SQL с открытым исходным кодом, предназначенная для облака. В частности, она была разработана с нуля как распределенная потоковая база данных, а не как дополнительная реализация на основе другой системы.
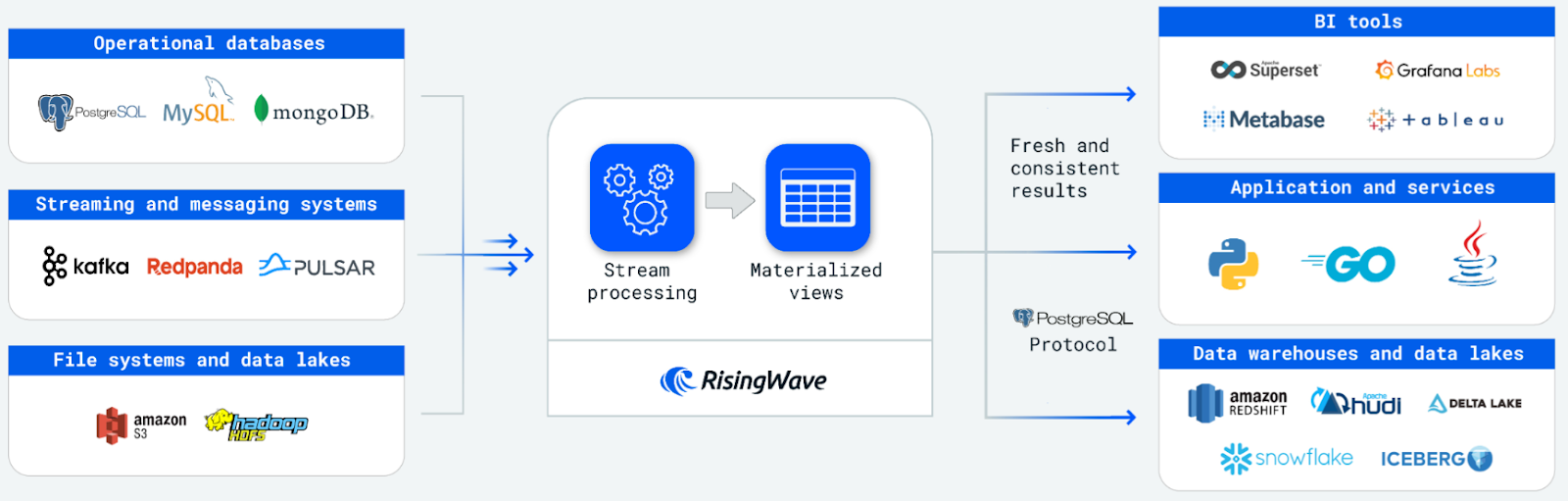
Это также снижает сложность создания приложений потоковой обработки, позволяя разработчикам выражать сложную логику потоковой обработки посредством каскадных материализованных представлений. Кроме того, это позволяет пользователям сохранять данные непосредственно внутри системы, устраняя необходимость доставки результатов во внешние базы данных для хранения и обслуживания запросов.
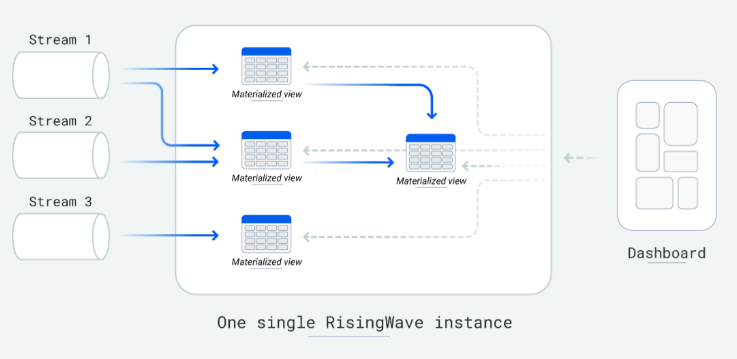
Простоту базы данных RisingWave можно описать следующим образом:
- Простота в освоении: он использует SQL в стиле PostgreSQL, что позволяет пользователям погрузиться в потоковую обработку, как если бы они это делали с базой данных PostgreSQL.
- Простота разработки: поскольку она работает как реляционная база данных, разработчики могут разложить логику потоковой обработки на более мелкие, управляемые, сложенные материализованные представления, вместо того, чтобы иметь дело с обширными вычислительными программами.
- Простота интеграции: благодаря интеграции с разнообразными облачными системами и экосистемой PostgreSQL RisingWave имеет богатую и обширную экосистему, что упрощает встраивание в существующие инфраструктуры.

Наконец, RisingWave предоставляет облако RisingWave: размещенную службу, которая дает возможность создать новый облачный кластер RisingWave и приступить к потоковой обработке за считанные минуты.
Материализовать
Materialize — это высокопроизводительное хранилище потоковых данных на базе SQL, предназначенное для поэтапной обработки данных в реальном времени с упором на простоту, эффективность и надежность. Его архитектура позволяет пользователям создавать сложные, инкрементальные преобразования данных и запросы поверх потоковых данных с минимальной задержкой.
Поскольку Materialize создан для обработки данных в реальном времени, он использует эффективные инкрементальные вычисления, чтобы обеспечить обновления и запросы с низкой задержкой. Обрабатывая только изменения данных, а не повторную обработку целых наборов данных, он может обрабатывать потоки данных с высокой пропускной способностью с оптимальной производительностью.
Materialize предназначен для горизонтального масштабирования, распределяя задачи обработки по нескольким узлам или кластерам для одновременного управления большими объемами потоков данных. Такая природа также повышает отказоустойчивость и отказоустойчивость, позволяя системе работать бесперебойно даже в случае сбоев узлов.
Будучи хранилищем потоковых данных с открытым исходным кодом , Materialize предлагает прозрачность и гибкость. Он был создан с нуля для поддержки поэтапной обработки данных в реальном времени, а не как дополнение к существующей системе.
Это значительно упрощает разработку приложений потоковой обработки, позволяя разработчикам выражать сложную логику потоковой обработки с помощью стандартных запросов SQL. Фактически разработчики могут напрямую сохранять данные внутри системы, устраняя необходимость перемещать результаты во внешние базы данных для хранения и обслуживания запросов.
Простоту Materialize можно описать следующим образом:
- Простота в освоении: он использует PostgreSQL-совместимый SQL, что позволяет разработчикам использовать свои существующие навыки работы с SQL для потоковой обработки в реальном времени без необходимости сложного обучения.
- Простота разработки: Materialize позволяет пользователям писать сложные потоковые запросы, используя знакомый синтаксис SQL. Способность системы автоматически поддерживать материализованные представления и справляться с основными сложностями потоковой обработки означает, что разработчики могут сосредоточиться на бизнес-логике, а не на тонкостях управления потоками данных, что упрощает этап разработки.
- Простота интеграции . Благодаря поддержке различных источников и приемников данных, включая Kafka и PostgreSQL, Materialize легко интегрируется в различные экосистемы, что упрощает интеграцию с существующей инфраструктурой.
Наконец, Materialize обеспечивает строгие гарантии согласованности и правильности, гарантируя точные и надежные результаты запросов даже при одновременном обновлении данных. Это делает его идеальным решением для приложений, требующих своевременного анализа и анализа в реальном времени.
Способность Materialize обеспечивать поэтапную обработку потоковых данных в режиме реального времени в сочетании с простотой использования и высокой производительностью делает ее мощным инструментом для современных приложений, управляемых данными.
Выводы
В этой статье разработчики DST Global проанализировали необходимость потоковых баз данных при обработке потоков данных, сравнив их с традиционными базами данных.
Мы также увидели, что реализация потоковой базы данных в существующих программных средах представляет проблемы, которые необходимо решить, но доступные коммерческие решения, такие как RisingWave и Materialize, позволяют их преодолеть.



