Переход от практик систем баз данных к ИИ: создание эффективных практик разработки и обслуживания с помощью генеративного ИИ.
Узнайте от специалистов компании DST Global, как искусственный интеллект может произвести революцию в разработке и обслуживании современных баз данных с помощью автоматизации, приложений искусственного интеллекта, работающих в режиме реального времени, и многого другого.
Современные методы работы с базами данных повышают производительность, масштабируемость и гибкость, обеспечивая при этом целостность, согласованность и безопасность данных. Некоторые ключевые практики включают использование распределенных баз данных для обеспечения масштабируемости и надежности, использование облачных баз данных для масштабирования и обслуживания по требованию, а также внедрение баз данных NoSQL для обработки неструктурированных данных. Кроме того, озера данных хранят огромные объемы необработанных данных для расширенной аналитики, а базы данных в памяти ускоряют извлечение данных за счет хранения данных в основной памяти. Появление искусственного интеллекта (ИИ) быстро меняет разработку и обслуживание баз данных за счет автоматизации сложных задач, повышения эффективности и обеспечения надежности системы.
В этой статье рассматривается, как ИИ может произвести революцию в разработке и обслуживании благодаря автоматизации, передовым практикам и интеграции технологий ИИ. В статье также рассматривается основа данных для приложений искусственного интеллекта в реальном времени, предлагая понимание выбора базы данных и шаблонов архитектуры для обеспечения низкой задержки, отказоустойчивости и высокой производительности систем.
Как генеративный ИИ позволяет решать задачи разработки и обслуживания баз данных
Использование генеративного искусственного интеллекта (GenAI) для разработки баз данных может значительно повысить производительность и точность за счет автоматизации ключевых задач, таких как проектирование схемы, генерация запросов и очистка данных. Он может генерировать оптимизированные структуры базы данных, помогать в написании и оптимизации сложных запросов и обеспечивать высокое качество данных с минимальным вмешательством вручную. Кроме того, ИИ может отслеживать производительность и предлагать корректировки, делая разработку и обслуживание баз данных более эффективными.
Генеративный искусственный интеллект и разработка баз данных
Давайте рассмотрим, как GenAI может помочь в некоторых ключевых задачах разработки баз данных:
- Анализ требований. Компоненты, которые требуют дополнений и модификаций для каждого запроса на изменение базы данных, документированы. Используя этот документ, GenAI может помочь выявить конфликты между требованиями к изменениям, что поможет эффективно планировать реализацию запросов на изменения в средах разработки, контроля качества и рабочей среды.
- Проектирование базы данных. GenAI может помочь разработать схему проектирования базы данных на основе лучших практик нормализации, денормализации или проектирования одной большой таблицы. Фаза проектирования имеет решающее значение, и создание надежной конструкции на основе передового опыта может предотвратить дорогостоящие изменения конструкции в будущем.
- Создание схемы и управление ею . GenAI может генерировать оптимизированные схемы баз данных на основе первоначальных требований, обеспечивая соблюдение лучших практик на основе уровней нормализации и требований к разделам и индексам, тем самым сокращая время проектирования.
- Создание пакетов, процедур и функций. GenAI может помочь оптимизировать пакеты, процедуры и функции в зависимости от объема обрабатываемых данных, идемпотентности и требований к кэшированию данных.
- Написание запросов и оптимизация . GenAI может помочь в написании и оптимизации сложных SQL-запросов, уменьшении количества ошибок и повышении скорости выполнения за счет анализа структур данных на основе стоимости доступа к данным и доступных метаданных.
- Очистка и преобразование данных. GenAI может выявлять и исправлять аномалии, обеспечивая высокое качество данных при минимальном ручном вмешательстве со стороны разработчиков баз данных.
Генеративный искусственный интеллект и обслуживание баз данных
Обслуживание базы данных для обеспечения эффективности и безопасности имеет решающее значение для роли администратора базы данных (DBA). Вот несколько способов, с помощью которых GenAI может помочь в выполнении важных задач по обслуживанию баз данных:
- Резервное копирование и восстановление. ИИ может автоматизировать графики резервного копирования, отслеживать процессы резервного копирования и прогнозировать потенциальные сбои. GenAI может генерировать сценарии для сценариев восстановления и моделировать процессы восстановления, чтобы проверить их эффективность.
- Настройка производительности. ИИ может анализировать данные о производительности запросов, предлагать варианты оптимизации и генерировать стратегии индексации на основе путей доступа и оптимизации затрат. Он также может прогнозировать проблемы с производительностью запросов на основе исторических данных и рекомендовать изменения конфигурации.
- Управление безопасностью. ИИ может выявлять уязвимости безопасности, предлагать лучшие практики для разрешений и шифрования, создавать отчеты об аудите, отслеживать необычные действия и создавать оповещения о потенциальных нарушениях безопасности.
- Мониторинг базы данных и устранение неполадок. ИИ может обеспечить мониторинг в реальном времени, обнаружение аномалий и прогнозную аналитику. Он также может генерировать подробные диагностические отчеты и рекомендовать корректирующие действия.
- Управление исправлениями и обновлениями. ИИ может рекомендовать оптимальные графики внесения исправлений, создавать отчеты об анализе воздействия исправлений и автоматизировать тестирование исправлений в изолированной среде перед их применением в рабочей среде.
Корпоративная RAG для разработки баз данных
Расширенная генерация извлечения (RAG) помогает в проектировании схемы, оптимизации запросов, моделировании данных, стратегиях индексирования, настройке производительности, методах обеспечения безопасности, а также планах резервного копирования и восстановления. RAG повышает эффективность и результативность, извлекая передовой опыт и создавая индивидуальные, контекстно-зависимые рекомендации и автоматизированные решения. Реализация RAG включает в себя:
- Создание базы знаний
- Разработка механизмов поиска
- Интеграция моделей генерации
- Создание петли обратной связи
Чтобы обеспечить эффективные, масштабируемые и обслуживаемые системы баз данных, RAG помогает избежать ошибок, рекомендуя правильную нормализацию схемы, сбалансированную индексацию, эффективное управление транзакциями и внешние конфигурации.
Трубопровод RAG
Когда пользовательский запрос или подсказка вводятся в систему RAG, она сначала интерпретирует запрос, чтобы понять, какая информация запрашивается. На основе запроса система ищет соответствующую информацию в обширной базе данных или хранилище документов. Обычно это достигается с помощью векторного внедрения, когда и запрос, и документы преобразуются в векторы в многомерном пространстве, а меры сходства используются для извлечения наиболее релевантных документов.
Полученная информация вместе с исходным запросом передается в языковую модель. Эта модель использует как входной запрос, так и контекст, предоставленный полученными документами, для создания более информированного, точного и релевантного ответа или вывода.
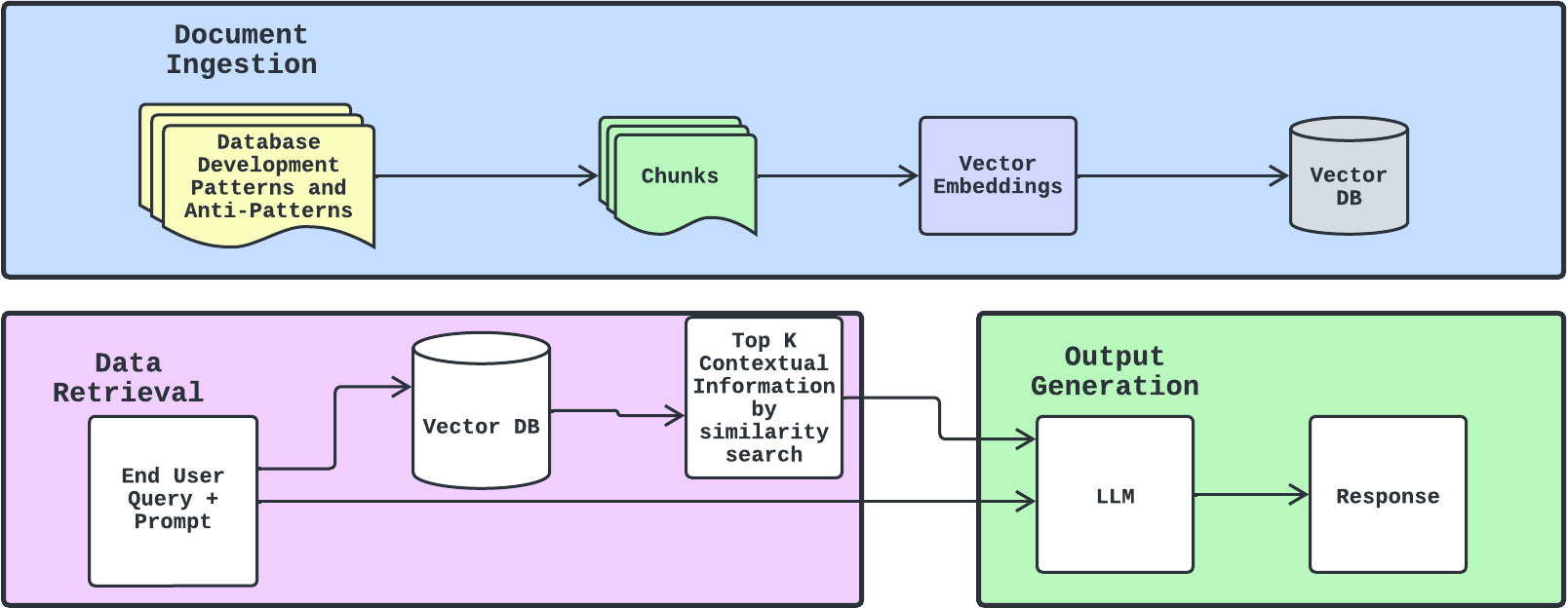
Векторные базы данных для RAG
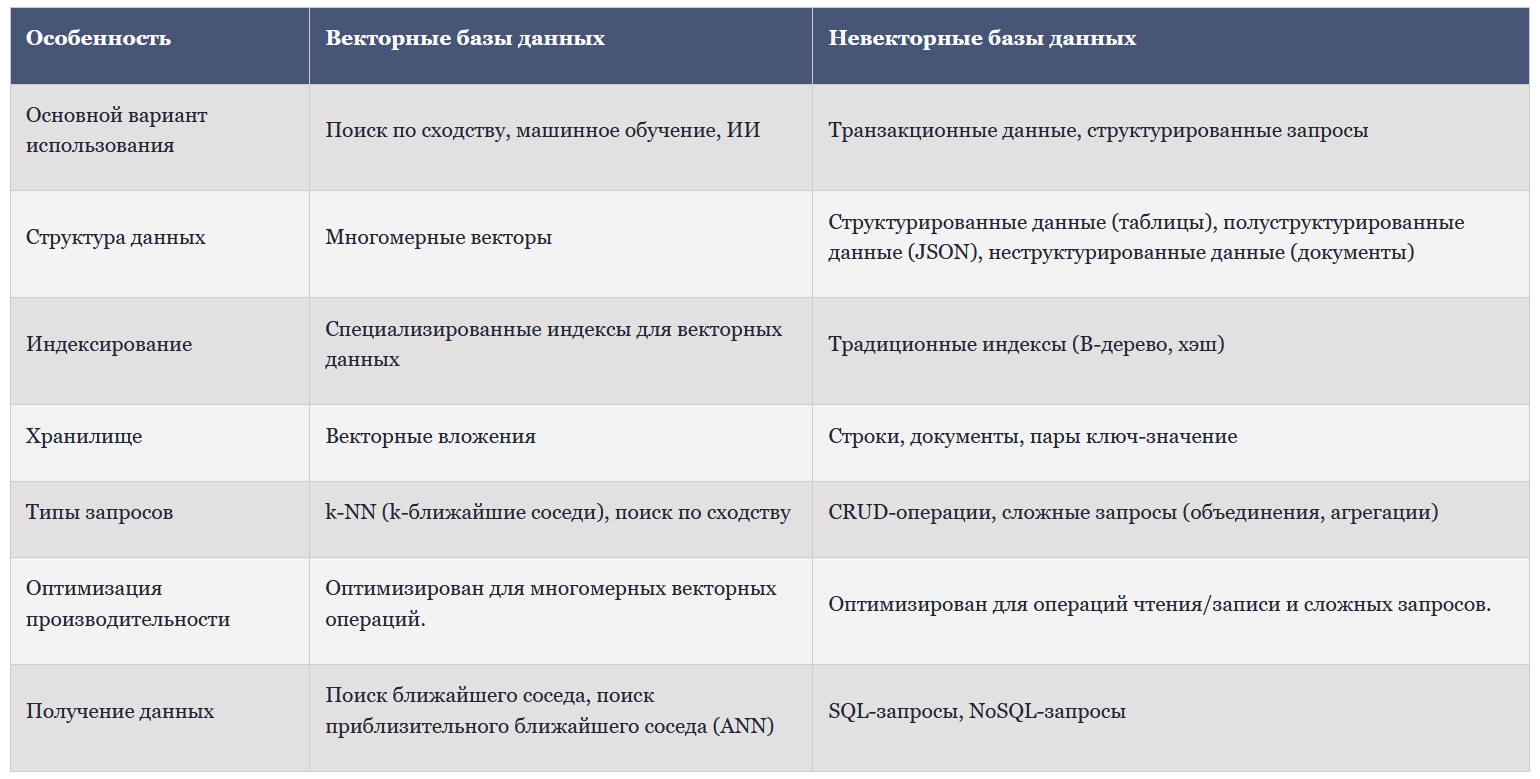
Векторные базы данных предназначены для многомерных векторных операций, что делает их идеальными для поиска по сходству в приложениях искусственного интеллекта. Однако невекторные базы данных управляют транзакционными данными и сложными запросами в структурированных, полуструктурированных и неструктурированных форматах данных. В таблице ниже показаны ключевые различия между векторными и невекторными базами данных:
При выборе базы данных векторов выбор подходящей базы данных векторов включает оценку: совместимости данных, производительности, масштабируемости, возможностей интеграции, эксплуатационных аспектов, стоимости, безопасности, функций, поддержки сообщества и стабильности поставщика.
Тщательно оценив эти аспекты, можно выбрать векторную базу данных, которая соответствует требованиям приложения и поддерживает его цели по росту и производительности.
Векторные базы данных для RAG
Для RAG обычно используются несколько векторных баз данных в отрасли, каждая из которых предлагает уникальные функции для поддержки эффективного хранения, поиска и интеграции векторов с рабочими процессами ИИ:
- Qdrant и Chroma — это мощные векторные базы данных, предназначенные для обработки многомерных векторных данных, которые необходимы для современных задач искусственного интеллекта и машинного обучения.
- Milvus , широкомасштабируемая база данных с открытым исходным кодом, поддерживает различные типы векторных индексов и используется для поиска видео/изображений и крупномасштабных рекомендательных систем.
- Faiss , библиотека для эффективного поиска по сходству, широко используется для крупномасштабного поиска по сходству и вывода ИИ благодаря своей высокой эффективности и поддержке различных методов индексации.
Эти базы данных выбираются на основе конкретных вариантов использования, требований к производительности и совместимости экосистемы.
Векторные вложения
Векторные внедрения можно создавать для различных типов контента, таких как чертежи архитектуры данных, документы баз данных, подкасты о выборе векторной базы данных и видеоролики о передовых методах работы с базами данных для использования в RAG. Единая база знаний с возможностью поиска может быть создана путем преобразования этих разнообразных форм информации в многомерные векторные представления. Это обеспечивает эффективный и контекстно-зависимый поиск соответствующей информации в различных медиаформатах, расширяя возможности предоставления точных рекомендаций, создания оптимизированных решений и поддержки комплексных процессов принятия решений при разработке и обслуживании баз данных.
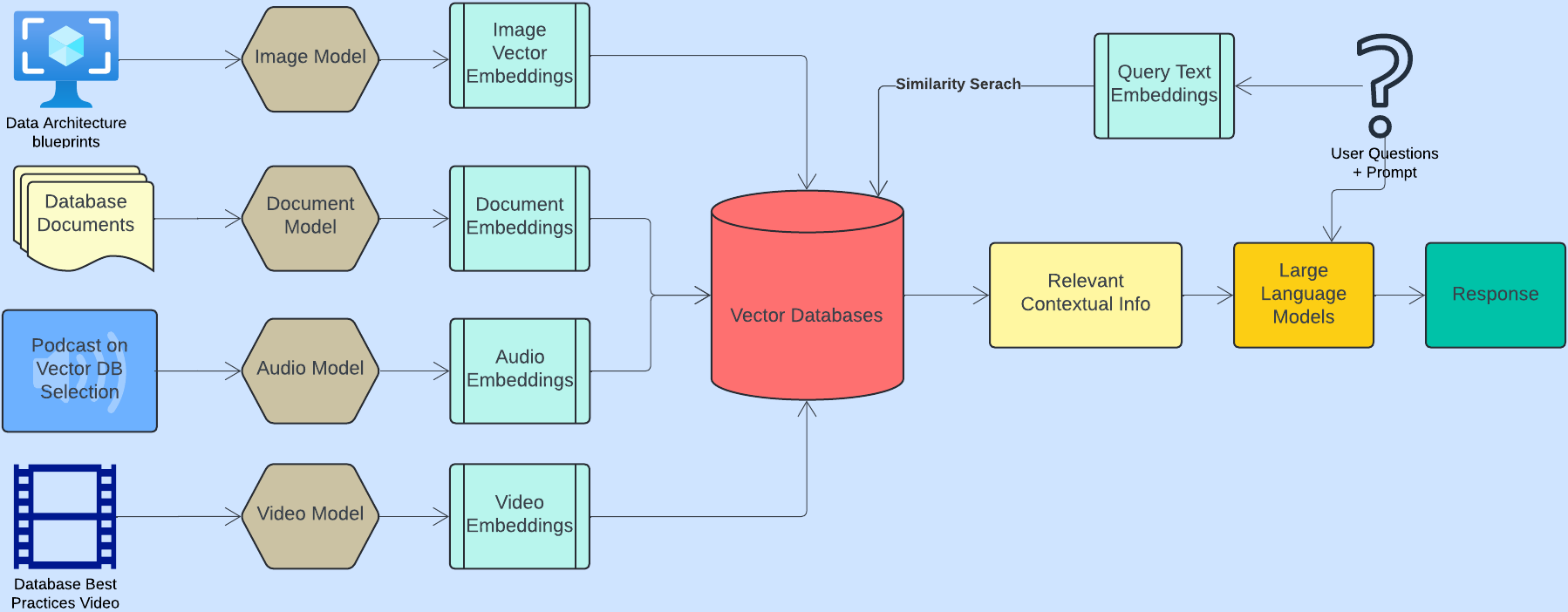
Векторный поиск и извлечение
Векторный поиск и извлечение в RAG включают преобразование различных типов данных (например, текста, изображений, аудио) в многомерные векторные представления с использованием моделей машинного обучения. Эти вложения индексируются с использованием таких методов, как иерархический навигационный малый мир (HNSW) или ANN, чтобы обеспечить эффективный поиск сходства.
При выполнении запроса он также преобразуется в векторное внедрение и сравнивается с индексированными векторами с использованием показателей расстояния, таких как косинусное сходство или евклидово расстояние, для получения наиболее релевантных данных. Эта полученная информация затем используется для расширения процесса генерации, предоставления контекста и повышения релевантности и точности сгенерированных результатов. Векторный поиск и извлечение очень эффективны для таких приложений, как семантический поиск, где запросы сопоставляются с похожим контентом, и системы рекомендаций, где предпочтения пользователя сравниваются с похожими элементами, чтобы предложить подходящие варианты. Они также используются при создании контента, где извлекается наиболее подходящая информация для повышения точности и контекста создаваемого вывода.
LLMOps для разработки баз данных на базе искусственного интеллекта
Операции с большими языковыми моделями (LLMOps) для разработки баз данных на основе искусственного интеллекта используют базовые и точно настроенные модели, эффективное оперативное управление и возможность наблюдения за моделями для оптимизации производительности и обеспечения надежности. Эти методы повышают точность и эффективность приложений ИИ, что делает их хорошо подходящими для разнообразных, специфичных для конкретной области и надежных задач разработки и обслуживания баз данных.
Базовые модели и точно настроенные модели
Использование больших предварительно обученных моделей GenAI обеспечивает прочную основу для разработки специализированных приложений благодаря их обучению на различных наборах данных. Адаптация предметной области включает дополнительную тренировку этих основополагающих моделей на данных предметной области, повышая их актуальность и точность в таких областях, как финансы и здравоохранение.
Малая языковая модель разработана для повышения вычислительной эффективности, имеет меньше параметров и меньшую архитектуру по сравнению с большими языковыми моделями (LLM). Маленькие языковые модели призваны сбалансировать производительность и использование ресурсов, что делает их идеальными для приложений с ограниченной вычислительной мощностью или памятью. Точная настройка этих небольших моделей на конкретных наборах данных повышает их производительность для конкретных задач, сохраняя при этом эффективность вычислений и обновляя их. Специальное развертывание точно настроенных моделей на небольшом языке гарантирует их эффективную работу в рамках существующей инфраструктуры и удовлетворение конкретных потребностей бизнеса.
Оперативное управление
Эффективное оперативное управление имеет решающее значение для оптимизации работы LLM. Это включает в себя использование различных типов подсказок, таких как «нулевой», «однократный», «немного» и «многократный», а также обучение настройке ответов на основе предоставленных примеров. Подсказки должны быть ясными, краткими, актуальными и конкретными для повышения качества результатов.
Передовые методы, такие как рекурсивные подсказки и явные ограничения, помогают обеспечить согласованность и точность. Такие методы, как подсказки цепочки мыслей (COT) , директивы настроений и подсказки направленного стимула (DSP), направляют модель к более тонким и контекстно-зависимым ответам.
Быстрое создание шаблонов стандартизирует подход, обеспечивая надежные и согласованные результаты для всех задач. Создание шаблонов включает в себя разработку подсказок, адаптированных к различным аналитическим задачам, а контроль версий систематически управляет обновлениями с помощью таких инструментов, как Codeberg . Постоянное тестирование и совершенствование шаблонов подсказок еще больше повышают качество и актуальность получаемых результатов.
Наблюдаемость модели
Наблюдаемость за моделями обеспечивает оптимальную работу моделей за счет мониторинга в реальном времени, обнаружения аномалий, оптимизации производительности и упреждающего обслуживания. Улучшая отладку, обеспечивая прозрачность и обеспечивая возможность постоянного улучшения, наблюдаемость моделей повышает надежность, эффективность и подотчетность систем искусственного интеллекта, снижая операционные риски и повышая доверие к приложениям, управляемым искусственным интеллектом. Он включает в себя синхронные и асинхронные методы, обеспечивающие функционирование моделей должным образом и предоставление надежных результатов.
Генеративное синхронное наблюдение с поддержкой ИИ и асинхронное наблюдение за данными с поддержкой ИИ
Использование искусственного интеллекта для синхронного и асинхронного наблюдения за данными при разработке и обслуживании баз данных расширяет возможности мониторинга в реальном времени и за прошлые периоды. Синхронное наблюдение предоставляет информацию в режиме реального времени и оповещения о показателях базы данных, позволяя немедленно обнаруживать аномалии и реагировать на них. Асинхронная наблюдаемость использует ИИ для анализа исторических данных, выявления долгосрочных тенденций и прогнозирования потенциальных проблем, что облегчает упреждающее обслуживание и глубокую диагностику. В совокупности эти подходы обеспечивают высокую производительность, надежность и эффективность операций с базами данных.
Заключение
Интеграция ИИ в разработку и обслуживание баз данных по мнению разработчиков DST Global, повышает эффективность, точность и масштабируемость за счет автоматизации задач и повышения производительности. В частности:
- Enterprise RAG, поддерживаемый векторными базами данных и LLMOps, дополнительно оптимизирует управление базами данных с помощью передовых методов.
- Наблюдаемость за данными обеспечивает комплексный мониторинг, обеспечивая упреждающее реагирование в режиме реального времени.
- Создание надежной базы данных имеет решающее значение для приложений искусственного интеллекта в реальном времени, обеспечивая эффективное удовлетворение систем потребностями в реальном времени.
- Интеграция генеративного искусственного интеллекта в архитектуру данных и выбор баз данных, построение аналитических слоев, каталогизацию данных, структуру данных и разработку сетей данных повысит автоматизацию и оптимизацию, что приведет к более эффективному и точному анализу данных.
Преимущества использования ИИ при разработке и обслуживании баз данных позволят организациям постоянно повышать производительность и надежность своих баз данных, тем самым увеличивая их ценность и позиции в отрасли.



