

Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все Ваши вопросы.
Управление данными
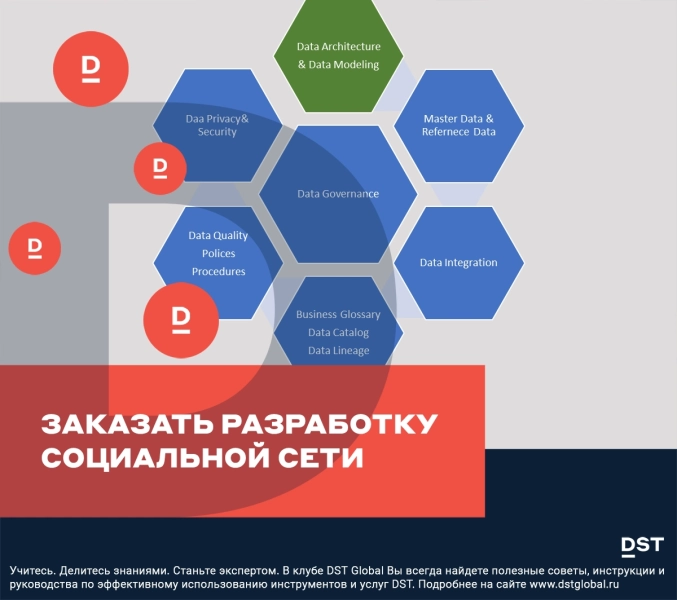
Часть 1. Конфиденциальность и безопасность данных.
Разработчики компании DST Global расскажут, как управление данными помогает организациям эффективно управлять своими данными, обеспечивая качество и безопасность для более эффективного принятия решений.
В каждой организации может существовать несколько исходных систем для различных нужд. В зависимости от размера организации число исходных систем может варьироваться от одной до более чем 1000. Организации часто централизуют свои данные в одном месте, интегрируют их и извлекают из них пользу, например, 360-градусное представление клиентов, продуктов и т. д. Для достижения этой цели необходимо создать хорошую систему управления данными.
Структура управления данными помогает организациям группировать данные соответствующим образом, управлять ими, обеспечивать качество данных, проверять согласованность и полноту данных, и все это для улучшения способности принимать решения и обеспечивать безопасность данных в удачный способ.
Ключевые принципы управления данными описаны ниже. Конфиденциальность и безопасность данных являются двумя важнейшими столпами устойчивого развития и успеха любого продукта.
Конфиденциальность и безопасность данных
Конфиденциальность и безопасность данных могут быть реализованы на уровне каждой отдельной системы. Однако при интеграции данных из разных систем необходимо реализовать соответствующую структуру безопасности. В противном случае данные могут стать объектом нарушения конфиденциальности и безопасности данных, что может нанести вред организациям. Вот графическое представление конфиденциальности и безопасности данных.
На приведенном выше рисунке отдельные системы, такие как финансовая, HR, маркетинговая и операционная, защищены индивидуально. Когда система интегрирована в централизованное хранилище данных, возникают проблемы с безопасностью.
Подходы к решению
Чтобы преодолеть эти проблемы с безопасностью в отдельных системах, существует преимущественно два способа: аутентификация (Auth) и авторизация (AuthZ).
1. Аутентификация
Аутентификация — это процесс проверки личности пользователя или процесса для входа в приложение, базу данных или любую систему.
В режимах аутентификации базы данных существует несколько способов добиться этого, но наиболее известными из них являются:
- Аутентификация по паролю (пример: аутентификация SQL Server, аутентификация базы данных Snowflake)
- Интегрированная проверка подлинности Windows
- Активный каталог (LDAP)
- SSO (аутентификация с помощью единого входа)
- Аутентификация пары ключей
- На основе сертификатов
- МИД
2. Авторизация
Авторизация — это процесс, в котором аутентифицированному пользователю разрешен доступ к различным объектам, их данным и различным операциям, которые может выполнять пользователь; например, пользователю разрешено читать только некоторый набор записей или только некоторый набор атрибутов, и пользователь может выполнять операции обновления или удаления только с некоторым набором данных.
Существует несколько типов методов авторизации данных. Шестью наиболее известными из них являются авторизация на основе ролей и авторизация на основе пользователей. В зависимости от сложности безопасности приложения также могут быть реализованы другие методы, такие как авторизация на основе атрибутов, контроль доступа на основе атрибутов, авторизация на основе контекста и авторизация на основе правил.
Ниже я кратко опишу авторизацию на основе ролей и авторизацию на основе пользователей.
Ролевая авторизация. В этом типе авторизации объекты и безопасность данных назначаются ролям, а затем роли назначаются пользователям.
Авторизация на основе пользователя. В этом типе авторизации объекты и безопасность данных будут назначены отдельным пользователям, а пользователям предоставляются права на объекты базы данных и данные.
Ключевые выводы
- Надежная система управления данными необходима, когда мы интегрируем данные из различных исходных систем.
- В рамках управления данными конфиденциальность и безопасность данных являются жизненно важными компонентами, которые необходимо учитывать.
- Конфиденциальность и безопасность данных могут быть реализованы на уровне отдельной системы; однако, когда мы переносим все исходные системные данные в централизованное расположение, возникают проблемы с безопасностью и утечкой данных.
- Аутентификация и авторизация — два основных способа укрепления структуры управления данными.
Часть 2. Архитектура данных.
Что такое архитектура данных?
Архитектура данных является фундаментальной основой организации и представляет собой схему интегрированного представления, включающего различные дисциплины управления данными, показанные на диаграмме выше.
Архитектура данных отображает общую стратегию бизнеса в форме проекта. В нем подчеркиваются требования к стратегии, такие как источники данных и различные точки данных. Архитектура данных помогает продемонстрировать, как должна происходить интеграция данных из разных наборов данных, поступающих из разных исходных систем.
Архитектура данных показывает интегрированное представление различных уровней абстракции данных, таких как необработанные данные, курируемые данные, обработанные данные и агрегированные данные для бизнес-аналитики.
Архитектура данных также объясняет, как осуществляется управление данными. Это может включать в себя способы получения, хранения, защиты, обработки, архивирования и удаления данных.
Типы архитектуры данных
Существует несколько типов архитектур данных, и подходящую модель можно выбрать на основе нескольких параметров, таких как стоимость, производительность, надежность и доступность. Наиболее известными моделями архитектуры данных, используемыми в отрасли, являются:
- Централизованная архитектура данных
- Распределенная архитектура
- Архитектура озера данных
- Архитектура Лейкхауса
- Событийно-ориентированная архитектура
- Федеративная архитектура
- Микросервисная архитектура
- Гибридная архитектура
- Архитектура фабрики данных
- Архитектура сетки данных
Мы рассмотрим три наиболее широко используемые архитектуры.
Централизованная архитектура данных
В архитектуре этого типа данные хранятся в централизованном месте, например в централизованном хранилище данных, где интегрированы все исходные системы. Отсюда доступ к данным обеспечивается в соответствии с установленными политиками и средствами контроля доступа. На рисунке ниже централизованная модель данных интегрированно заполнена данными из разных мест.
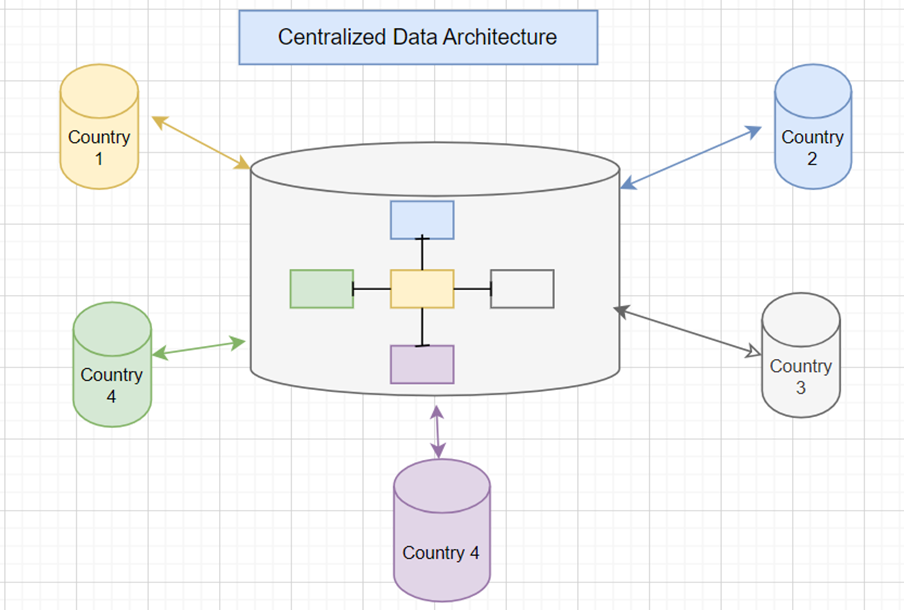
Некоторые из преимуществ использования этой архитектурной модели:
- Данные доступны в одном месте, что упрощает доступ и координацию данных.
- Этот метод будет иметь меньшую избыточность данных по сравнению с другими методами, поскольку все данные хранятся в одном месте.
- Стоимость внедрения экономична по сравнению с другими архитектурами.
- Согласованность, преобразование, безопасность и т. д. данных гораздо проще реализовать.
Некоторые из недостатков:
- Если имеется много потребителей данных, эта модель может привести к трафику данных, который может привести к проблемам с производительностью.
- Если в централизованной системе произойдет системный сбой, то это повлияет на всю систему.
- Могут существовать нормативные или специальные ограничения на обмен данными с другими местоположениями.
Распределенная архитектура
В распределенной архитектуре централизованные данные будут храниться в нескольких местах, и системы, расположенные ближе к этому месту, будут работать хорошо. Репликация данных обычно выполняется для обеспечения согласованности и точности данных в архитектуре этого типа. На рисунке ниже стандартная модель данных реплицирована в трех местах, а данные принимаются и потребляются вблизи соответствующих мест. Данные из этих трех местоположений были синхронизированы, чтобы обеспечить их доступность во всех местах.
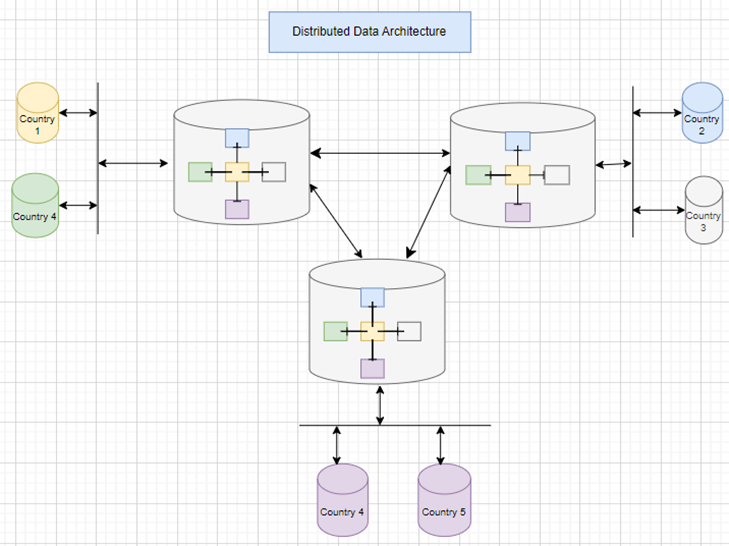
Преимущества и недостатки аналогичны модели централизованной архитектуры данных, поскольку обе эти модели в значительной степени полагаются на централизованный подход.
Некоторые из преимуществ:
- Данные доступны в одном месте, что упрощает доступ и координацию данных.
- Этот метод будет иметь меньшую избыточность данных по сравнению с другими методами, поскольку все данные хранятся в одном месте.
- Стоимость внедрения экономична по сравнению с другими архитектурами.
- Согласованность, преобразование, безопасность и т. д. данных гораздо проще реализовать.
Недостатки:
- При рассмотрении централизованной базы данных трафик данных выше.
- Если в централизованной системе произойдет системный сбой, то это повлияет на всю систему.
- Мы не можем использовать эту модель, если существуют какие-либо нормативные или конкретные ограничения на обмен данными с другими странами.
Архитектура озера данных
В архитектуре озера данных все источники данных хранятся в исходном формате необработанных данных. Эта модель обычно помогает специалистам по данным и аналитикам исследовать скрытые точки данных, а также обеспечивает гибкость при разработке различных моделей ML и аналитики. Эта архитектура обычно развертывается в службах облачного хранения, таких как S3, Azure BLOB и облачное хранилище, поддерживаемое поставщиками облачных услуг, такими как AWS, Azure, GCP и другими.
Преимущества:
- Архитектура озера данных позволяет хранить различные типы данных, такие как структурированные, полуструктурированные и неструктурированные данные.
- Эта модель позволяет хранить исходные необработанные данные для исследования данных и машинного обучения.
- Эта архитектура масштабируема и может хранить очень большой набор данных.
- Хранение данных и вычисления в этой архитектуре разделены из-за простоты масштабирования этих двух компонентов.
- Масштабируемость позволяет создать экономичную архитектуру решения.
- Эта архитектура поддерживает расширенную аналитику, например машинное обучение.
Недостатки:
- Если нет надлежащего управления, эта модель может привести к разрознению данных.
- Озера данных подвержены угрозам безопасности и конфиденциальности данных.
- Прием данных, обработка и обеспечение соблюдения схемы в этой модели сложны.
Ключевые выводы
- надежная система управления данными. При интеграции данных из различных исходных систем необходима
- Централизованная архитектура данных использует централизованное место для интеграции различных исходных систем.
- Модель распределенной архитектуры данных использует централизованный механизм в разных местах. Она отличается от модели централизованной архитектуры данных, поскольку в этой модели данные хранятся в нескольких местах.
- Модель архитектуры озера данных позволяет хранить данные в исходном необработанном формате и помогает в их исследовании.
3 часть. MDM и RDM.
Управление основными данными (MDM) — это важная дисциплина, которая помогает организациям обеспечить согласованность, точность и подотчетность своих общих активов данных.
Что такое управление основными данными (MDM)?
Управление основными данными ( MDM ) — это важная дисциплина, которая помогает организациям обеспечить согласованность, точность и подотчетность своих общих активов данных. MDM предполагает сотрудничество между ИТ-специалистами и бизнес-группами для поддержания семантической согласованности, управления и единообразия официальных основных данных предприятия. Основные данные включают в себя единообразный и согласованный набор атрибутов и идентификаторов, которые описывают критически важные объекты организации, такие как клиенты, поставщики, граждане, потенциальные клиенты, иерархии, сайты, продукты и планы счетов.
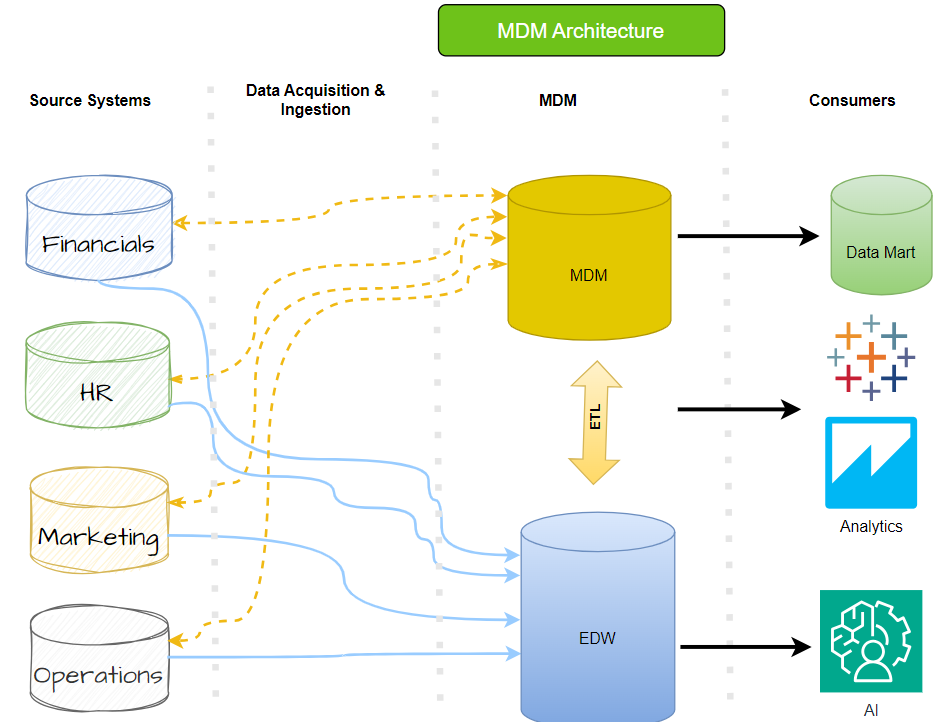
Для достижения этой цели MDM использует технологию создания единой основной записи для каждого объекта, которая пополняется, согласовывается и дедуплицируется для формирования надежного источника данных. Внедряя MDM, организации могут гарантировать точность, согласованность и надежность своих данных, что имеет решающее значение для принятия обоснованных решений и успешных бизнес-операций.
Типы стилей реализации MDM
Существует несколько типов реализации MDM, и подходящую модель можно выбрать на основе нескольких параметров, таких как стоимость, производительность, надежность и доступность.
В отрасли используются четыре наиболее известные модели архитектуры данных MDM. Они есть:
1. Стиль реестра
2. Стиль консолидации
3. Стиль сосуществования
4. Централизованный стиль
Стиль реализации MDM реестра
Модель реестра хорошо подходит для быстрого приема данных из нескольких источников. Если бизнесу требуется недорогое и быстрое решение для создания золотой записи, системы реестра могут сделать это, применив алгоритмы для очистки данных перед их сохранением на платформе MDM. Из MDM основные данные можно читать (только) или отправлять последующим пользователям данных и приложениям. Поскольку данные в источниках не обновляются из реестра MDM, системы исходных данных остаются неизменными, обеспечивая историческую запись всех нечистых данных.
Атрибуты основных данных MDM индексируются для одной записи истинности, доступной только для чтения. Он не управляет расширенным набором атрибутов данных, созданных в нескольких объединенных системах MDM.
Стиль реализации MDM консолидации
Стиль реализации Consolidation MDM — это обновленный стиль реестра с добавленным уровнем управления данными. Модели консолидации подходят для нескольких источников и используют те же процедуры конвейера данных, что и модель реестра. Несколько источников данных объединяются в центр MDM, где алгоритмы очищают данные, а сомнительные данные затем проверяются специалистами по управлению данными, которые могут внести соответствующие исправления. Таким образом, точность данных проходит через уровень человеческой мудрости, недоступный компьютерам, что приводит к большей точности данных. Повышенная точность данных помогает поддерживать высококачественную аналитику и сообщаемые функции, присутствующие в консолидированных моделях.
Стиль реализации MDM сосуществования
Начиная с консолидированной модели, стили реализации «Сосуществование MDM» встраивают в систему MDM функции обратной связи, которые обновляют исходные системы записями основных данных. В результате запись основных данных создается как в концентраторе, так и в восходящих источниках данных. Это помогает авторам сохранять самую актуальную информацию из источников. Эта конфигурация требует, чтобы источники имели функции очистки для обеспечения целостности данных.
Централизованный стиль реализации MDM
Централизованный стиль реализации MDM обеспечивает максимальный контроль над политиками безопасности, видимости и владения основными данными из концентратора MDM, не позволяя никакой другой системе корректировать запись основных данных. Авторы создают данные в хабе; стюарды просматривают сомнительные записи в центре MDM. Источников нет, есть только места назначения данных, которые подписываются на MDM для основных данных. Централизованные системы всегда являются наиболее точными во всех областях, и цена это доказывает.
Инструменты MDM
Некоторые из инструментов MDM, доступных на рынке:
- Атаккама
- Тараканы
- информатика
- Точный
- Оракул
Управление справочными данными (RDM)
Управление справочными данными (RDM) — это система, которая организует, обновляет и консолидирует справочные данные, а также управляет классификациями и иерархиями между системами и направлениями деятельности. RDM охватывает как внутренние, так и внешние данные и фокусируется на стандартизации значений и определений внутри и между системами.
Эта система имеет решающее значение для обеспечения честности и надежности бизнес-процессов, а также уменьшения количества ошибок и повышения эффективности.
Ключевые выводы
- При интеграции данных из разных исходных систем важно иметь надежную систему управления данными.
- Управление основными данными (MDM) — это жизненно важная дисциплина, которая помогает организациям обеспечить согласованность, точность и подотчетность своих общих данных.
- MDM требует сотрудничества между бизнес- и ИТ-командами для поддержания семантической согласованности, управления и единообразия официальных основных данных предприятия.
- Существует четыре типа стилей MDM, и нам следует выбрать подходящую модель на основе разных параметров.
- Управление справочными данными имеет решающее значение для обеспечения честности и надежности бизнес-процессов, а также для уменьшения количества ошибок и повышения эффективности.
4 часть. Интеграция данных.
При интеграции данных из разных исходных систем по мнению разработчиков DST Global, важно иметь надежную систему управления данными.
Создание совета или руководящего комитета по управлению данными — хороший первый шаг при интеграции программы и структуры управления данными. организацией Структура управления должна быть доведена до сведения всего персонала и руководства, чтобы все понимали происходящие изменения.
Основные понятия, необходимые для успешного управления приложениями данных и аналитики. Они есть:
- Фокус на бизнес-ценностях и целях организации.
- Соглашение о том, кто несет ответственность за данные и кто принимает решения.
- Модель, в которой особое внимание уделяется курированию и происхождению данных для управления данными.
- Прозрачный процесс принятия решений, включающий этические принципы
- Основные компоненты управления включают безопасность данных и управление рисками.
- Обеспечивать постоянное обучение с мониторингом и обратной связью по его эффективности.
- Преобразование рабочего места в культуру сотрудничества с использованием управления данными для поощрения широкого участия
Что такое интеграция данных?
Интеграция данных — это процесс объединения и гармонизации данных из нескольких источников в единый, согласованный формат, который могут использовать различные пользователи, например: в оперативных, аналитических целях и целях принятия решений.
Процесс интеграции данных состоит из четырех основных важнейших компонентов:
1. Исходные системы
Исходные системы, такие как базы данных, файловые системы, устройства Интернета вещей (IoT), медиаконтиненты и облачные хранилища данных, предоставляют необработанную информацию, которую необходимо интегрировать. Неоднородность этих исходных систем приводит к тому, что данные могут быть структурированными, полуструктурированными или неструктурированными .
- Базы данных . Централизованные или распределенные репозитории предназначены для хранения, организации и управления структурированными данными. Примеры включают системы управления реляционными базами данных (СУБД), такие как MySQL, PostgreSQL и Oracle. Данные обычно хранятся в таблицах с предопределенными схемами, что обеспечивает согласованность и простоту запросов.
- Файловые системы : Иерархические структуры, которые организуют и хранят файлы и каталоги на дисках или других носителях информации. Общие файловые системы включают NTFS (Windows), APFS (macOS) и EXT4 (Linux). Данные могут быть любого типа, включая структурированные, полуструктурированные и неструктурированные.
- Устройства Интернета вещей (IoT) : физические устройства (датчики, исполнительные механизмы и т. д.), встроенные в электронику, программное обеспечение и сетевое подключение. Устройства Интернета вещей собирают, обрабатывают и передают данные, обеспечивая мониторинг и контроль в режиме реального времени. Данные, генерируемые устройствами Интернета вещей, могут быть структурированными (например, показания датчиков), полуструктурированными (например, конфигурация устройства) или неструктурированными (например, видеоматериалы).
- Репозитории мультимедиа: платформы или системы, предназначенные для управления и хранения различных типов медиафайлов. Примеры включают системы управления контентом (CMS) и системы управления цифровыми активами (DAM). Данные в медиа-хранилищах могут включать изображения, видео, аудиофайлы и документы.
- Облачное хранилище данных: сервисы, которые обеспечивают хранение данных по требованию и управление ими в режиме онлайн. Популярные платформы облачного хранения данных включают Amazon S3, Microsoft Azure Blob Storage и Google Cloud Storage. Доступ к данным в облачном хранилище и их обработка возможны из любого места, где есть подключение к Интернету.
2. Сбор данных
Сбор данных включает извлечение и сбор информации из исходных систем.

- Пакетные процессы . Пакетные процессы обычно используются для структурированных данных. В этом методе данные накапливаются за определенный период времени и обрабатываются в больших объемах. Этот подход выгоден для больших наборов данных и обеспечивает согласованность и целостность данных.
- Интерфейс прикладного программирования (API) : API служат каналом связи между приложениями и источниками данных. Они обеспечивают контролируемый и безопасный доступ к данным. API обычно используются для интеграции со сторонними системами и обеспечения обмена данными.
- Потоковая передача . Потоковая передача предполагает непрерывный прием и обработку данных. Он обычно используется для источников данных в реальном времени, таких как сенсорные сети, каналы социальных сетей и финансовые рынки. Технологии потоковой передачи обеспечивают немедленный анализ и принятие решений на основе последних данных.
- Виртуализация . Виртуализация данных обеспечивает логическое представление данных без их физического перемещения или копирования. Он обеспечивает беспрепятственный доступ к данным из нескольких источников, независимо от их местоположения и формата. Виртуализация часто используется для интеграции данных и уменьшения разрозненности данных.
- Репликация данных. Репликация данных включает копирование данных из одной системы в другую. Это повышает доступность и избыточность данных. Репликация может быть синхронной, когда данные копируются в режиме реального времени, или асинхронной, когда данные копируются через определенные промежутки времени.
- Обмен данными. Обмен данными предполагает предоставление авторизованным пользователям или системам доступа к данным. Это облегчает сотрудничество, позволяет получать информацию с разных точек зрения и поддерживает принятие обоснованных решений. Совместное использование данных может быть реализовано с помощью различных механизмов, таких как порталы данных, озера данных и объединенные базы данных.
3. Хранение данных
После получения данных хранение данных в репозитории имеет решающее значение для эффективного доступа и управления. различные варианты хранения данных Доступны, каждый из которых адаптирован к конкретным потребностям. Эти параметры включают в себя:
- Системы управления базами данных (СУБД) : Реляционные системы управления базами данных (СУБД) — это программные системы, предназначенные для организации, хранения и извлечения данных в структурированном формате. Эти системы предлагают расширенные функции, такие как безопасность данных, целостность данных и управление транзакциями. Примеры популярных СУБД включают MySQL, Oracle и PostgreSQL. Базы данных NoSQL, такие как MongoDB и Cassandra, предназначены для хранения полуструктурированных данных и управления ими. Они обеспечивают гибкость и масштабируемость, что делает их пригодными для обработки больших объемов данных, которые, возможно, потребуется лучше вписать в реляционную модель.
- Услуги облачного хранения . Услуги облачного хранения предлагают масштабируемые и экономичные решения для хранения данных в облаке. Они обеспечивают доступ к данным по требованию из любого места, где есть подключение к Интернету. Популярные службы облачного хранения включают Amazon S3, Microsoft Azure Storage и Google Cloud Storage.
- Озера данных . Озера данных — это большие хранилища необработанных и неструктурированных данных в их собственном формате. Их часто используют для анализа больших данных и машинного обучения. Озера данных можно реализовать с помощью распределенной файловой системы Hadoop (HDFS) или облачных служб хранения.
- Дельта-озера : Дельта-озера — это тип озера данных, который поддерживает транзакции ACID и эволюцию схемы. Они предоставляют надежное и масштабируемое решение для хранения данных для рабочих нагрузок обработки и анализа данных.
- Облачное хранилище данных . Облачные хранилища данных — это облачные решения для хранения данных, предназначенные для бизнес-аналитики и аналитики. Они обеспечивают высокую производительность запросов и масштабируемость для больших объемов структурированных данных. Примеры включают Amazon Redshift, Google BigQuery и Snowflake.
- Файлы больших данных . Файлы больших данных — это большие наборы данных, хранящиеся в одном файле. Они часто используются для задач анализа и обработки данных. Распространенные форматы файлов больших данных включают Parquet, Apache Avro и Apache ORC.-
- Локальные сети хранения данных (SAN) : SAN — это выделенные высокоскоростные сети, предназначенные для хранения данных. Они предлагают высокую скорость передачи данных и обеспечивают централизованное хранилище для нескольких серверов. Сети SAN обычно используются в корпоративных средах с большими требованиями к хранению данных.
- Сетевое хранилище (NAS) : устройства NAS представляют собой системы хранения на уровне файлов, которые подключаются к сети и предоставляют общее пространство для хранения нескольким клиентам. Они часто используются в малом и среднем бизнесе и обеспечивают легкий доступ к данным с различных устройств.
Выбор правильного варианта хранения данных зависит от таких факторов, как размер данных, тип данных, требования к производительности, потребности в безопасности и соображения стоимости. Организации могут использовать комбинацию этих вариантов хранения для удовлетворения своих конкретных потребностей в управлении данными.
4. Потребление
Это заключительный этап жизненного цикла интеграции данных, на котором интегрированные данные используются различными приложениями, аналитиками данных, бизнес-аналитиками, учеными, моделями AI/ML и бизнес-процессами. Данные могут использоваться в различных формах и по различным каналам, в том числе:
- Операционные системы : интегрированные данные могут использоваться операционными системами с использованием API (интерфейсов прикладного программирования) для поддержки повседневных операций и принятия решений. Например, система управления взаимоотношениями с клиентами (CRM) может использовать данные о взаимодействии с клиентами, покупках и предпочтениях для предоставления персонализированного опыта и целевых маркетинговых кампаний.
- Аналитика: интегрированные данные могут использоваться аналитическими приложениями и инструментами для исследования данных, анализа и составления отчетов. Аналитики данных и бизнес-аналитики используют эти инструменты для выявления тенденций, закономерностей и выводов из данных, которые могут помочь в принятии бизнес-решений и стратегий.
- Обмен данными : интегрированные данные могут быть переданы внешним заинтересованным сторонам, таким как партнеры, поставщики и регулирующие органы, через платформы и механизмы обмена данными. Обмен данными позволяет организациям сотрудничать и обмениваться информацией, что может привести к улучшению процесса принятия решений и внедрению инноваций.
- Kafka — это распределенная потоковая платформа, которую можно использовать для потребления и обработки данных в реальном времени. Интегрированные данные могут передаваться в Kafka, где они могут использоваться приложениями и сервисами, которым требуются возможности обработки данных в реальном времени.
- AI/ML : интегрированные данные могут использоваться моделями AI (искусственный интеллект) и ML (машинное обучение) для обучения и вывода. Модели AI/ML используют данные для изучения закономерностей и прогнозирования, которые можно использовать для таких задач, как распознавание изображений, обработка естественного языка и обнаружение мошенничества.
Использование интегрированных данных позволяет компаниям принимать обоснованные решения, оптимизировать операции, улучшать качество обслуживания клиентов и внедрять инновации. Предоставляя унифицированное и согласованное представление данных, организации могут раскрыть весь потенциал своих активов данных и получить конкурентное преимущество.
Что такое шаблоны архитектуры интеграции данных?
В этом разделе разработчики DST Global предлагают углубится в ряд шаблонов интеграции, каждый из которых предназначен для обеспечения бесшовных интеграционных решений. Эти шаблоны действуют как структурированные структуры, облегчающие соединения и обмен данными между различными системами. В целом они делятся на три категории:
- Интеграция данных в реальном времени
- Интеграция данных практически в реальном времени
- Пакетная интеграция данных
1. Интеграция данных в реальном времени
В различных отраслях прием данных в реальном времени служит ключевым элементом. Давайте рассмотрим некоторые практические иллюстрации его применения из реальной жизни:
- В лентах социальных сетей отображаются последние публикации, тенденции и действия.
- Умные дома используют данные в реальном времени для автоматизации задач.
- Банки используют данные в реальном времени для мониторинга транзакций и инвестиций.
- Транспортные компании используют данные в режиме реального времени для оптимизации маршрутов доставки.
- Интернет-магазины используют данные в реальном времени для персонализации покупок.
Понимание механизмов и архитектур приема данных в реальном времени имеет жизненно важное значение для выбора наилучшего подхода для вашей организации.
Действительно, существует широкий выбор архитектур интеграции данных в реальном времени. Среди них наиболее часто используемые архитектуры:
- Потоковая архитектура
- Архитектура интеграции, управляемая событиями
- Лямбда Архитектура
- Каппа Архитектура
Каждая из этих архитектур предлагает свои уникальные преимущества и варианты использования, соответствующие конкретным требованиям и эксплуатационным потребностям.
а. Архитектура интеграции данных на основе потоковой передачи
В потоковой архитектуре потоки данных принимаются непрерывно по мере их поступления. Такие инструменты, как Apache Kafka, используются для сбора, обработки и распространения данных в реальном времени.
Эта архитектура идеально подходит для обработки высокоскоростных и больших объемов данных, обеспечивая при этом качество данных и низкую задержку.
Потоковая архитектура на базе Apache Kafka совершает революцию в обработке данных. Он предполагает непрерывный прием данных, что позволяет собирать, обрабатывать и распространять их в режиме реального времени. Этот подход облегчает обработку данных в реальном времени, обрабатывает большие объемы данных и отдает приоритет качеству данных и получению информации с низкой задержкой.
На диаграмме ниже показаны различные компоненты, включенные в архитектуру интеграции потоковых данных.
потоковая передача — шаблон интеграции данных
б. Архитектура интеграции, управляемая событиями
Архитектура, управляемая событиями, — это высокомасштабируемый и эффективный подход для современных приложений и микросервисов. Эта архитектура реагирует на определенные события или триггеры внутри системы, получая данные по мере возникновения событий, что позволяет системе быстро реагировать на изменения. Это позволяет эффективно обрабатывать большие объемы данных из различных источников.
в. Архитектура интеграции Lambda
Архитектура Lambda использует гибридный подход, умело сочетая преимущества пакетного приема данных и приема данных в реальном времени. Он состоит из двух параллельных конвейеров данных, каждый из которых имеет определенную цель. Пакетный уровень профессионально обрабатывает исторические данные, а уровень скорости быстро обрабатывает данные в реальном времени. Такой архитектурный дизайн обеспечивает получение аналитической информации с малой задержкой, обеспечивая точность и согласованность данных даже в обширных распределенных системах.
д. Архитектура интеграции данных Kappa
Архитектура Kappa — это упрощенный вариант архитектуры Lambda, специально разработанный для обработки данных в реальном времени. Он использует механизм обработки одиночного потока, такой как Apache Flink или Apache Kafka Streams, для управления как историческими данными, так и данными в реальном времени, оптимизируя конвейер приема данных. Такой подход сводит к минимуму сложность и затраты на обслуживание, одновременно обеспечивая быстрое и точное понимание.
2. Интеграция данных практически в реальном времени
При интеграции данных практически в реальном времени данные обрабатываются и становятся доступными вскоре после их создания, что крайне важно для приложений, требующих своевременного обновления данных. Для интеграции данных практически в реальном времени используется несколько шаблонов, некоторые из них выделены ниже:
а. Сбор измененных данных — интеграция данных
Система отслеживания измененных данных ( CDC ) — это метод регистрации изменений, происходящих в данных исходной системы, и распространения этих изменений в целевую систему.
б. Репликация данных — Архитектура интеграции данных
Благодаря архитектуре интеграции репликации данных две базы данных могут легко и эффективно реплицировать данные в соответствии с конкретными требованиями. Эта архитектура гарантирует, что целевая база данных остается синхронизированной с исходной базой данных, обеспечивая обе системы актуальными и согласованными данными. В результате процесс репликации становится плавным, что обеспечивает эффективную передачу данных и синхронизацию между двумя базами данных.
в. Виртуализация данных — архитектура интеграции данных
В виртуализации данных виртуальный уровень объединяет разрозненные источники данных в единое представление. Он исключает репликацию данных, динамически направляет запросы к исходным системам на основе таких факторов, как локальность данных и производительность, а также обеспечивает унифицированный уровень метаданных. Виртуальный уровень упрощает управление данными, повышает производительность запросов и облегчает управление данными и сценарии расширенной интеграции. Это дает организациям возможность эффективно использовать свои информационные активы и полностью раскрыть их потенциал.
3. Пакетный процесс: интеграция данных
Пакетная интеграция данных включает в себя консолидацию и передачу набора сообщений или записей в пакетном режиме для минимизации сетевого трафика и накладных расходов. Пакетная обработка собирает данные за определенный период времени, а затем обрабатывает их пакетно. Этот подход особенно полезен при обработке больших объемов данных или когда обработка требует значительных ресурсов. Кроме того, этот шаблон позволяет выполнять репликацию основных данных в хранилище реплик для аналитических целей. Преимуществом этого процесса является передача уточненных результатов. Традиционные шаблоны интеграции данных пакетного процесса:
Традиционная архитектура ETL — архитектура интеграции данных
Этот архитектурный проект соответствует традиционному процессу извлечения, преобразования и загрузки (ETL). В этой архитектуре есть несколько компонентов:
- Извлечение: данные получены из различных исходных систем.
- Преобразование: данные подвергаются процессу преобразования для преобразования их в желаемый формат.
- Загрузка: преобразованные данные затем загружаются в назначенную целевую систему, например хранилище данных.
Инкрементная пакетная обработка — архитектура интеграции данных
Эта архитектура оптимизирует обработку, концентрируясь только на новых или измененных данных из предыдущего пакетного цикла. Такой подход повышает эффективность по сравнению с полной пакетной обработкой и снижает нагрузку на ресурсы системы.
Микропакетная обработка — архитектура интеграции данных
При микропакетной обработке небольшие пакеты данных обрабатываются через регулярные и частые интервалы. Он обеспечивает баланс между традиционной пакетной обработкой и обработкой в реальном времени. Этот подход значительно снижает задержку по сравнению с традиционными методами пакетной обработки, обеспечивая заметное преимущество.
Пакетная обработка Pationed — архитектура интеграции данных
В этом подходе к секционированной пакетной обработке объемные наборы данных стратегически делятся на более мелкие, управляемые разделы. Эти разделы затем можно эффективно обрабатывать независимо друг от друга, часто используя возможности параллелизма. Эта методология предлагает неоспоримое преимущество за счет значительного сокращения времени обработки, что делает ее привлекательным выбором для обработки крупномасштабных данных.
Ключевые выводы
- При интеграции данных из разных исходных систем важно иметь надежную систему управления данными.
- Шаблоны интеграции данных следует выбирать на основе вариантов использования, таких как объем, скорость и достоверность.
- Существует 3 типа стилей интеграции данных, и нам следует выбрать подходящую модель на основе различных параметров.
Управление данными
Напишите нам прямо сейчас, наши специалисты расскажут об услугах и ответят на все ваши вопросы.
Комментарии пользователей
и отзывы экспертов
и отзывы экспертов
Вам может быть интересно
Когда возникает производственная проблема, начинается гонка за поиском данных, которые покажут, что пошло не так. И во многих инженерных организациях поиск данных занимает больше времени, чем понимани...
Различия и сходства между двумя наиболее влиятельными проектами с открытым исход...
От моды к здравому смыслу: почему архитектура пере...
Системы хранения данных типа «озера данных» сочета...
По мере перехода предприятий к оркестрации данных,...
Представьте, что скорость — это не только фи...
В этой статье представлен план создания масштабиру...
В этой статье разработчики компании DST Global рас...
По мере того, как предприятия ускоряют внедрение И...
Успешная аналитика медицинских данных требует комп...
Dark data — это огромные объемы неструктурир...
Единственное что разные места создают не удобство и постоянный контроль множества точек входа
Размерности качества данных служат опорной точкой для создания правил обеспечения качества данных, метрик, моделей данных и стандартов, которые должны соблюдать все сотрудники с момента, когда они вводят запись в систему или извлекают массив данных из сторонних источников.
Текущий мониторинг, интерпретация и улучшение данных — ещё одно неотъемлемое требование, способное превратить реактивное управление качеством данных в проактивное. Так как всё движется по замкнутому кругу, пусть это будет круг высококачественных и ценных данных.